



一、实现效果

使用大模型:Funasr(CPU)、CoysVoice2、DeepSeek。
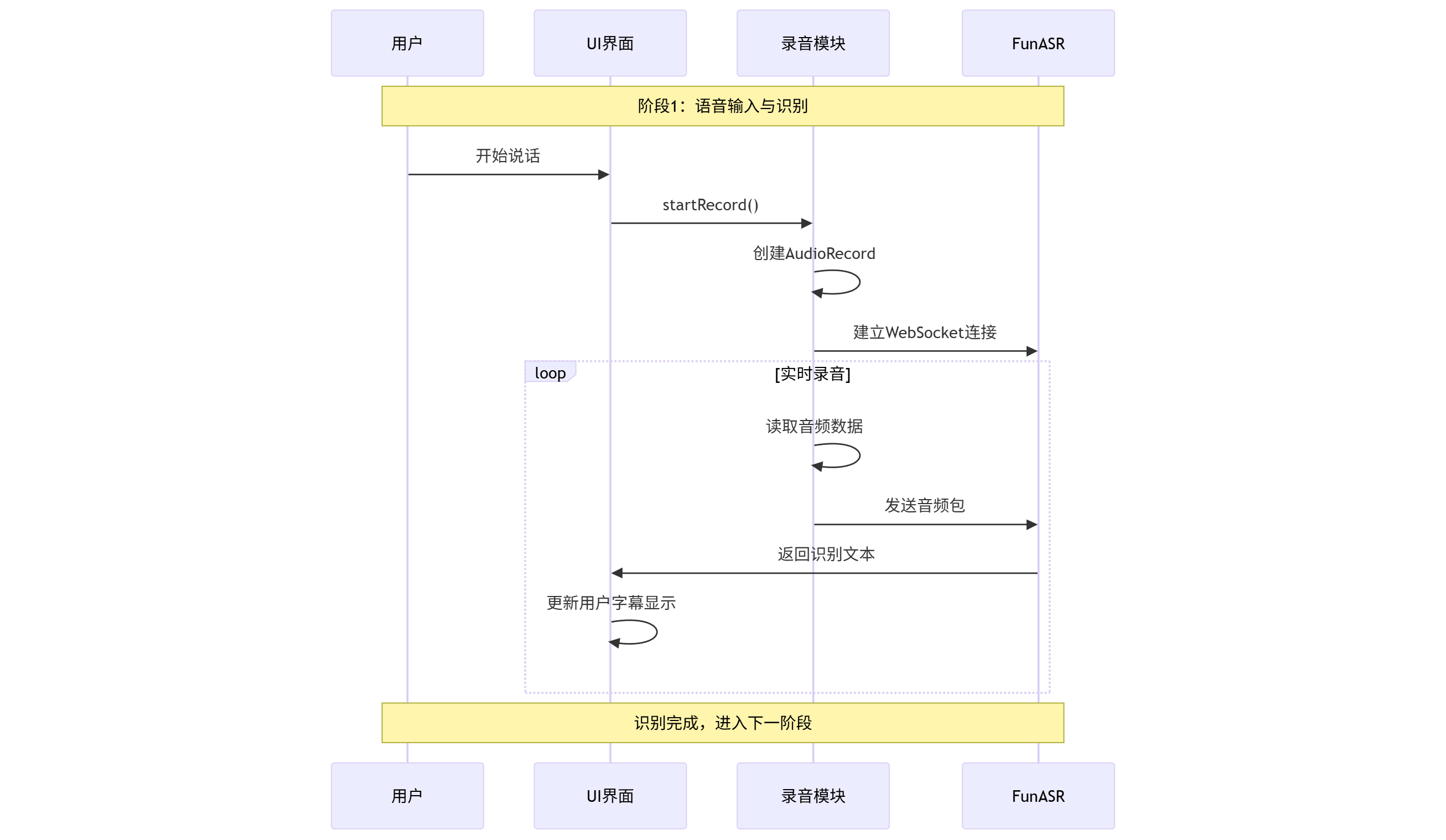
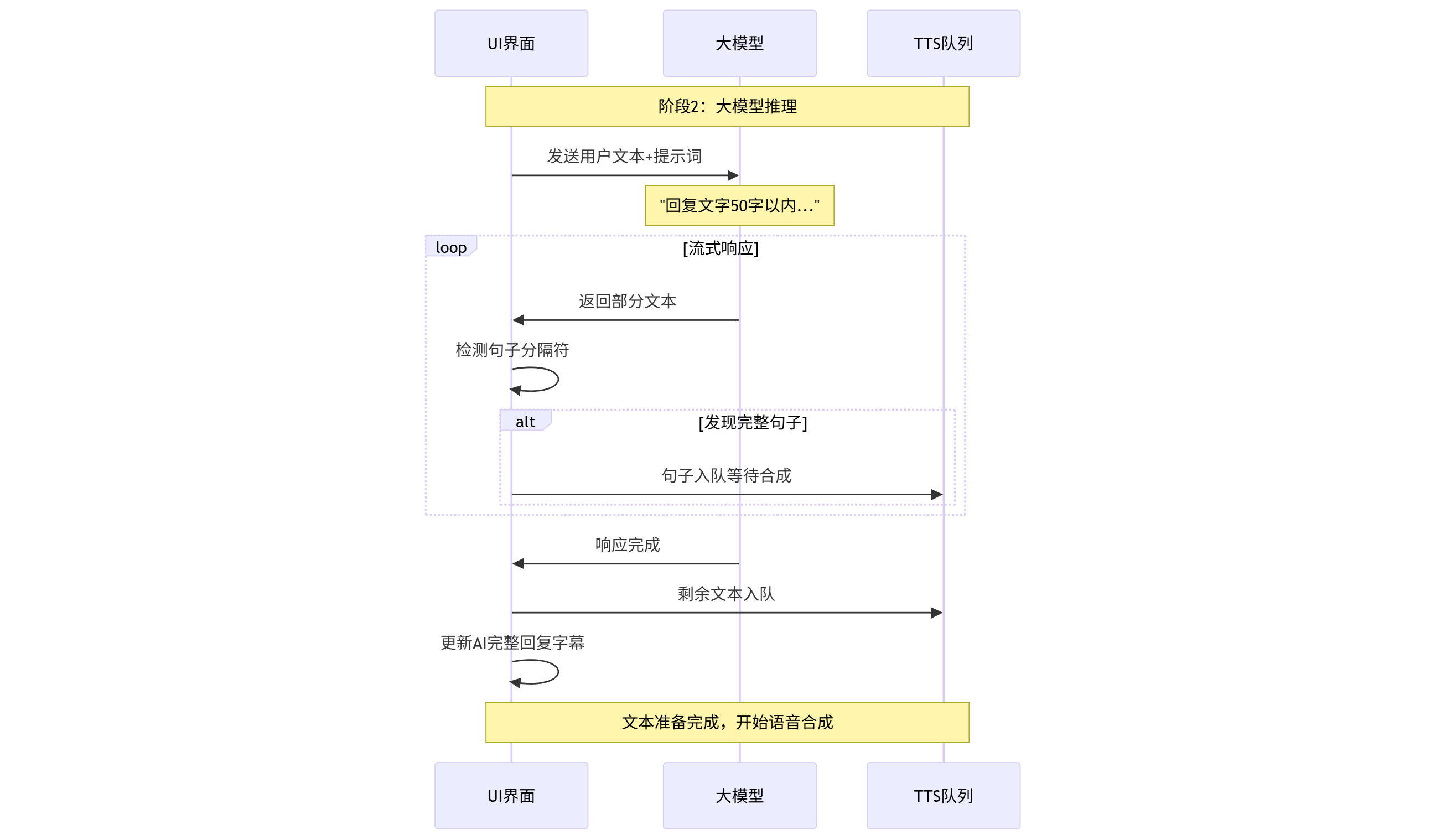
实现思路:使用Funasr实现用户语音识别,将识别的语音转换成文本后,发送给DeepSeek API 接口,deepseek 提示词设置50字以内的文本信息,使用Cosyvoice2 将返回的文本克隆成语音,Android 再播放合成的语音。
ps:在安卓上 Funasr 语音识别和TTS合成语音出现一种回声问题,这里使用MediaPlayer 方法解决。
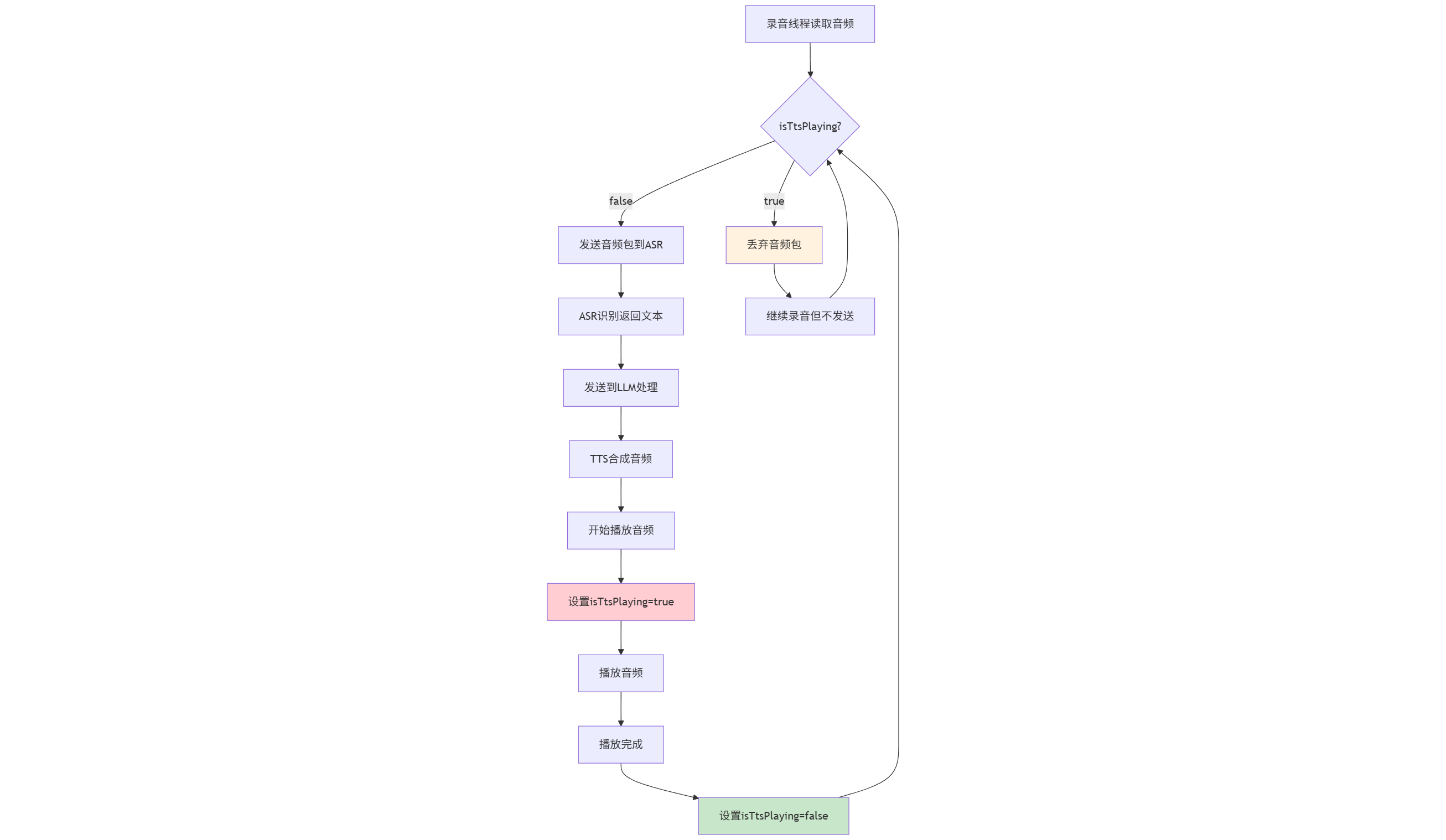
实现逻辑时序图:
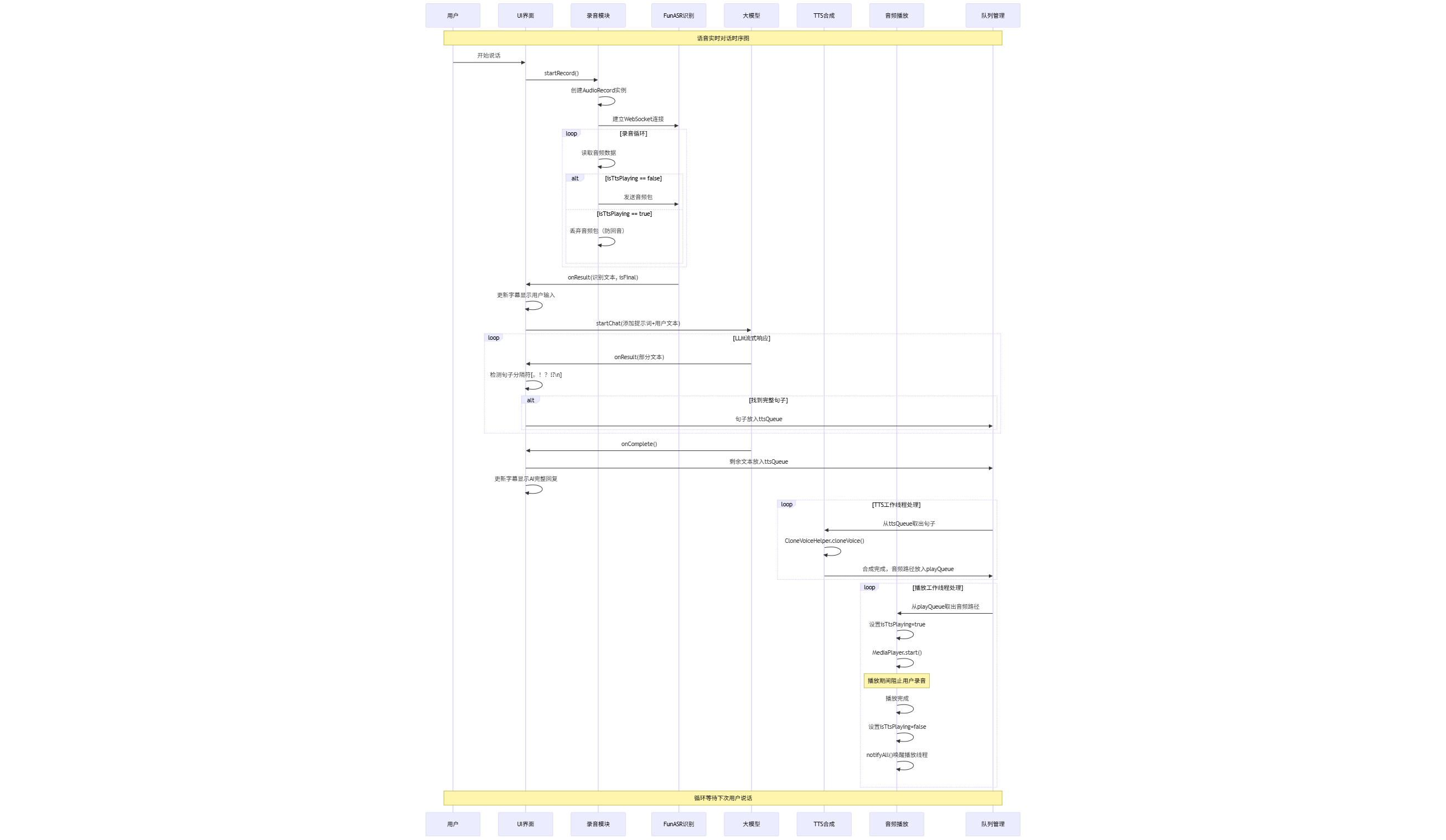
阶段1:语音输入与识别
阶段2:大模型推理
阶段3:语音合成与播放
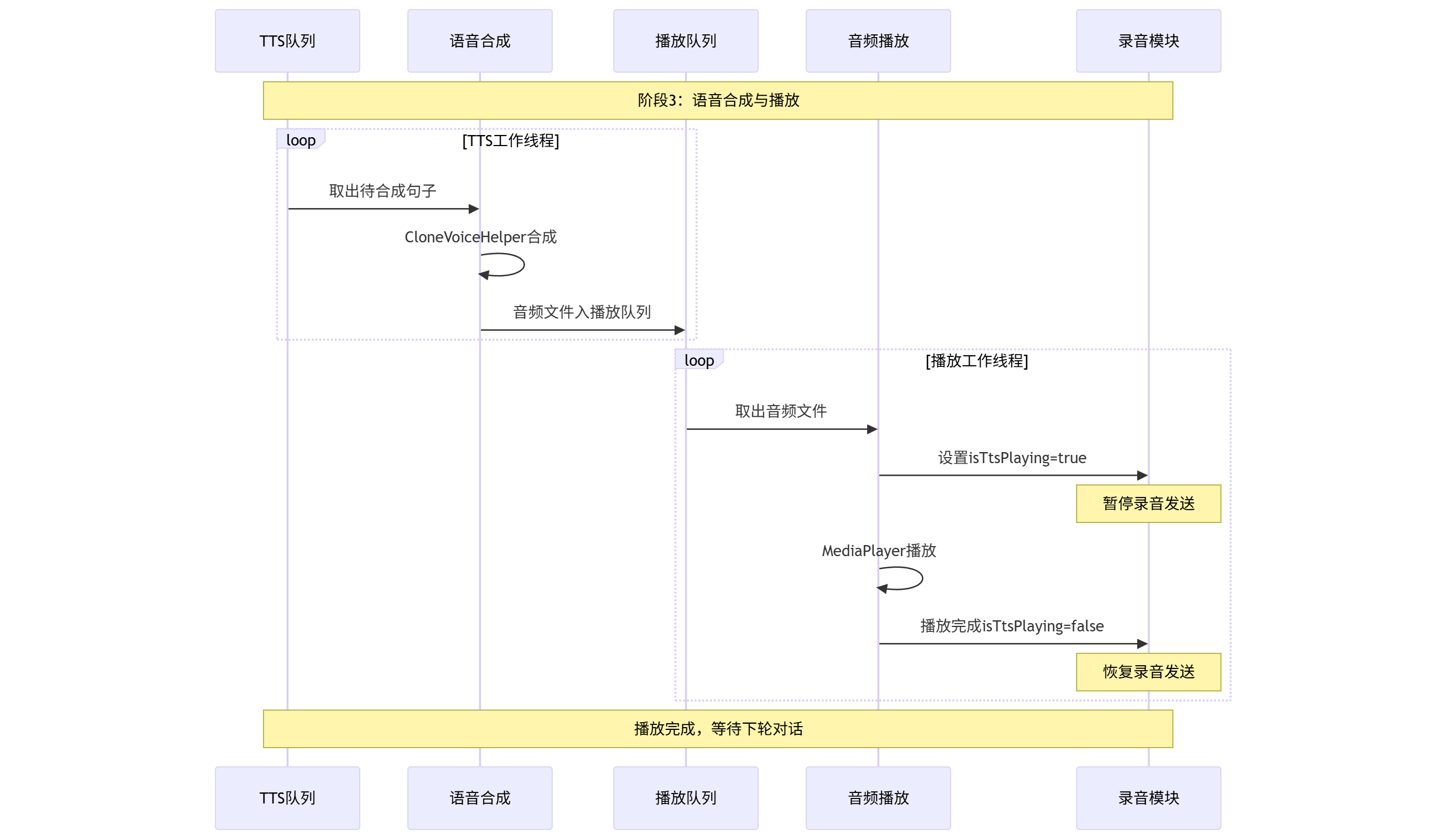
防回音机制
二、安装环境
Windows11、Docker、Python3.10、Android Studio、JDK17、GPU
三、环境安装
1.Docker 安装
https://www.runoob.com/docker/windows-docker-install.html
2.Docker中部署Funasr、CosyVoice2
Funasr 部署:https://github.com/modelscope/FunASR/blob/main/runtime/docs/SDK_advanced_guide_online_zh.md
CosyVoice2 部署:
https://github.com/FunAudioLLM/CosyVoice
3.启动Funasr、Cosyvoice2(使用vllm加速)
- 启动Funasr
cd FunASR/runtime
nohup bash run_server_2pass.sh \
