







 本文介绍了爬虫的基本概念,包括通用爬虫、聚焦爬虫、增量式爬虫和分布式爬虫。重点讲解了requests模块在爬虫中的应用,以及如何通过UA伪装应对网站的反爬机制。同时,通过案例展示了如何爬取搜狗搜索首页、动态加载数据如豆瓣电影、肯德基餐厅信息、化妆品生产许可信息和荣耀线下门店信息,并涉及图片的爬取方法。
本文介绍了爬虫的基本概念,包括通用爬虫、聚焦爬虫、增量式爬虫和分布式爬虫。重点讲解了requests模块在爬虫中的应用,以及如何通过UA伪装应对网站的反爬机制。同时,通过案例展示了如何爬取搜狗搜索首页、动态加载数据如豆瓣电影、肯德基餐厅信息、化妆品生产许可信息和荣耀线下门店信息,并涉及图片的爬取方法。
爬虫
1 爬虫介绍
1.1 什么是爬虫
爬虫是通过编写程序来模拟浏览器上网,然后从网页中抓取数据的过程,也可以理解为让代码代替人去检测并获取网站上某个位置的数据。
难点:如何让代码伪装成人类(正常使用者)向网站发送请求。
1.2 分类
1.2.1 通用爬虫与聚焦爬虫
通用爬虫:抓取一张网页的全部源码。
聚焦爬虫:抓取一张网页中的局部内容,聚焦爬虫是建立在通用爬虫的基础上的。
1.2.2 增量式爬虫与分布式爬虫
增量式爬虫是在上一次爬虫的基础上继续爬取数据,适用于继续爬取因故未爬完的数据或网站更新的数据;
分布式爬虫是在多个服务器上部署爬虫程序,是一种提高爬取效率的方法。
1.3 反爬机制与反反爬策略
反爬机制
反爬机制是应用于网站中,用于阻止爬虫程序对网站数据进行爬取。
反反爬策略
反反爬策略是应用于爬虫中,用于破解网站的反爬机制从而实现对网站中的数据进行爬取。
1.4 requests模块
requests模块是一个基于网络请求的模块,可用于模拟浏览器上网过程。
流程:
- 指定url
- 发起请求
- 获取响应数据
- 持久化存储
1.5 Chrome的开发者工具中Elements和Network-Response的区别
Elements:显示的是当前网页加载完毕后对应的所有数据(包含动态加载的数据);
Network中的Response:显示的内容是每个请求资源数据。
如果页面中没有动态加载的数据,则这两者显示的页面源码没有区别。
如果存在动态加载的数据,Elements显示的是当前页面中所有的请求资源加载完毕后的总的网页源代码,而Network中的Response中显示的是页面加载过程中每一个请求资源信息。
Network面板常用于web抓包。
2 案例 搜狗搜索首页
2.1 爬取搜狗首页的页面源码
import requests
# 指定url
target_url = 'https://www.sogou.com/'
# 发起请求,获取响应对象
response_obj = requests.get(url=target_url) # 请求方式为get
# 获取响应数据
page_text = response_obj.text # 以字符串的形式获取响应数据
# 持久化存储数据
with open('./sogou.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
2.2 简易的网页采集器
基于搜狗搜索爬取任意检索关键字的页面源码。
重点:
- 避免乱码
- UA伪装
keyword = input('Please enter a keyword:')
target_url = 'https://www.sogou.com/web'
params = {
'query': keyword
}
# 进行UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
response_obj = requests.get(url=target_url, headers=headers, params=params)
# 设置响应数据的编码格式,避免乱码。
response_obj.encoding = 'utf-8'
page_text = response_obj.text
filename = '{keyword}.html'.format(keyword=keyword)
with open(filename, 'w', encoding='utf-8') as fp:
