- 博客(140)
- 资源 (1)
- 收藏
- 关注
 RSS订阅
RSS订阅原创 安装Flume和Kafka
上一章获取到了排行的视频信息,并且每小时更新一次,那么这里使用flume监控文件并配置到kafka中。自用启动代码::cd soft/kafka_2.12-2.7.0/bin/启动zookeeper: ./zookeeper-server-start.sh ../config/zookeeper.properties 启动kafka: ./kafka-server-start.sh ../config/server.properties flume链接kafka: /root/
2022-03-16 18:33:31
 1991
1991
转载 hexo博客部署到腾讯云服务器
云服务器我直接买最低配置,镜像选的Centos8.2,因为我搭建的Spark集群都是基于Centos的比较熟悉,直接选择 付款 开机 ssh连 挺方便的,和本地虚拟机没啥区别。配置nginxnginx是一款轻量级的Web服务器/反向代理服务器以及电子邮件代理服务器,在BSD-like 协议下发行。其特点是占有内存少,并发能力强,nginx的并发能力在同类型的网页服
2022-03-05 18:20:16
722
原创 Mysql
首先回答一个问题:为什么要使用数据库?我们在实际应用中需要将数据持久化,以便我们不丢失数据,所以数据库提供了数据持久化的功能。但是数据的存储文件系统也能做,相比而言数据库对数据的组织和管理更为重要,可以选择查询我们想要的数据,并且兼顾性能、速度、数据管理方式、容灾、备份等多因素。对于我们,数据库是一种工具,帮助我们科学合理组织数据,快速存取。概念DataBase 数据库:存储数据表。DataBase Management System 数据库管理系统:用于建立管理数据库,通过它来访问数据库的数据表。
2021-12-05 09:55:56
706
原创 SQL基础知识
分为增删改查和面试题增创建数据库:create database 数据库名称create database taobao;创建表:create table 表名(列 格式 null设置,·····),主键设置:primary key (主键列)CREATE TABLE ProductIns(product_id char(4) NOT NULL,product_name VARCHAR(100) NOT NULL,product_type VARCHAR(32) NOT NULL,sal
2021-03-10 20:00:31
605
原创 二叉树遍历
校招实现对算法一般不会太偏太难先把基础练扎实二叉树的遍历今天整理二叉树的遍历不外乎三种遍历方式 前序 中序 后序 还有一个层次遍历实现方式两种 递归实现和非递归实现二叉树的前序遍历class Solution { public List<Integer> preorderTraversal(TreeNode root) { List<Integer> res = new ArrayList<>(); preorder
2021-03-09 21:20:10
157
原创 每日一题@79区域和检索 - 数组不可变
给定一个整数数组 nums,求出数组从索引 i 到 j(i ≤ j)范围内元素的总和,包含 i、j 两点。实现 NumArray 类:NumArray(int[] nums) 使用数组 nums 初始化对象int sumRange(int i, int j) 返回数组 nums 从索引 i 到 j(i ≤ j)范围内元素的总和,包含 i、j 两点(也就是 sum(nums[i], nums[i + 1], ... , nums[j])) 示例:输入:["NumArray", "sum
2021-03-04 21:11:19
256
 1
1
原创 每日一题@78单词搜索
经典回溯法给定一个二维网格和一个单词,找出该单词是否存在于网格中。单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。示例:board =[ ['A','B','C','E'], ['S','F','C','S'], ['A','D','E','E']]给定 word = "ABCCED", 返回 true给定 word = "SEE", 返回 true给定 word = "ABCB"
2021-03-03 21:30:27
178
1
原创 看书Apache Spark 1
