




 本文深入探讨了K近邻算法的原理与应用,包括算法的工作流程、欧氏距离计算、超参数k的选择及其对分类结果的影响。通过多个案例,如电影类型分类、鸢尾花分类、年收入预测和约会网站配对效果判定,详细展示了KNN算法在不同领域的实践。此外,还介绍了学习曲线和K折交叉验证在模型调优中的作用。
本文深入探讨了K近邻算法的原理与应用,包括算法的工作流程、欧氏距离计算、超参数k的选择及其对分类结果的影响。通过多个案例,如电影类型分类、鸢尾花分类、年收入预测和约会网站配对效果判定,详细展示了KNN算法在不同领域的实践。此外,还介绍了学习曲线和K折交叉验证在模型调优中的作用。
机器学习
1 K-近邻算法介绍
1.1 分类问题
分类问题:根据已知样本的某些特征,判断一个未知样本属于哪种样本类别。
与回归问题相比,分类问题的输出结果是离散值,用于指定输入的样本数据属于哪个类别。
1.2 K近邻算法
1.2.1 简介
K近邻(k-Nearest Neighbor,KNN)算法,是处理分类问题的基本算法之一。
KNN算法可以理解为:如果在未知类别样本附近的k个最近的样本中,大多数都属于某个类别,则这个未知样本也可以视为属于这个类别,即物以类聚,人以群分。
1.2.2 工作原理
- 给定一个训练数据集,训练数据集中的所有样本数据的类别都已知,即训练数据集中的每个数据与其所属类别的对应关系已知;
- 输入一个未知类别的实例,将输入的实例与训练数据集中的实例在特征方面进行比较;
- 根据设定的k值,取出与输入实例的特征最为相似的k个训练数据,即在特征空间中距离输入实例最近的k个训练数据;
- 对这k个训练数据进行分类统计,获取k个训练数据中出现次数最多的类别,并将这个类别视为输入实例的类别。
训练数据集是已经被正确分类的样本数据集合,每个样本数据都有表示类别的标签,因此K近邻算法属于监督学习。
1.2.3 近邻 - 欧氏距离
K近邻算法中的近邻是通过不同特征值之间的距离进行判断的,一般采用欧氏距离。
二维空间,即只考虑2个特征时
d(x,y)=(x1−y1)2+(x2−y2)2
d(x, y)=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2}
d(x,y)=(x1−y1)2+(x2−y2)2
n维空间,即考虑n个特征时
d(x,y)=(x1−y1)2+(x2−y2)2+...+(xn−yn)2=∑i=1n(xi−yi)2
d(x, y)=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+...+(x_n-y_n)^2}=\sqrt{\sum_{i=1}^n (x_i-y_i)^2}
d(x,y)=(x1−y1)2+(x2−y2)2+...+(xn−yn)2=i=1∑n(xi−yi)2
1.2.4 k值
k值用于指定KNN算法中距离输入实例最近的实例数量。
k值的大小会影响KNN算法的输出结果。
超参数
如果模型中的某些参数发生变化时,会对分类或回归的结果产生影响,则这些参数就称为模型的超参数。
k值是KNN算法模型中是超参数。
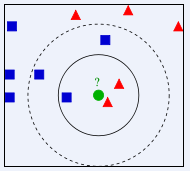
以上图为例,输入的待分类数据用绿色圆表示,已正确分类的样本数据分别用蓝色方块和红色三角表示,目标是判断绿色圆是属于蓝色方块类别还是属于红色三角类别。
- 若k=3,取距离绿色圆最近的3个样本数据,分别是2个红色三角和1个蓝色方块,因此判断绿色圆属于红色三角类别;
- 若k=5,取距离绿色圆最近的5个样本数据,分别是2个红色三角和3个蓝色方块,因此判断绿色圆属于蓝色方块类别。
2 案例
2.1 案例1 电影类型分类
数据集包含2个特征:影片出现的打斗场景次数与接吻场景次数。
目标值为电影的分类:动作片、爱情片、喜剧片等。
import pandas as pd
df = pd.read_excel('./datasets/my_films.xlsx')
df.head()
'''
名字 Action Lens Love Lens target
0 前任3 4 10 Love
1 西游记 16 2 Action
2 战狼2 18 3 Action
3 失恋33天 2 13 Love
4 宝贝计划 4 2 Comedy
'''
基于KNN算法,使用电影数据集对模型进行训练。
from sklearn.neighbors import KNeighborsClassifier
feature = df[['Action Lens', 'Love Lens']]
target = df['target']
# 实例化分类器
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(feature, target)
输入未知类型的电影数据,使用模型对其进行分类。
knn.predict([[30, 55]])
'''
array(['Love'], dtype=object)
'''
模型做出判断,一个打斗场景出现30次,接吻场景出现55次的电影属于爱情片。
2.2 案例2 鸢尾花分类
数据集使用sklearn提供的的IRIS(鸢尾花)数据集。
IRIS数据集包含4个特征:
Sepal.Length - 花萼长度
Sepal.Width - 花萼宽度
Petal.Length - 花瓣长度
Petal.Width - 花瓣宽度
特征值均为正浮点数,单位为厘米。
目标值为鸢尾花的分类,包括
Iris Setosa - 山鸢尾
Iris Versicolour - 杂色鸢尾
Iris Virginica - 维吉尼亚鸢尾
加载鸢尾花数据集。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
iris = load_iris() # 加载鸢尾花数据
feature = iris.data
target = iris.target
feature.shape # (150, 4)
将数据集拆分成训练集和测试集。
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=2020)
x_train.shape # (120, 4)
x_test.shape # (30, 4)
观察数据集,判断是否需要进行特征工程处理。
