







GAN生成动漫头像
这篇文章主要是听的李宏毅老师的GAN课程,结合了一些《深度学习框架pytorch入门与实践》中的代码实现的。
GAN原理简介
GAN(Generative adversarial Networks)生成对抗网络,GAN解决了一个著名问题:给定一批样本,训练一个系统可以生成类似的新样本。生成对抗网络,顾名思义,有两个部分一个是生成器(Generator),一个判别器(Discriminator),两者相互对抗,左右互博。
- 生成器(Generator):输入一个随机噪声,生成一张图片
- 判别器(Discriminator):判别图像是真图片还是假图片
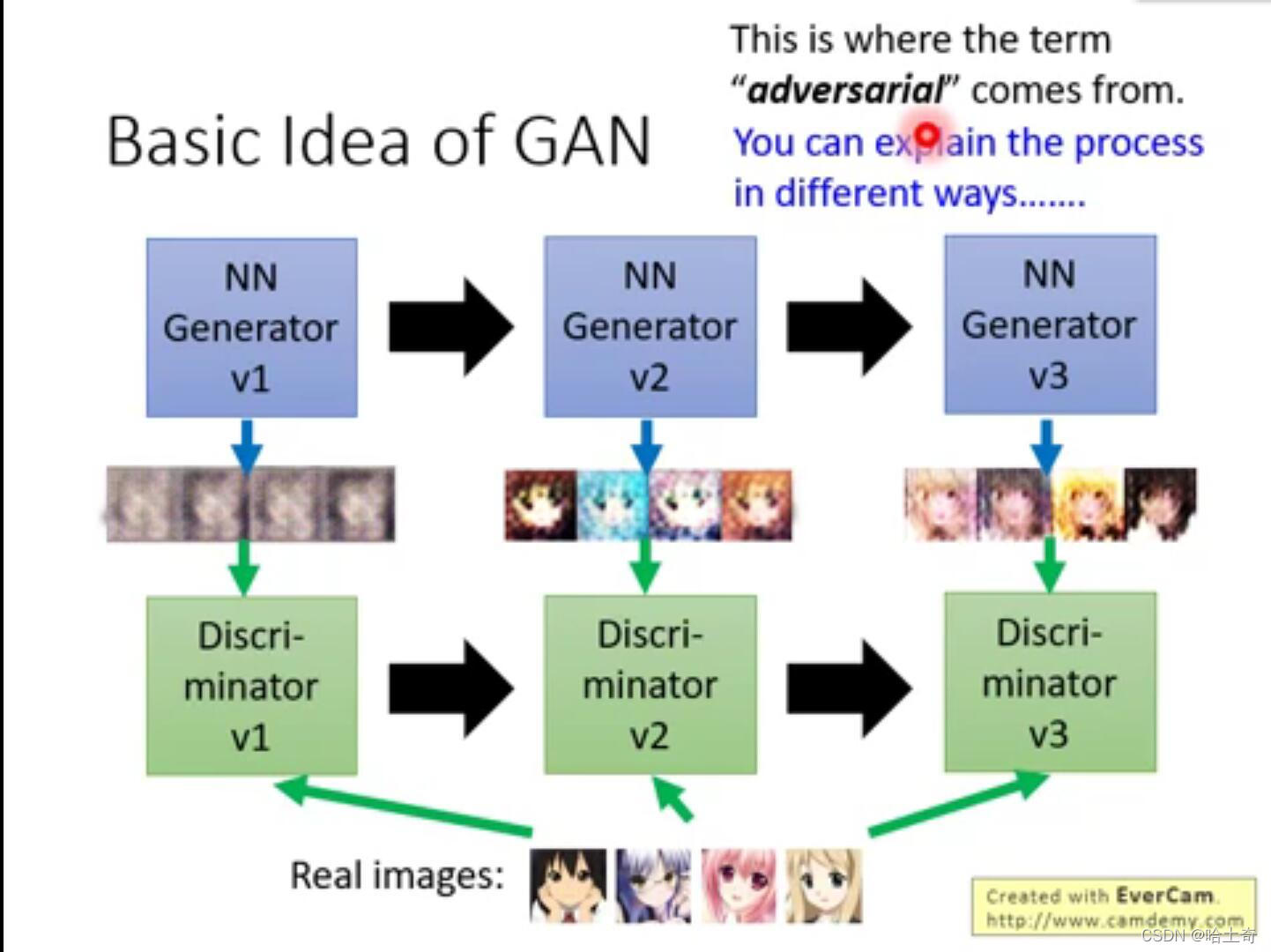
如图展示了基本训练过程,第一代的生成器最开始由于是随机初始化,传入一个随机噪点,产生的图片是模糊一片,第一代判别器做的事情就是,能够辨别图片是第一代的生成器产生的图片,还是真实图片。可能第一代判别器认为有颜色的是真图,而生成器要骗过判别器,所以要进化,进化成了第二代,产生有颜色的图片。判别器也随之进化,找出有嘴巴的是真图,辨别出了生成图和真图。那么生成器也进化到第三代,产生了嘴巴的图片,骗过第二代的判别器,判别器又进化成第三代。一步一步对抗,相互进化,最终生成二次元头像。
算法过程
训练Discriminator
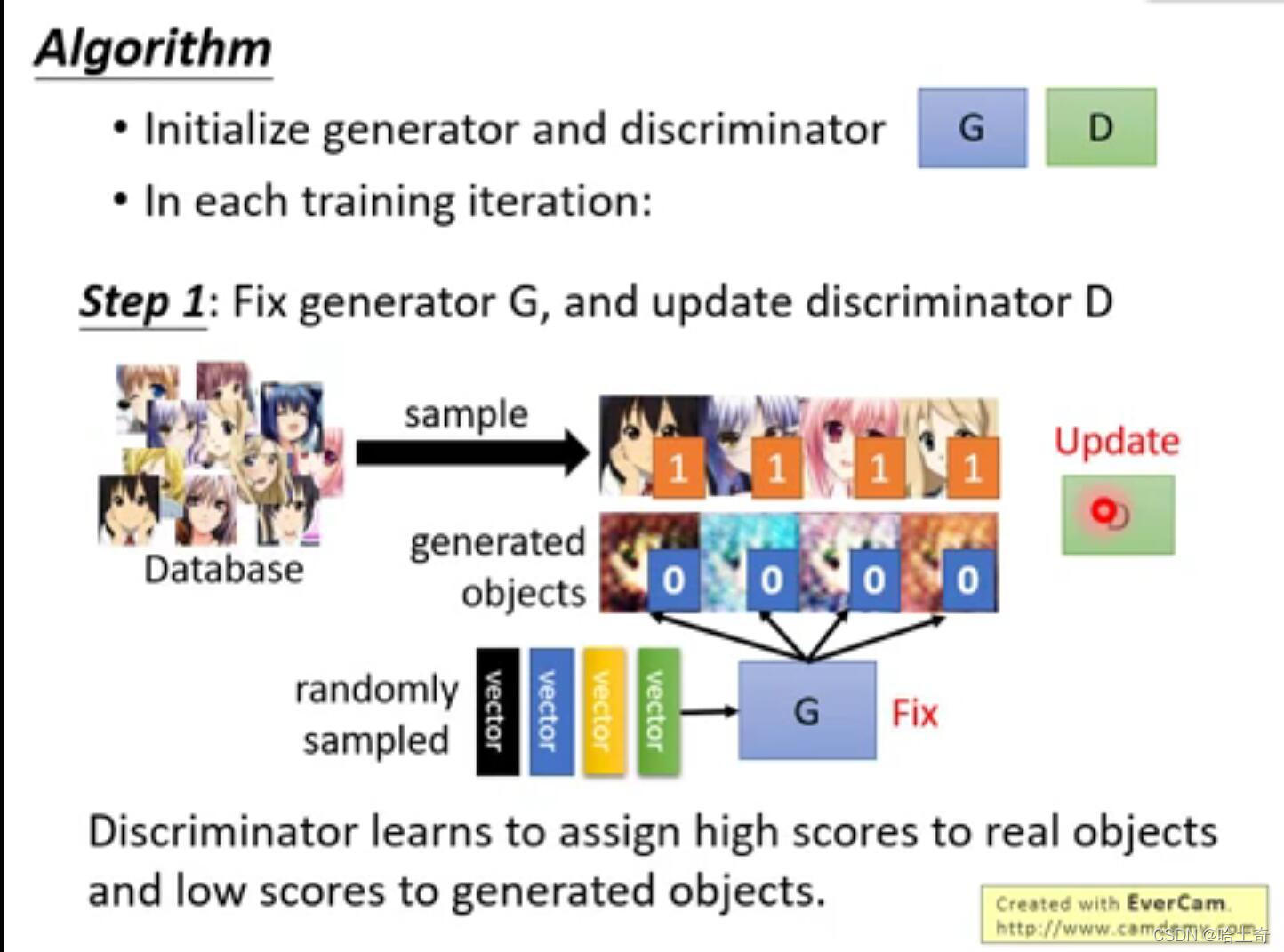
首先初始化生成器和判别器,在每次训练迭代中,先固定住生成器,传入随机噪点给生成器,生成对应的图片。前面说了判别器的任务是判别真假图片,判别器主要是给图片打分,分数越高认为真图片的概率越高,分数越低认为是假图片概率越高。所以训练判别器时,收到Database中的图和生成器给的图,调整参数,如果是Database的图就给高分,如果是生成器给的图就给低分。换句话说,我们训练处的判别器就是要数据集给的图越接近1越好,生成器给的图越接近0越好。
训练Generator
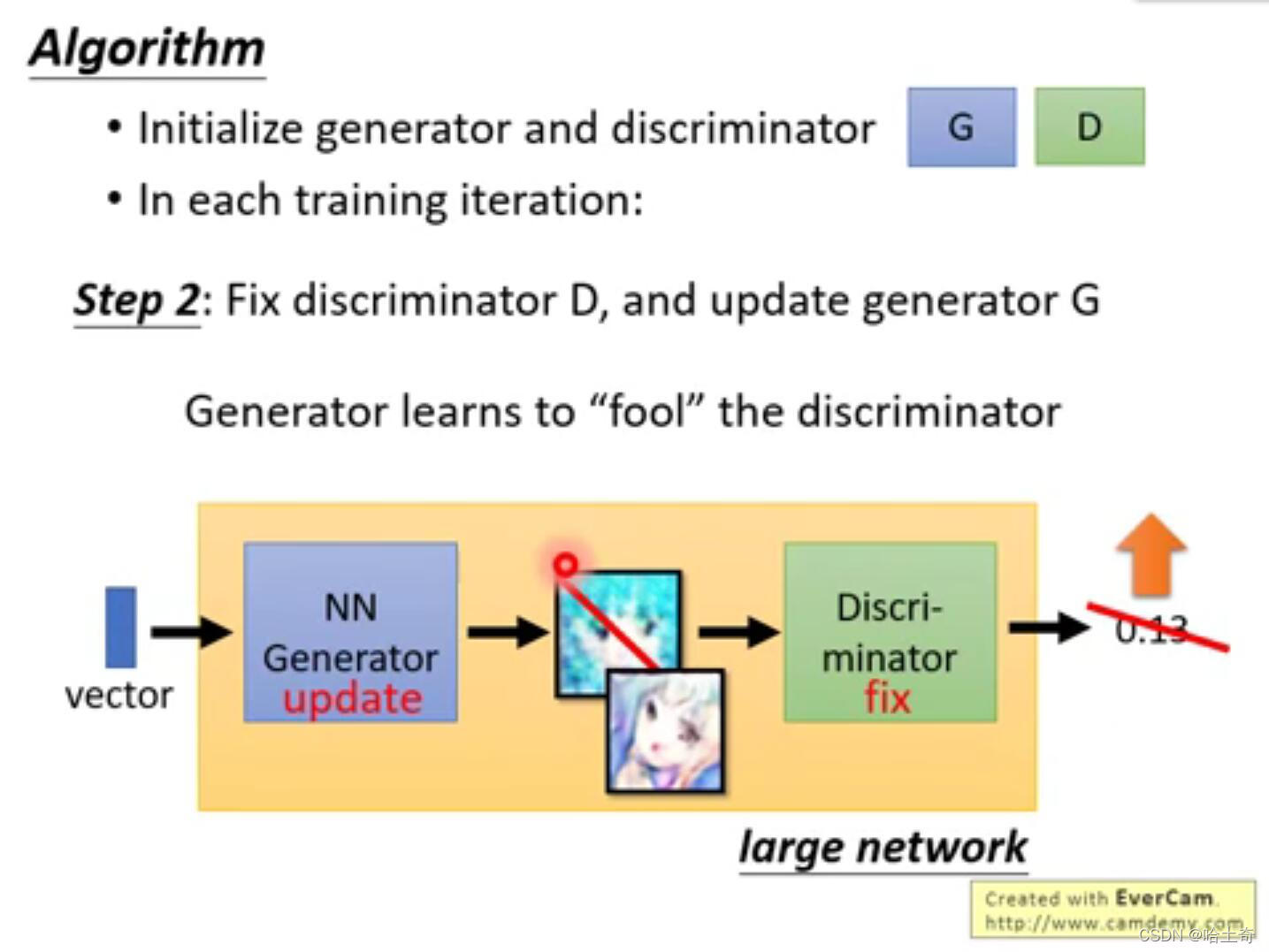
前面训练好了判别器,现在训练生成器,生成器需要做的事情是,收到随机噪点,产生一张图片,要“骗”过判别器。如何“骗”过生成器呢。实际上的做法是,将生成的图片,送到判别器中进行评分,目标是让评分越高越好(越接近1越好)。整个部分可以看做整体,就是一个巨大的hidden layer,其中有Generator和Discriminator,输入噪点,生成评分。调整参数让评分不断靠近1,但是中间部分Discriminator不能调整。
整个过程

- 从数据集中选出m个样本{x1,x2…xm};接着创建m个噪声,这个z的维度由自己决定,这个就是后面生成器输入的噪声;获取生成数据,就是G(z)生成器生成的;更新判别器参数,使得下面的公式最大化,下边公式的意思是:D(x)判别器判别真图片的分数去log平均值 加上 1 - 判别器判别假图片的值 的log平均值。简单说就是要判别真图片的分数越大越好,判别假图片时,假图片的评分距离1的值越远越好。(相当于训练二分类器,用bceloss)
