




 本文探讨了使用 commodity 深度传感器进行动作识别的方法,针对深度数据噪声和遮挡问题,提出了一种 actionlet ensemble 模型。通过提取关节相对位置(skeleton feature)、局部占用模式(LOP feature)和傅立叶时频金字塔(Fourier Temporal Pyramid)特征,增强了特征的鲁棒性和区分性。同时,通过挖掘区分性关节组合(actionlets)和多核 SVM 进行分类,提高了动作识别的准确性。
本文探讨了使用 commodity 深度传感器进行动作识别的方法,针对深度数据噪声和遮挡问题,提出了一种 actionlet ensemble 模型。通过提取关节相对位置(skeleton feature)、局部占用模式(LOP feature)和傅立叶时频金字塔(Fourier Temporal Pyramid)特征,增强了特征的鲁棒性和区分性。同时,通过挖掘区分性关节组合(actionlets)和多核 SVM 进行分类,提高了动作识别的准确性。
目录
1、Invariant Features for 3D Joint Positions(skeleton feature)
2、Local Occupancy Patterns(LOP feature)
4、Mining Discriminative Actionlets
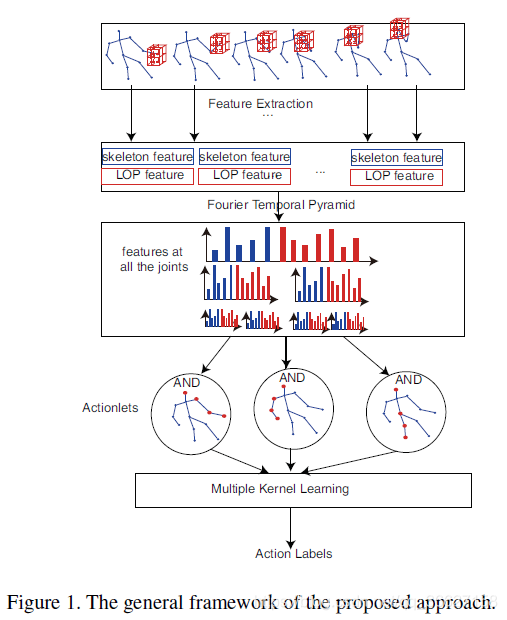
论文名称:Mining actionlet ensemble for action recognition with depth cameras(2012 CVPR)
下载地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6247813
Summary
这是一篇对 skeleton data 用 handcrafted feature 做动作识别任务的文章。
作者这么做的 motivation 是:
The recently developed commodity depth sensors open up new possibilities of dealing with this problem but also present some unique challenges:The depth maps captured by the depth cameras are very noisy and the 3D positions ofthe tracked joints may be completely wrong if serious occlusions occur, which increases the intra-class variations in the actions.
于是,作者提出了一个 actionlet ensemble 的模型:
1、对每个节点提取 skeleton feature(the 3D joint position feature)oi 和 LOP(local occupancy pattern) feature pi,concatenate 起来作为每个节点的一个特征 gi。
2、再对每个节点进行 Fourier Temporal Pyramid 建模,得到每个节点包含时序维度的建模信息 Gi。
3、接着对每一个类别,挖掘有助于区分动作类别的节点组合 actionlets(一个 actionlets 定义为所有节点的一个子集,节点组合)。
4、最后对 actionlets 做一个多核 SVM(linear output),对动作进行分类。
Details
1、Invariant Features for 3D Joint Positions(skeleton feature)
具体怎么做
首先,each joint i has 3 coordinates pi(t) = (xi(t), yi(t), zi(t)) at a frame t. The coordinates are normalized so that the motion is invariant to the absolute body position, the initial body orientation and the body size.
接着,For each joint i, we extract the pairwise relative position features by taking the difference between the position of joint i and that of each other joint j:
![]()
The 3D joint feature for joint i is then defined as: pi
![]()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