数据中各个特征的量级相差不大,不需要进行特征工程处理。
基于KNN算法,使用训练集对模型进行训练,模型中的k值设为5。
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train, y_train)
使用测试集对模型进行评估。
# 分类的正确率
knn.score(x_test, y_test) # 0.9
# 获取估计器的参数
knn.get_params()
'''
{'algorithm': 'auto',
'leaf_size': 30,
'metric': 'minkowski',
'metric_params': None,
'n_jobs': None,
'n_neighbors': 5,
'p': 2,
'weights': 'uniform'}
'''
查看模型对测试集的分类结果,并与测试集的实际分类进行比较。
print('模型的分类结果:', knn.predict(x_test))
print('实际的类别标签:', y_test)
'''
模型的分类结果: [2 0 1 1 1 1 2 1 0 0 2 1 0 2 2 0 1 1 2 0 0 2 2 0 2 1 1 1 0 0]
实际的类别标签: [2 0 1 1 1 2 2 1 0 0 2 2 0 2 2 0 1 1 2 0 0 2 1 0 2 1 1 1 0 0]
'''
2.3 案例3 预测年收入范围
import pandas as pd
df = pd.read_csv('./datasets/adults.txt')
df.head()
'''
age workclass final_weight education education_num marital_status occupation relationship race sex capital_gain capital_loss hours_per_week native_country salary
0 39 State-gov 77516 Bachelors 13 Never-married Adm-clerical Not-in-family White Male 2174 0 40 United-States <=50K
1 50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse Exec-managerial Husband White Male 0 0 13 United-States <=50K
2 38 Private 215646 HS-grad 9 Divorced Handlers-cleaners Not-in-family White Male 0 0 40 United-States <=50K
3 53 Private 234721 11th 7 Married-civ-spouse Handlers-cleaners Husband Black Male 0 0 40 United-States <=50K
4 28 Private 338409 Bachelors 13 Married-civ-spouse Prof-specialty Wife Black Female 0 0 40 Cuba <=50K
'''
2.3.1 使用one hot编码进行特征值化
提取样本数据
feature = df[['age', 'education_num', 'occupation', 'hours_per_week']]
target = df['salary']
特征工程 - 特征值化
one_hot_feature = pd.concat(
(feature[['age', 'education_num', 'hours_per_week']], pd.get_dummies(feature['occupation'])), axis=1)
特征预处理 - 标准化
from sklearn.preprocessing import StandardScaler
s_feature = StandardScaler().fit_transform(one_hot_feature)
数据集切分
x_train, x_test, y_train, y_test = train_test_split(s_feature, target, test_size=0.2, random_state=20)
训练模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=30)
knn.fit(x_train, y_train)
评估模型
knn.score(x_test, y_test) # 0.7982496545370796
2.3.2 使用自定义映射关系进行特征值化
提取样本数据
feature = df[['age', 'education_num', 'occupation', 'hours_per_week']]
target = df['salary']
自定义映射关系
cnt = 1
feature_dict = {}
for each_occupation in feature['occupation'].unique().tolist():
feature_dict[each_occupation] = cnt
cnt += 1
feature_dict
'''
{'Adm-clerical': 1,
'Exec-managerial': 2,
'Handlers-cleaners': 3,
'Prof-specialty': 4,
'Other-service': 5,
'Sales': 6,
'Craft-repair': 7,
'Transport-moving': 8,
'Farming-fishing': 9,
'Machine-op-inspct': 10,
'Tech-support': 11,
'?': 12,
'Protective-serv': 13,
'Armed-Forces': 14,
'Priv-house-serv': 15}
'''
特征工程 - 特征值化
feature['occupation'] = feature['occupation'].map(feature_dict)