- m个噪点z,更新生成器,生成器根据z产生的图片,喂给判别器,产生的分数越高越好。
BCE Loss
bce loss分类,用于二分类问题。数学公式如下
l
o
s
s
(
X
i
,
y
i
)
=
−
w
i
[
y
i
l
o
g
x
i
+
(
1
−
y
i
)
l
o
g
(
1
−
x
i
)
]
loss(X_i,y_i) = -w_i[y_ilogx_i + (1 - y_i)log(1 - xi)]
loss(Xi,yi)=−wi[yilogxi+(1−yi)log(1−xi)]
pytorch中bceloss
class torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')
weight: 初始化权重矩阵
size_average: 默认是True,对loss求平均数
reduction: 默认求和, 对于batch_size的loss平均数
代码实现
前面的理论了解之后,可以着手实现了我这里用的数据集是Extra Data,也可以用Anime Dataset尝试。请自行找梯子。
初始化
import matplotlib.pyplot as plt
import torch
import torchvision
import torchvision.datasets as DataSet
import torchvision.transforms as transform
import torch.utils.data as Data
import numpy as np
import torch.nn as nn
import torch.optim as optim
import os
# 用于图片保存
def saveImg(inp, name):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.5, 0.5, 0.5])
std = np.array([0.5, 0.5, 0.5])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
plt.savefig(name)
# 用于图片显示,可以调试数据集是否加载成功
def imgshow(inp):
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.5, 0.5, 0.5])
std = np.array([0.5, 0.5, 0.5])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
plt.show()
batch_size = 20
# 图像处理,尺寸转为64 * 64,转tensor范围(0,1), Normalize之后转为 (-1, 1)
simple_transform = transform.Compose([