看书Apache Spark 1大数据处理框架Apache Spark设计与实现第一章 大数据处理框架概览1.大数据带来的挑战 数据量大 数据类型多样 产生处理速度快 价值密度低 的4V特性传统处理系统难以在可接受的时间内对数据进行高效处理2.大数据处理框架 2004年Google提出基于分治归并和函数式编程思想的MapReduce分布式计算框架。2007年微软提出Dryad分布式计算框架,它允许用户将任务组织成有向无环图DAG。2012年AMPLab提出基于内存适合于迭代计算的Spa
2021-03-01 13:11:12
120
原创 Linux命令
Linux相关1.当前目录 ./ 切换目录 cd2.查看当前进程 ps 执行退出 exit 查看当前路径pwd3.清屏 clear 退出当前命名 ctrl+c 执行睡眠ctrl+z4.查看当前作业jobs 列出进程的PID和作业号jobs -l5.软链接 ln -s slink source 相当于快捷方式 硬链接ln link source 相当于copy一份不可跨区6.创建目录mkdir 创建文件touch / vi 文件权限修改chmod7.查看文件内容的命令:vi 编辑方式查
2021-02-28 21:01:58
187
原创 每日一题@77不同路径 II
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]输出:2解释:3x3 网格的正中间有一个障碍物。从左上角到右下角一共有 2 条不同的路径:1. 向右 -> 向右 -> 向下 -> 向
2021-02-28 17:57:49
272
1
原创 大数据电信客服3
大数据电信客服3B站链接数据分析部分数据分析先把视频看完了使用MapReduce项目一直缺少依赖然后就用Spark自己写注意他妈的Hbase2.0把hbase-mapreduce模块单独拿出来需要添加一下依赖才能运行 <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</arti
2021-02-24 14:05:59
299
原创 大数据电信客服2
大数据电信客服2B站链接介绍完整的安装运行项目配置我的机器安装Hadoop3.2.1和Spark3.0 导致Hbase和Kafka版本都很高 所以视频里面有的配置文件需要修改这是所有软件版本 上传到百度云正在上传 传完发链接我配置了6台虚拟机node1-6链接:https://pan.baidu.com/s/1gRWeVCGfQHDY6YucNSjzlw提取码:1212复制这段内容后打开百度网盘手机App,操作更方便哦Hadoop安装使用这个文档安装完全没碰到问题https:
2021-02-23 10:09:24
753
原创 大数据电信客服
大数据电信客服项目B站链接项目背景通信运营商产生大量通信数据,例如童话记录,短信等我们的需求是统计每天每月以及每年每个人的通话次数及时长。项目架构CallLog 通话日志 —> Flume日志收集 —> Kafka消息处理 —>HBase数据存储MR统计分析—>YARN调度—>Mysql存储 —>WebServer前端生产数据ProduceLog ---------->Flume -------------------->Kafka消息
2021-02-20 11:53:57
1576
2
原创 Spark核心源码分析2
大数据科学丛书Spark核心源码分析与开发实战第4章 Spark的运行模式1.运行模式概览standalone模式,即独立模式,通过它可以独立部署Spark集群,比如当我们只需要借助Spark进行大数据计算时,此模式是最佳模式。但当我们需要多种计算框架比如MR时,就需要引入外部资源管理系统YARN和Mesos对资源进行调度。Spark一开始就支持Mesos,yarn资源Container是不可动态伸缩的,一旦启动就不可变。术语:Application:用户构建的Spark应用程序,包括驱动程
2021-02-19 16:35:55
255
1
原创 Spark核心源码分析1
大数据科学丛书Spark核心源码分析与开发实战第一章 Spark系统概述1.Spark是什么是一个快速和通用的大数据处理引擎。可以通俗的理解为一个分布式的大数据处理框架,它基于RDD,立足于,内存计算,在one stack to rule them all思想引领下,打造的一个可以进行流式处理,机器学习,即时查询,图计算等各种大数据处理无缝连接的一栈式计算平台。Spark优势:快速处理:比Hadoop快的原因,内存计算减少磁盘io,Hadoop按部就班进行计算,Spark有方向性的,有向无环
2021-02-11 11:53:46
178
原创 深入之Java虚拟机1
