







 本文详细介绍了基于SPIN的模型检测,包括SPIN的历史、应用、特征,Promela语言的语法,如变量、进程、通道和线性时序逻辑LTL。此外,还阐述了SPIN环境的安装步骤,如下载、安装cygwin、ActiveTcl和graphviz。文章还探讨了SPIN和ISPIN的功能,如LTL转换、代码检查和模型检测验证。最后,通过实际例子展示了如何利用SPIN进行模型检测,如互斥协议检验、通道消息传递和领导者选举算法。
本文详细介绍了基于SPIN的模型检测,包括SPIN的历史、应用、特征,Promela语言的语法,如变量、进程、通道和线性时序逻辑LTL。此外,还阐述了SPIN环境的安装步骤,如下载、安装cygwin、ActiveTcl和graphviz。文章还探讨了SPIN和ISPIN的功能,如LTL转换、代码检查和模型检测验证。最后,通过实际例子展示了如何利用SPIN进行模型检测,如互斥协议检验、通道消息传递和领导者选举算法。
本博客主要讲述基于SPIN的模型检测的内容,转载请声明出处!
目录
4.1 SPIN关于线性时序逻辑 LTL 及其到自动机的转换
一、SPIN概述
1.1 SPIN的历史背景
SPIN(Simple Promela Interpreter)是适合于并行系统,尤其是协议一致性的辅助分析检测工具,由贝尔实验室的形式化方法与验证小组于1980年开始开发的pan就是现在SPIN的前身。1989年SPIN的0版本推出主要用于检测一系列的ω-regular属性。1995年偏序简约和线性时序逻辑转换的引入使得SPIN的功能进一步扩大。2001年推出的SPIN4.0版本支持C代码的植入,应用的灵活性进一步增强。
在随后2003年推出的SPIN4.1版本加入了深度优先搜索算法,更是使得SPIN的发展上了一个新台阶。
1.2 SPIN的应用
NASA 使用SPIN检测早在1996年火星探测者所存在的错误,结果发现一些错误是可以在发射之前就可以被改正的。SPIN从此就被用来检测土星火箭控制软件和一些应用与外层空间的程序。
Lucent公司也发现了SPIN 的优点,PathStar Access Server是受益于Holzmann(SPIN开发者)的工作的第一个Lucent 产品,Holzmann用SPIN 检测了5ESS Switch的新版本代码,这个软件现在用于Lucent的灵活性部分来改善软件测试的过程。
SPIN良好的算法设计和非凡的检测能力得到了ACM(Association for Computing Machinery)(世界最早的专业计算机协会)的认可,在2001年授予SPIN的开发者Holzmann享有声望的软件系统奖。
迄今为止SPIN也是唯一获得ACM软件系统奖的模型检测工具。
1.3 SPIN的特征
SPIN验证主要关心的问题是进程之间的信息能否正确的交互,而不是进程内部的具体计算。SPIN是一个基于计算机科学的“形式化方法”,将先进的理论验证方法应用于大型复杂的软件系统当中的模型检测工具。如今SPIN被广泛的应用于工业界和学术界。其特点如下:
1.SPIN以Promela为输入语言,可以对网络协议设计中的规格的逻辑一致性进行检验,并报告系统中出现的死锁、无效的循环、未定义的接收和标记不完全等情况。
2.SPIN使用on-the-fly技术,即无需构建一个全局的状态图或者Kripke结构,而可以根据需要生成系统自动机的部分状态。
3.SPIN可当做一个完整的LTL(Linear Temporal Logic)模型检验系统来使用,支持所有的可用的线性时态逻辑表示的正确性验证要求,也可以在有效的on-the-fly检验系统中用来检验协议的安全特征。
4.SPIN可通过使用会面点来进行同步通信,也可以使用缓冲通道来进行异步通信。
5.对于给定的一个使用Promela描述的协议系统,SPIN可以对其执行随意的模拟,也可以生成一个C代码程序,然后对该系统的正确性进行有效的检验。
6.在进行检验时,对于中小规模的模型,可以采用穷举状态空间分析,而对于较大规模的系统,则采用Bit State Hashing方法来有选择地搜索部分状态空间。
1.4基于SPIN的协议分析
用SPIN对协议进行模拟分析,来确定协议的正确性。正确性是指:不存在违背断言(assertion)的情况、不存在死锁(deadlock)、不存在“坏的”循环、 满足我们定义的LTL公式。在SPIN/Promela模型中主要由:断言(assertion),特殊的标记和never claims三种方式来实现。
一个“断言”(assert语句)是一个逻辑表达式。它可以出现在所描述的模型中的任何位置,并在任何时候都是可以执行的。它相当于指定系统的一个“不变式”,无论什么时候这个表达式的值都应为真。在SPIN执行assert语句时,如果该语句所指定的条件成立(表达式的值不为0),则不产生任何影响;但如果条件不成立(表达式的值为0),将产生一个错误报告。在Peomela模型中经常使用assert语句来检验在某状态时某个性质是否成立。
死锁(deadlock)是系统运行到某个状态后不能再转向其它任何一个状态。在SPIN验证过程中如果出现死锁情况,验证器将会给出“invalid end state”提示语句。要验证Promela所描述的一个系统是否存在死锁,验证器就要能够将正确的结束状态和异常的结束状态区别开来。在一个执行序列结束时,最好是所有的进程的实例都运行到了其相应进程体的最后,并且所有的消息通道都为空。然而有的时候,并不一定要求所有的进程都到达了它们进程体的最后才能说明不存在死锁,其中有的进程可能会停留在空闲状态,也可能会在某些状态循环,等待某个消息的到来后再进行其他操作。为此,在建模的过程中可以用“end”标记来标识正确的结束状态。