transform.Resize((64, 64)),
transform.ToTensor(),
transform.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 使用GPU or CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 噪点数量
noise_z = 100
generator_feature_map = 64
# 加载数据集
path = "AnimeDataset"
train_set = DataSet.ImageFolder(path, simple_transform)
train_loader = Data.DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
# 正确分数标签
true_label = torch.ones(batch_size).to(device)
true_label = true_label.view(-1, 1)
# 错误分数标签
false_label = torch.zeros(batch_size).to(device)
false_label = false_label.view(-1, 1)
# 固定的noises,这样在每个Epoch完成之后可以看到generator产生同个照片的过程
fix_noises = torch.randn(batch_size, noise_z, 1, 1).to(device)
# 随机noises
noises = torch.randn(batch_size, noise_z, 1, 1).to(device)
g_train_cycle = 1 # 训练生成器周期
save_img_cycle = 1 # 每几次epoch输出一次结果
print_step = 200 # 打印loss 信息周期
bceloss = nn.BCELoss()
生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.layer1 = nn.Sequential(
# 100*1*1 --> (64 * 8) * 4 *4
nn.ConvTranspose2d(noise_z, generator_feature_map * 8, kernel_size=4, bias=False),
nn.BatchNorm2d(generator_feature_map * 8),
nn.ReLU(True))
self.layer2 = nn.Sequential(
# (64 * 8) * 4 * 4 --> (64 * 4)*8*8
nn.ConvTranspose2d(generator_feature_map * 8, generator_feature_map * 4, kernel_size=4, stride=2,
padding=1),