深入理解Java虚拟机第二版第一章 JavaJava发展史虚拟机 实战编译自己的虚拟机第二章 Java内存区域与内存溢出异常1.运行时数据区域包括一下几个:程序计数器:一块较小的内存空间,它可以看作当前线程所执行字节码的行号指示器。分支跳转循环异常都是依赖这个计数器完成。每个线程都需要一个独立的程序计数器,各线程之间互不影响,独立存储,为线程私有内存。Java虚拟机栈:线程私有的,生命周期与线程相同。描述为Java方法执行的内存模型:每个方法执行的同时会创建一个栈帧用于存储局部变量表、操作
2021-02-07 16:16:31
143
原创 每日一题@76最后一个单词
最后一个单词的长度给你一个字符串 s,由若干单词组成,单词之间用空格隔开。返回字符串中最后一个单词的长度。如果不存在最后一个单词,请返回 0 。单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。示例 1:输入:s = "Hello World"输出:5示例 2:输入:s = " "输出:0首先想着遍历字符串,使用charAt函数,等于空格就设置count为0,不是则+1,最后返回count public int lengthOfLastWord(String s) {
2021-02-05 22:14:08
720
原创 看书Java8
对java程序员笔试解析 整理(8) 数据结构与算法第六章 数据结构与算法1.线性表线性表的顺序存储指用一组地址连续的单元依次存储线性表的数据元素线性表的链式存储在计算机任意存储单元存储元素,不要求物理连续,失去了顺序表的随机存取优点。特点:存储密度小,物理上不需要相邻、插入删除快、查找比顺序表慢、每个节点由数据域和指针组成。2.链表时物理存储单元上非联系非顺序的存储结构,数据单元的逻辑顺序是通过链表中的指针链接次序实现的。链表的查找是从头节点开始,依次访问时间复杂度为O(n)。如何查找单
2021-02-05 21:26:13
143
2
原创 Java看书7
对java程序员笔试解析 整理(7)第四章 网络与通信1.OSI网络模型从逻辑上可分为七层模型,由下至上分别为物理层、数据链路层、网络层、传输层、会话层、表示层和应用层应用层:也称为应用实体,一般指的是应用程序,常见的应用层协议有FTP、HTTP等表示层:负责数据的编码以及转化,确保应用层正常工作会话层:主要负责网络中两个结点之间的建立、维护、控制会话以及提供单工、半双工、和全双工三种通信模式的服务。NFS、RPC和X Windows都在该层工作传输层:最重要的一层,负责分割组合数据实现端
2021-02-05 20:48:46
205
原创 Java看书6
对java程序员笔试解析 整理(6)第三章 数据库1.数据库中的事务指什么事务时数据库中一个单独的执行单元,在数据库中更改数据成功时,在食物中更改的数据便会提交,不在改变,否则事务就会取消或者回滚。事务必须满足四个属性:原子性、一致性、隔离性和持久性即ACID原子性:事务是一个不可分割的整体,即当修改数据时,要么全部执行要么不执行,不允许事务部分完成引起错误。一致性:一个事务在执行前和执行后数据库数据必须保持一致性状态。例如银行转账,转帐前和转账后两个账户的金额之和应该保持不变。数据库的一致
2021-02-05 11:56:01
129
原创 Java看书5
对java程序员笔试解析 整理(5)第二章 设计模式常用的设计模式有工厂模式、单例模式、适配器模式、享元模式以及观察者模式。工厂模式:主要解决:主要解决接口选择的问题。何时使用:我们明确地计划不同条件下创建不同实例时。如何解决:让其子类实现工厂接口,返回的也是一个抽象的产品。关键代码:创建过程在其子类执行。应用实例: 1、您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。 2、Hibernate 换数据库只需换方言和驱动就可以。优点:
2021-02-04 18:15:34
154
原创 Java看书4
对java程序员笔试解析 整理(4) 多线程40.实现多线程的三种方法实现Run able接口,并实现接口中的run方法。步骤自定义类并实现Runable接口实现run方法;创建Thread对象,用实现Runable接口的对象作为参数实例化Thread对象;调用Thread对象的start()方法。class MyThread implements Runable{ public void run(){ System.out.println("Thread body");
2021-02-04 16:26:39
124
原创 Java看书3
