




 本文探讨了一种针对小样本学习任务的改进方法,通过结合词嵌入和自适应margin loss,如CRAML和TRAML,使得相似类别间的区分更加有效。研究者提出了一种新的AdaptiveMarginLoss,适用于标准FSL和generalized FSL场景,提升了特征提取的区分度。
本文探讨了一种针对小样本学习任务的改进方法,通过结合词嵌入和自适应margin loss,如CRAML和TRAML,使得相似类别间的区分更加有效。研究者提出了一种新的AdaptiveMarginLoss,适用于标准FSL和generalized FSL场景,提升了特征提取的区分度。
Background & Motivation
各种度量学习方法的不同之处就在于特征的提取方法和嵌入空间内距离的度量方法不同。
交叉熵损失常用来监督模型提取区别度高的视觉特征,在此之前还有人提出各种不同的 margin loss。最简单的 Naive Additive Margin Loss:
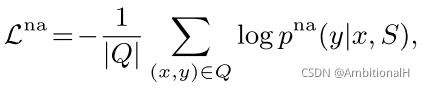
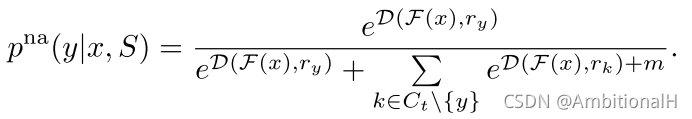
这个方法是假设所有的类都应该平等的远离彼此,因此增加了一个固定的常数 m。但是对相似的类别并不能很好地区分,尤其是在小样本的设定下。
除此之外还有 angular margin 和 cosine margin 等等。
By observing that the weights from the last fully connected layer of a classification DCNN trained on the softmax loss bear conceptual similarities with the centers of each class.
没读太懂。
但是之前的 margin loss 并不适合小样本学习任务这种数据很稀缺的情况,这也是本文的 Motivation。
Methodology
第一次看到 standard FSL 和 genrealized FSL 这两种说法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