nn.BatchNorm2d(generator_feature_map * 4),
nn.ReLU(True))
self.layer3 = nn.Sequential(
# (64*4)*8*8 --> (64*2)*16*16
nn.ConvTranspose2d(generator_feature_map * 4, generator_feature_map * 2, kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(generator_feature_map * 2),
nn.ReLU(True))
self.layer4 = nn.Sequential(
# (64*2)*16*16 --> 64*32*32
nn.ConvTranspose2d(generator_feature_map * 2, generator_feature_map, kernel_size=4, stride=2, padding=1,
bias=False),
nn.BatchNorm2d(generator_feature_map),
nn.ReLU(True))
self.layer5 = nn.Sequential(
# 64*32*32 --> 3*64*64
nn.ConvTranspose2d(generator_feature_map, 3, kernel_size=4, stride=2, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.layer5(out)
return out
判别器
class Discriminator(nn.Module):
def __init__(self, ndf=64):
super(Discriminator, self).__init__()
# layer1 输入 3 x 96 x 96, 输出 (ndf) x 32 x 32
self.layer1 = nn.Sequential(
nn.Conv2d(3, ndf, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ndf),
nn.LeakyReLU(0.2, inplace=True)
)
# layer2 输出 (ndf*2) x 16 x 16
self.layer2 = nn.Sequential(
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True)
)
# layer3 输出 (ndf*4) x 8 x 8
self.layer3 = nn.Sequential(
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True)
)
# layer4 输出 (ndf*8) x 4 x 4
self.layer4 = nn.Sequential(