对java程序员笔试解析 整理(3)28.容器List:实现ArrayList 无序可重复Vector 无序可重复LinkedList 无序可重复Set:实现HashSet 无序不可重复TreeSet有序不可重复Map:实现HashMap无序key不可重复TreeMap有序key不可重复HashMap无序key不可重复 线程同步29.HashMap和HashTable区别他们都实现了Map接口 HashMap允许一个null值 HashTable不可为nullHashTab
2021-02-04 10:39:32
141
1
原创 看书Java2
对java程序员笔试解析 整理(2)第一章 Java语言基础19.Java类加载器原理类的加载方式分为显式装载和隐式装载。隐式装载就是程序使用new等方式创建会隐式的调用类加载器把对应类加载到JVM中。显式装载是指直接通过class.forName()方式加载。java语言把类分为三类:系统类,拓展类和自定义类。Bootstrap Loader加载系统类ExtClassLoader 加载拓展类AppClassLoader 加载应用类通过双亲委托机制加载:当又类需要加载时,类加载器会首先请
2021-01-30 18:54:39
114
原创 看书Java1
对java程序员笔试解析 整理第一章 Java语言基础1.Java语言特点面向对象 跨平台 内置库类 支持web开发 安全性和健壮性2.形参和实参的区别形参作业范围为方法内部,生命周期与方法调用相同,形参在方法调用时分配内存,调用结束释放方法调用过程只能将实参赋给形参,因此对形参的改变不会影响实参的值3.指针是所指内容的地址,引用是某块地址的别称。指针可以执行加减运算,引用不行4.&和&&的区别&是按位与操作符,a&b就是把ab转为二进制然后按位
2021-01-29 19:49:31
139
原创 反转链表
反转链表输入一个链表,反转链表后,输出新链表的表头。 示例1输入{1,2,3}返回值{3,2,1}第一种:遍历头插法 public ListNode ReverseList(ListNode head) { //遍历 头插法 if(head == null) return null; ListNode p = new ListNode(head.val); while(head.next != null){
2020-12-16 20:17:50
127
原创 java多线程学习
多线程:指的是这个程序(一个进程)运行时产生了不止一个线程 并行与并发并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。线程安全:经常用来描绘一段代码。指在并发的情况之下,该代码经过多线程使用,线程的调度顺序不影响任何结果。这个时候使用多线程,我们只需要关注系统的内存,cp.
2020-11-28 21:13:28
112
原创 计算机网络基础知识总结
网络层次划分OSI七层网络模型IP地址子网掩码及网络划分ARP/RARP协议路由选择协议TCP/IP协议UDP协议DNS协议NAT协议DHCP协议HTTP协议一个举例计算机网络学习的核心内容就是网络协议的学习。网络协议是为计算机网络中进行数据交换而建立的规则、标准或者说是约定的集合。因为不同用户的数据终端可能采取的字符集是不同的,两者需要进行通信,必须要在一定的标准上进行。一个很形象地比喻就是我们的语言,我们大天朝地广人多,地方性语言也非常丰富,而且方言之间差距巨大。A地区的.
2020-11-25 19:18:53
582
原创 计算机网络-TCP和UDP实现可靠性传输
udp与tcp的区别TCP(TransmissionControl Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。UDP是User Datagram Protocol,一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务。可靠性由上层应用实现,所以要实现udp可靠性传输,必须通过应用层来实现和控制。TCP如何实现可靠性传输?确认机制、重传机制、滑动窗口。可靠性1.应用数据被分割成TCP认为最适合发送的数据块。这和UDP完全不同,应用程序产生的数据
2020-11-25 19:01:09
1152
原创 计算机网络-流量控制\拥塞控制
拥塞控制和流量控制流量控制:如果发送方把数据发送得过快,接收方可能会来不及接收,这就会造成数据的丢失。TCP的流量控制是利用滑动窗口机制实现的,接收方在返回的数据中会包含自己的接收窗口的大小,以控制发送方的数据发送。拥塞控制:拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。两者的区别:流量控制是为了预防拥塞。如:在马路上行车,交警跟红绿灯是流量控制,当发生拥塞时,如何进行疏散,是拥塞控制。流量控制指点对点通信量的控制。而拥塞控制是全局性的,涉及到所有的主机和降低网络