fp.write(page_text)
2.3 反反爬策略1:UA伪装
异常访问请求
非浏览器对网站发起的请求就称为异常访问请求。
User-Agent
用户代理,简称 UA,是一个特殊字符串头,表示请求载体的身份标识。
服务器能够通过UA识别用户使用的操作系统及版本、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
反爬机制
某些网站会对访问该网站的请求头中的User-Agent进行获取并判断,如果通过UA将请求者识别为爬虫程序,网站就拒绝提供数据。
反反爬策略:
将爬虫发起的请求中的UA伪装成某一款浏览器的身份标识。
常见的User-Agent
Safari:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50
Chrome
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36
Firefox
Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0
3 案例 爬取动态加载数据
动态加载数据
通过另一个新的请求获取的数据叫做动态加载数据。
动态加载数据是无法通过对浏览器地址栏中的当前页面url发请求来获取的。
3.1 豆瓣电影
豆瓣电影 选电影 https://movie.douban.com/explore
目标:爬取热门电影页面中显示的电影名称和评分。
- 判断目标数据是否属于动态加载数据
在Chrome的选项卡Network中,找到当前地址栏中的url对应的数据包,在其内部选项卡Response中局部检索一个页面上显示的电影名,例如想哭的我戴上了猫的面具。如果没有检索到,说明当前url对应的数据包中没有电影数据,页面上显示的电影数据属于动态加载数据。
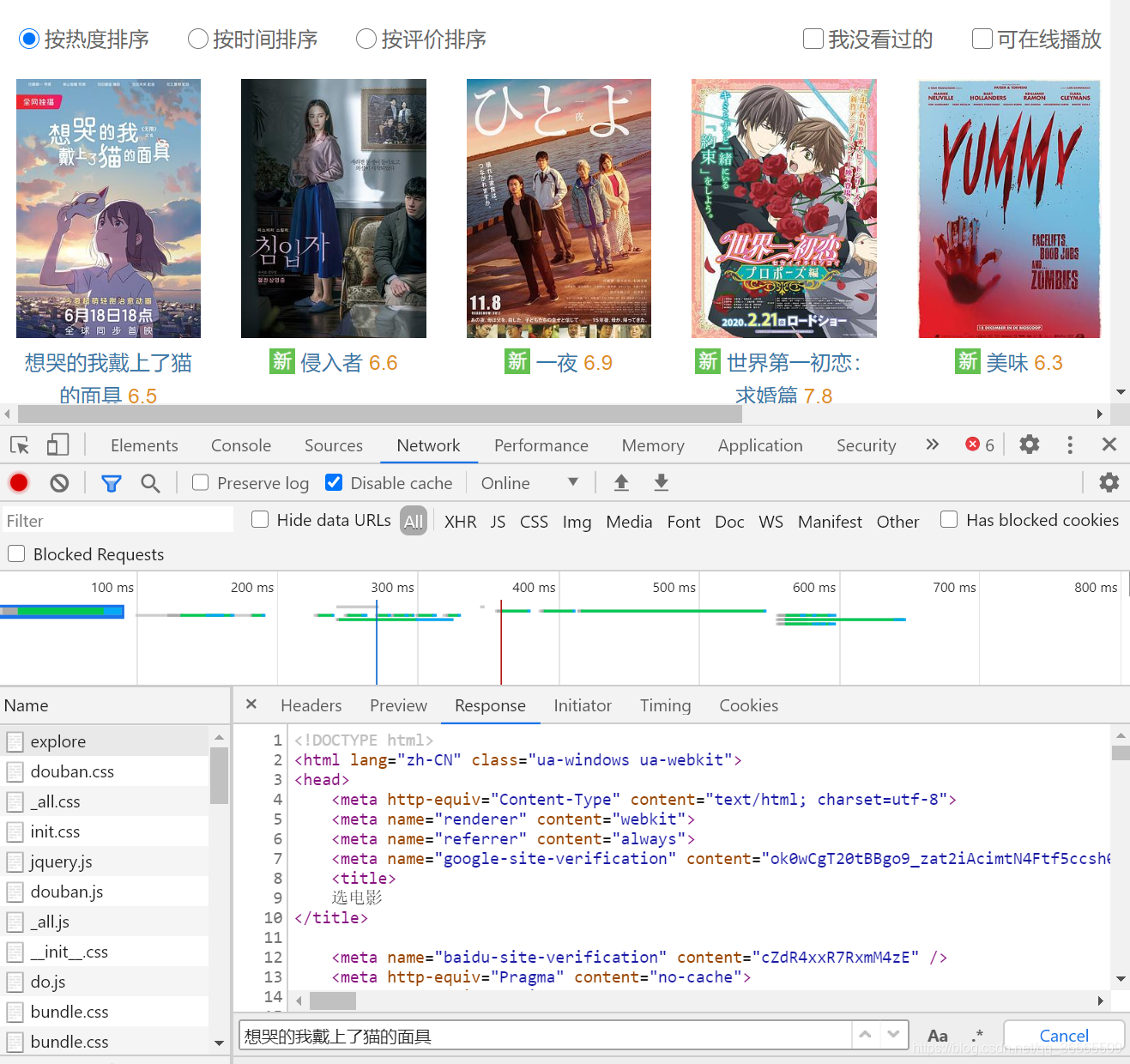
- 捕获动态加载数据
全局检索:在左侧随便点击一个包,使用快捷键Ctrl+F对所有数据包进行检索,找到包含数据的包。
检索结果 Response
{"subjects":[{"rate":"6.5","cover_x":4800,"title":"想哭的我戴上了猫的面具"...
可以得知返回的响应数据是Json格式的字符串。
查看请求信息 Headers
Request URL: https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
Request Method: GET
Query String Parameters
type: movie
tag: 热门
sort: recommend
page_limit: 20
page_start: 0
按照此方法查看其它电影可以发现通过修改参数page_limit和page_start来指定当前页面显示数量和起始位置,例如:从第5个开始获取3条数据。
target_url = 'https://movie.douban.com/j/search_subjects'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
params = {
'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '3',
'page_start': '5',
}
response_obj = requests.get(url=target_url, headers=headers, params=params)
response_dict = response_obj.json()
film_list = response_dict['subjects']
for each_file_dict in film_list:
title = each_file_dict['title']
rate = each_file_dict['rate']
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3325
3325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