feature.head()
'''
age education_num occupation hours_per_week
0 39 13 1 40
1 50 13 2 13
2 38 9 3 40
3 53 7 3 40
4 28 13 4 40
'''
数据集切分
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=20)
训练模型
knn = KNeighborsClassifier(n_neighbors=30)
knn.fit(x_train, y_train)
评估模型
knn.score(x_test, y_test) # 0.7982496545370796
查看模型对测试集的分类结果,并与测试集的实际分类进行比较。
print('模型的分类结果:', knn.predict(x_test)[0: 10])
print('实际的类别标签:', y_test[0: 10])
'''
模型的分类结果: ['>50K' '<=50K' '>50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K']
实际的类别标签:
13376 <=50K
7676 >50K
32188 <=50K
30550 <=50K
18873 >50K
21652 >50K
29911 <=50K
27398 <=50K
5757 >50K
4303 <=50K
'''
2.4 案例4 约会网站配对效果判定
import pandas as pd
df = pd.read_csv('./datasets/datingTestSet.txt', header=None, sep='\t')
df.head()
'''
0 1 2 3
0 40920 8.326976 0.953952 largeDoses
1 14488 7.153469 1.673904 smallDoses
2 26052 1.441871 0.805124 didntLike
3 75136 13.147394 0.428964 didntLike
4 38344 1.669788 0.134296 didntLike
'''
样本数据提取
feature_col = [col for col in df.columns if col != 3]
feature = df[feature_col]
target = df[3]
特征工程 - 归一化
from sklearn.preprocessing import MinMaxScaler
m_feature = MinMaxScaler().fit_transform(feature)
数据集切分
x_train, x_test, y_train, y_test = train_test_split(m_feature, target, test_size=0.2, random_state=2020)
训练模型
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(x_train,y_train)
评估模型
knn.score(x_test,y_test) # 0.7991708889912482
3 学习曲线简介
学习曲线是用于查看模型的学习效果,判断模型所处状态的一种方法,模型状态包括过拟合或欠拟合等。
使用约会网站案例的数据,通过学习曲线寻找最优的k值。
score_list = []
for k in range(1, 100):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train, y_train)
score = knn.score(x_test, y_test)
score_list.append(score)
绘制学习曲线
import matplotlib.pyplot as plt
plt.plot(range(1, 100), score_list)
plt.xlabel('k')
plt.ylabel('score')
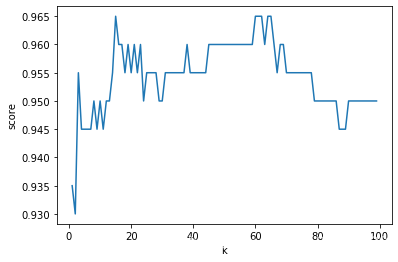
获取模型评估的准确率最高对应的k值。
import numpy as np
score_array = np.array(score_list)
np.argmax(score_array) # 14
best_k = list(range(1, 100))[np.argmax(score_array)] # 15
最优的k值为15,基于最优的k值建模并评估。
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(x_train, y_train)
knn.score(x_test, y_test) # 0.965
4 K折交叉验证
4.1 介绍
交叉验证是一种通用的模型评估方法。
主要思想是将样本数据以交叉的方式分出几组训练集和测试集,使用每组训练集和测试集训练模型并计算模型的评估结果,再取所有评估结果的平均值作为此次交叉验证的评估结果。
4.2 实现思路
- 将数据集平均分割成K等份;
- 使用一份数据作为测试数据,其余作为训练数据;
- 训练模型,评估模型,获得测试准确率;
- 选取另一份数据作为测试数据,重复步骤2和步骤3;
- 获得K个测试准确率,计算平均值。

4.3 交叉验证在KNN中的使用
from sklearn.model_selection import cross_val_score
knn = KNeighborsClassifier(n_neighbors=15)
cross_val_score(knn, x_train, y_train, cv=10)
'''
array([0.9625, 0.9375, 0.9625, 0.95, 0.9, 0.975, 0.975, 0.95, 0.925, 0.95])
'''
cross_val_score(knn, x_train, y_train, cv=10).mean()
# 0.9487499999999999
4.4 学习曲线结合K折交叉验证选取最优的k值
score_list = []
for k in range(1, 100):
knn = KNeighborsClassifier(n_neighbors=k)