--download-model-dir /workspace/models \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--model-dir damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx \
--punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--hotword /workspace/models/hotwords.txt > log.txt 2>&1 &- cosyvoice2 流式克隆代码:
import os
import sys
import argparse
import logging
logging.getLogger('matplotlib').setLevel(logging.WARNING)
from fastapi import FastAPI, UploadFile, Form, File
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
import uvicorn
import numpy as np
ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append('{}/../../..'.format(ROOT_DIR))
sys.path.append('{}/../../../third_party/Matcha-TTS'.format(ROOT_DIR))
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from vllm import ModelRegistry
from cosyvoice.vllm.cosyvoice2 import CosyVoice2ForCausalLM
ModelRegistry.register_model("CosyVoice2ForCausalLM", CosyVoice2ForCausalLM)
from cosyvoice.utils.file_utils import load_wav
from cosyvoice.utils.common import set_all_random_seed
from cosyvoice.utils.file_utils import load_wav
from fastapi.responses import StreamingResponse, JSONResponse
app = FastAPI()
# set cross region allowance
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"])
def generate_data(model_output):
for i in model_output:
tts_audio = (i['tts_speech'].numpy() * (2 ** 15)).astype(np.int16).tobytes()
yield tts_audio
@app.get("/inference_sft")
@app.post("/inference_sft")
async def inference_sft(tts_text: str = Form(), spk_id: str = Form()):
model_output = cosyvoice.inference_sft(tts_text, spk_id)
return StreamingResponse(generate_data(model_output))
@app.get("/inference_zero_shot_spk")
@app.post("/inference_zero_shot_spk")
async def inference_zero_shot(tts_text: str = Form(),zero_shot_spk_id:str=Form()):
#prompt_speech_16k = load_wav(prompt_wav.file, 16000)
model_output = cosyvoice.inference_zero_shot(tts_text,'', '' , zero_shot_spk_id,stream=False)
return StreamingResponse(generate_data(model_output))
@app.post("/inference_zero_shot")