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True)
)
# layer5 输出一个数(概率)
self.layer5 = nn.Sequential(
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
# 定义NetD的前向传播
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.layer5(out)
out = out.view(-1,1)
return out
优化器
generator = Generator().to(device)
discriminator = Discriminator().to(device)
learning_rate = 0.0002
beta = 0.5
# 优化器初始化
g_optim = optim.Adam(generator.parameters(), lr=learning_rate, betas=(beta, 0.999))
d_optim = optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(beta, 0.999))
损失函数
def loss_g_func(testLabel, trueLabel):
return bceloss(testLabel, trueLabel)
def loss_d_func(real_predicts, real_labels, fake_predicts, fake_labels):
real = bceloss(real_predicts, real_labels) # 真图片分数,不断靠近1
fake = bceloss(fake_predicts, fake_labels) # 假图片分数,不断靠近0
real.backward()
fake.backward()
return real + fake
开始训练
# 训练Discriminator
train_num = 25
for trainIdx in range(train_num):
for step, data in enumerate(train_loader):
image_x, _ = data
image_x = image_x.to(device)
# 训练判别器
noises.data.copy_(torch.randn(batch_size, noise_z, 1, 1))
out = discriminator(image_x) # 原图产生的分数
fake_pic = generator(noises) # 生成器生成图像
fake_predict = discriminator(fake_pic.detach()) # 使用detach()切断求导关联
d_optim.zero_grad()
dloss = loss_d_func(out, true_label, fake_predict, false_label)