cross_list = cross_val_score(knn, x_train, y_train, cv=10)
score = cross_list.mean()
score_list.append(score)
import matplotlib.pyplot as plt
plt.plot(list(range(1, 100)), score_list)
plt.xlabel('k')
plt.ylabel('score')
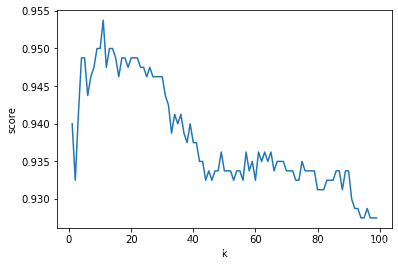
score_array = np.array(score_list)
best_k = list(range(1, 100))[np.argmax(score_array)] # 11
knn = KNeighborsClassifier(n_neighbors=best_k)
cross_val_score(knn, x_train, y_train, cv=10).mean() # 0.95375
5 综合案例 手写数字识别
5.1 准备训练集和测试集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
加载一张图片数据
img_arr = plt.imread('./digist/3/3_100.bmp')
img_arr.shape # (28, 28)
plt.imshow(img_arr)
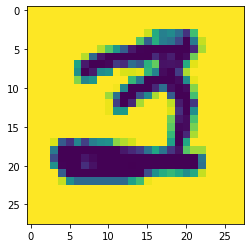
加载所有数据,将其封装成样本数据。
feature_list = []
target_list = []
for i in range(10):
for j in range(1, 501):
img_path = './digist/' + str(i) + '/' + str(i) + '_' + str(j) + '.bmp'
img_arr = plt.imread(img_path)
feature_list.append(img_arr)
target_list.append(i)
print(len(feature_list)) # 5000
print(len(target_list)) # 5000
feature_list[0].shape # (28, 28)
feature_list中每个元素的维度是2,因此feature_list的维度是3。
训练模型所需的特征数据的维度是2,因此需要对feature_list进行降维处理,将列表中每一个元素由2维转换为1维。
feature2d_list = []
for img_arr in feature_list:
feature2d_list.append(img_arr.reshape((28*28,)))
# 列表转换成numpy数组
feature = np.array(feature2d_list)
target = np.array(target_list)
拆分数据集
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.1, random_state=2020)
5.2 寻找模型最优的超参数k
score_list = []
k_list = []
for k in range(3,100):
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, x_train, y_train, cv=10).mean()
k_list.append(k)
score_list.append(score)
cross_val_score(knn, x_train, y_train, cv=10).mean() # 0.9375555555555556
best_k = k_list[np.argmax(np.array(score_list))] # 1
import matplotlib.pyplot as plt
plt.plot(list(range(1, 100)), score_list)
plt.xlabel('k')
plt.ylabel('score')
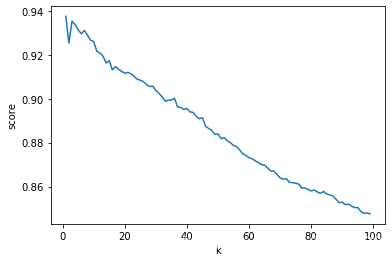
5.3 构建模型
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(x_train,y_train)
简单验证模型识别的效果。
print('验证集实际标签:', y_test[0:10])
print('模型的分类结果:', knn.predict(x_test)[0:10])
'''
验证集实际标签: [4 4 6 0 2 4 7 7 8 4]
模型的分类结果: [4 4 6 0 2 2 7 7 8 4]
'''
5.4 使用模型进行图像识别
加载图片
img_arr = plt.imread('./123.jpg')
plt.imshow(img_arr)

获取数字
five_img_arr = img_arr[300:430, 185:290]
plt.imshow(five_img_arr)

训练好的模型所能识别的图片的像素是28*28,需要对输入的图片进行等比例压缩处理。
import scipy.ndimage as ndimage
print(five_img_arr.shape) # (130, 105)
five_img_arr_zoom = ndimage.zoom(five_img_arr, zoom=(28/130, 28/105))
plt.imshow(five_img_arr_zoom)
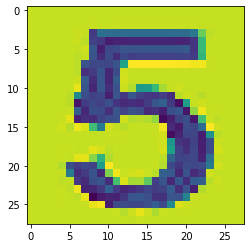
对数据进行降维处理后,即可输入到模型中进行识别。
数据集中每一行对应一条数据,因此将数据降维成(1, 28*28)。
knn.predict(five_img_arr_zoom.reshape((1, 28*28))) # array([5])

















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