2020-11-25 18:51:32
1055
原创 计算机网络-TCP的三次握手与四次挥手理解及面试
TCP的三次握手与四次挥手理解及面试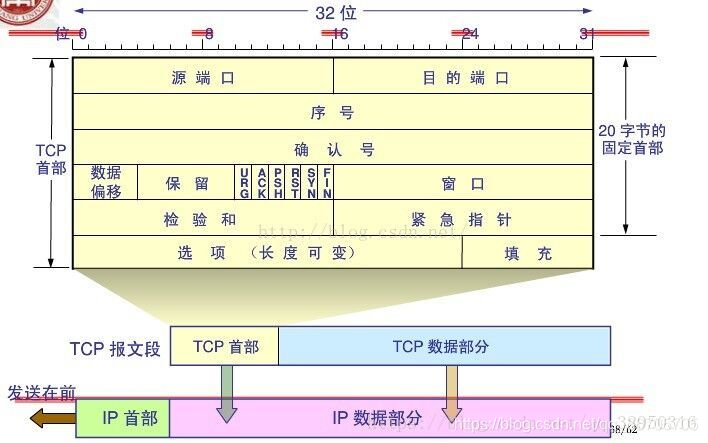序列号seq:占4个字节,用来标记数据段的
2020-11-25 18:47:41
121
原创 计算机网络-OSI7层网络模型协议精析
OSI7层网络模型协议精析OSI 七层模型通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯,因此其最主要的功能就是帮助不同类型的主机实现数据传输 。完成中继功能的节点通常称为中继系统。在OSI七层模型中,处于不同层的中继系统具有不同的名称。一个设备工作在哪一层,关键看它工作时利用哪一层的数据头部信息。网桥工作时,是以MAC头部来决定转发端口的,因此显然它是数据链路层的设备。具体说:物理层:网卡,网线,集线器,中继器,调制解调器数据链路层:网桥,交换机网络层:路由器网关工作
2020-11-25 18:43:09
356
原创 学习路径
计算机网络:osi7层模式,对应协议有什么,都是干嘛的,建议把谢希仁的《计算机网络》传输层那一章好好看看,比如tcp的三次握手,四次挥手,流量控制,拥塞控制,看的时候,不能硬背,要自己理解,才不会忘记,而且在题目有变动的时候,也能应答如流。操作系统:内存管理,进程调度,进程通信,linux常用命令。数据库:事务(ACID)、三级范式(举例)、关联(join)、聚集函数、group by、order by、索引(b+树)、innodb与其他的区别(锁的粒度)数据结构:(重头戏),除了广义表不需要重点看之
2020-11-25 18:34:37
173
原创 每日一面@海康应用开发(Java)
ArrayList的源码,add操作会发生什么一、add(E e) 方法public boolean add(E e) { // 判断是否需要扩容 ensureCapacityInternal(size + 1); // 将新元素追加到相应的数组中 elementData[size++] = e; return true;}ensureCapacityInternal(int minCapacity)方法判断是否需要扩容// minCapacity = size + 1 priv
2020-11-24 21:10:31
206
原创 每日一面#美团大数据
反射机制(1)Java反射机制的核心是在程序运行时动态加载类并获取类的详细信息,从而操作类或对象的属性和方法。本质是JVM得到class对象之后,再通过class对象进行反编译,从而获取t对象的各种信息。(2)Java属于先编译再运行的语言,程序中对象的类型在编译期就确定下来了,而当程序在运行时可能需要动态加载某些类,这些类因为之前用不到,所以没有被加载到JVM。通过反射,可以在运行时动态地创建对象并调用其属性,不需要提前在编译期知道运行的对象是谁。反射的优缺点:1、优点:在运行时获得类的
2020-11-23 16:59:23
267
原创 每日一面@小米-java岗
每日一面jvm垃圾回收算法标记-清除算法(Mark-Sweep)最基础的垃圾回收算法,分为两个阶段,标注和清除。标记阶段标记出所有需要回收的对象,清除阶段回收被标记的对象所占用的空间。标记:遍历内存区域,对需要回收的对象打上标记。清除:再次遍历内存,对已经标记过的内存进行回收。效率问题;遍历了两次内存空间(第一次标记,第二次清除)。空间问题:容易产生大量内存碎片,当再需要一块比较大的内存时,无法找到一块满足要求的,因而不得不再次出发GC。复制算法(Copying)为了解决Mar
2020-11-22 20:54:41
134
原创 每日一题@75分隔链表
给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前。你应当保留两个分区中每个节点的初始相对位置。 示例:输入: head = 1->4->3->2->5->2, x = 3输出: 1->2->2->4->3->5双链表法,把大与 x的节点放在一个新链表,最后两个链表合起来 public ListNode partition(ListNode head, int x) {
2020-11-17 19:11:19
215
SparkKMeans.scala
2020-07-11
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人