@app.get("/inference_zero_shot")
async def inference_zero_shot(tts_text: str = Form(), prompt_text: str = Form(), prompt_wav: UploadFile = File()):
prompt_speech_16k = load_wav(prompt_wav.file, 16000)
model_output = cosyvoice.inference_zero_shot(tts_text, prompt_text, prompt_speech_16k)
return StreamingResponse(generate_data(model_output))
@app.post("/register_speaker")
async def register_speaker(
spk_id: str = Form(),
sample_text: str = Form(),
prompt_wav: UploadFile = File()
):
try:
prompt_speech_16k = load_wav(prompt_wav.file, 16000)
cosyvoice.add_zero_shot_spk(sample_text, prompt_speech_16k, spk_id)
cosyvoice.save_spkinfo()
return JSONResponse(
content={
"status": "success",
"message": "Speaker registered successfully",
"available_speakers": cosyvoice.list_available_spks()
}
)
except Exception as e:
return JSONResponse(
status_code=500,
content={
"status": "error",
"message": str(e)
}
)
@app.get("/list_speakers")
async def list_speakers():
try:
return JSONResponse(
content={
"status": "success",
"available_speakers": cosyvoice.list_available_spks()
}
)
except Exception as e:
return JSONResponse(
status_code=500,
content={
"status": "error",
"message": str(e)
}
)
@app.get("/inference_cross_lingual")
@app.post("/inference_cross_lingual")
async def inference_cross_lingual(tts_text: str = Form(), prompt_wav: UploadFile = File()):
prompt_speech_16k = load_wav(prompt_wav.file, 16000)
model_output = cosyvoice.inference_cross_lingual(tts_text, prompt_speech_16k)
return StreamingResponse(generate_data(model_output))
@app.get("/inference_instruct")
@app.post("/inference_instruct")
async def inference_instruct(tts_text: str = Form(), spk_id: str = Form(), instruct_text: str = Form()):
model_output = cosyvoice.inference_instruct(tts_text, spk_id, instruct_text)
return StreamingResponse(generate_data(model_output))
@app.get("/inference_instruct2")
@app.post("/inference_instruct2")
async def inference_instruct2(tts_text: str = Form(), instruct_text: str = Form(), prompt_wav: UploadFile = File()):
prompt_speech_16k = load_wav(prompt_wav.file, 16000)
model_output = cosyvoice.inference_instruct2(tts_text, instruct_text, prompt_speech_16k)
return StreamingResponse(generate_data(model_output))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--port',
type=int,
default=7860)
parser.add_argument('--model_dir',
type=str,
default='/workspace/CosyVoice/pretrained_models/CosyVoice2-0.5B',
help='local path or modelscope repo id')
args = parser.parse_args()
try:
cosyvoice = CosyVoice(args.model_dir,load_jit=True, load_trt=True, load_vllm=True, fp16=True)
except Exception:
try:
cosyvoice = CosyVoice2(args.model_dir,load_jit=True, load_trt=True, load_vllm=True, fp16=True)
except Exception:
raise TypeError('no valid model_type!')
uvicorn.run(app, host="0.0.0.0", port=args.port)- 运行
conda activate cosyvoice_vllm
nohup python server.py > log.txt 2>&1 &
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