d_optim.step()
if step % g_train_cycle == 0:
# 训练生成器
g_optim.zero_grad()
noises.data.copy_(torch.randn(batch_size, noise_z, 1, 1))
fake_img = generator(noises)
fake_out = discriminator(fake_img)
# 尽可能让判别器把假图判别为1
loss_fake = loss_g_func(fake_out, true_label)
loss_fake.backward()
g_optim.step()
if step % print_step == print_step - 1:
print("train: ", trainIdx, "step: ", step + 1, " d_loss: ", dloss.item(), "mean score: ",
torch.mean(out).item())
print("train: ", trainIdx, "step: ", step + 1, " g_loss: ", loss_fake.item(), "mean score: ",
torch.mean(fake_out).item())
if trainIdx % save_img_cycle == 0:
fix_fake_image = generator(fix_noises)
fix_fake_image = fix_fake_image.data.cpu()
comb_img = torchvision.utils.make_grid(fix_fake_image, nrow=4)
savepath = os.path.join("gan", "pics", "g_%s.jpg" % trainIdx)
saveImg(comb_img, savepath)
torch.save(discriminator.state_dict(), './gan/netd_%s.pth' % trainIdx)
torch.save(generator.state_dict(), './gan/netg_%s.pth' % trainIdx)
结果
这个是1个Epoch的效果
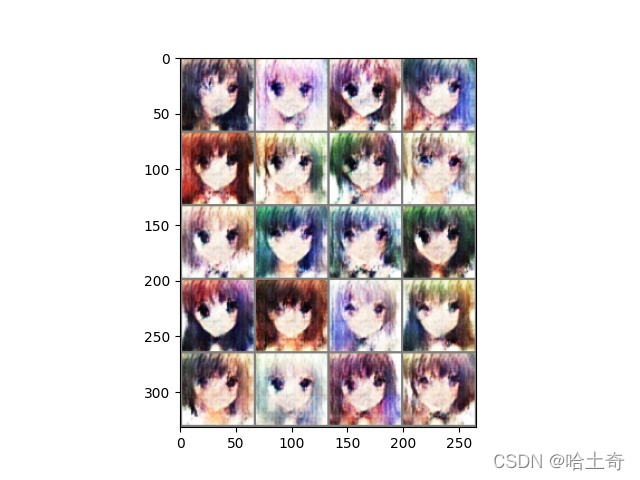
5个Epoch
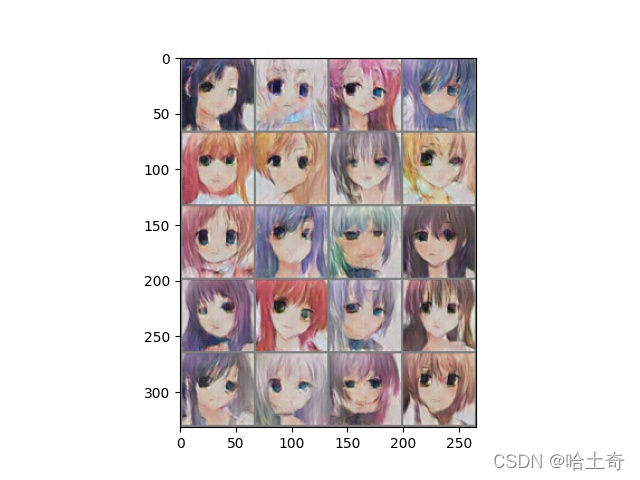
10个Epoch
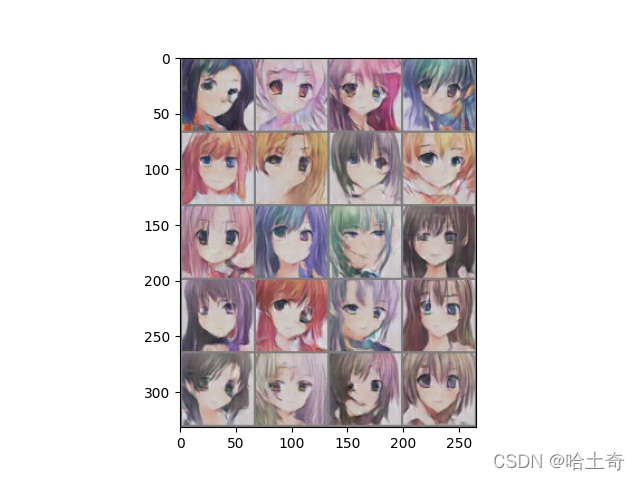
25个Epoch
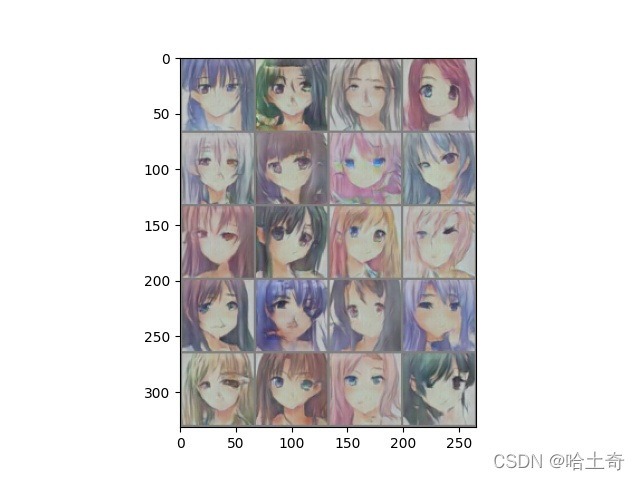

















 1645
1645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