一个“坏”的循环是指系统不断重复执行一些错的或是没有意义的行为。建模过程中可以设置“accept”标记(主要用于never 声明中),然后指定验证器找出所有至少执行过一次此标记语句的循环,如果这样的循环不存在则说明系统是正确的。也可以设置“progress”来标记一些必须要不断重复被执行的语句,如果存在没有经过“progress”的循环,则说明有“坏”的循环存在。
一个线性时序逻辑公式可以表达比“从不发生”或“总是发生”或“不断的发生”这些属性更复杂的系统要求。比如,系统要求满足 “事件P发生则能得到事件Q也发生了”这个规范约束条件,这时就可以用线性时序逻辑公式[](P->Q)来检测看你的系统是否能够满足这个条件。SPIN 提供了将线性时序逻辑公式翻译为相应的never claims的功能,使用起来相当的方便。
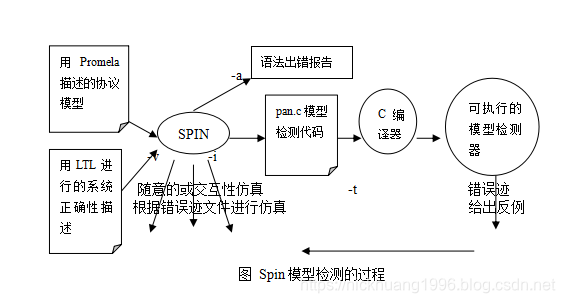
1.5 SPIN检测的基本过程
SPIN可以用在三个基础模型中:
1) 作为一个模拟器,允许快速对建立的系统模型进行随意的、引导性的或交互的仿真。
2) 可以作为一个详尽的分析器,严格的证明用户提出的正确性要求是否满足(使用偏序简约进行最优化检索)。
3) 用于大型系统近似性证明,用SPIN可以对大型的协议系统进行有效的正确性分析,即使这个系统覆盖了最大限度的状态空间。
SPIN首先从一个描述的协议系统的高层模型规格开始,经分析没有语法错误后,对系统的交互进行模拟,直到确认系统设计拥有预期的行为;然后,SPIN将产生一个用C语言描述的验证程序,经检验器编译后被执行,执行中如果发现了违背正确性说明的任何反例,则可反馈给交互模拟机,通过重现细节剔除引起错误的原因。
下图描述了整个的检测过程:
二、Promela语言
2.1 Promela简介
Promela语言是描述并发系统(concurrent systems)的一种模型语言(modelling language),而不是通常意义下的程序语言(Programming Language)。
Promela(Protocol/Meta Language)是用来对有限状态系统进行建模的形式描述语言。他类似于C程序语言,允许动态创建并行的进程,并可以在进程之间通过消息通道进行同步(使用会面点(rendezvous port)和异步(使用缓冲)进行通信。
其大体结构如下:
mtype={MSG,ACK}; /*类型说明*/
chan toS=… /*通道说明*/
chan toR=…
bool flag; /*变量说明*/
proctype Sender(){ /*进程说明*/
… /*进程体*/
}
proctype Receiver(){
…
}
init{
… /*初始进程*/
run Sender();
run Receiver(); /*创建进程实例*/
…
}2.2变量和数据类型
(1)基本的数据类型:
Promela中的基本的数据类型是下述五种:bit,bool,byte,short,int。
bit和bool表示同样的单比特信息,可以取值为0或1;byte可以为0~255的无符号数;short,int为有符号数值,它们的区别在于所表示的值的范围不同,short 范围为(-2^15)~(2^15-1),int的取值范围为(-2^31~2^31-1),系统默认基本数据类型的初始值为0。
(2)数组:
数组的定义和C语言的一样,如:byte state[5],表示定义了一个含有5个元素的字节型数组state[0]~state[4]。
(3)枚举类型:
mtype={one, two, three},它相当于下面三条语句:
#define one 1;
#define two 2;
#define three 3;一个枚举类型mtype(message type)最多可以包含255个常量。
(4)结构:
结构的定义和C的也是类似的,如:
typedef Msg {
byte a[3], b;
chan p;
}
Msg x; 如果x=[0,7,2],5,queue ,则x.a[1] =7 ,x.b = 5 ,x.p就是通道queue。
2.3进程
一个进程的说明以关键词proctype开始,主要由以下几个部分组成:进程名、形式参数列表、局部变量说明、进程体。一个进程说明可以对应多个进程实例,进程实例可以在任何进程中使用run语句创建,同时将返回该进程的id。
在Promela语言所描述的系统中,init进程类似于标准C程序中的main()函数,所以最小系统可以是
init{skip}这里的skip是一个空语句。还有一个典型的“Hello World”程序在Promela中可描述为:
init{printf(“Hello World\n”)}进程实例的创建还可以用在proctype前加上关键词 active来实现,如:
active [3] proctype Bar(){…}就是创建3个Bar进程实例,这时进程不能带参数。
进程体中的语句要么被执行(当判断条件满足时),要么被阻塞(当判断条件满足时)。一个进程可以和其他进程并行执行,并通过全局变量或通道相互通信。进程间并行执行时的相对速度是随机的。
例如考虑下面包含两个进程的系统,这两个进程共享访问全局变量state。
byte state=1;
proctype A(){(state==1)->state=state+1}
proctype B(){(state==1)->state=state-1}
init{run A();runB()}在这两个进程中,如果其中一个进程在另一个进程开始之前就已经结束了,则另一个进程将在其初始条件处永远被阻塞;如果两个进程都同时通过条件,则两者都能结束,但最终state的值是不可预测的,它可能的值有0,1,2。
为了避免在进程并行中相对速度的不确定性带来的影响,在Promela中可使用原子序列。当一串语句用“{}”括起来,并以关键词atomic作为前缀时,表示该语句序列将作为一个不可分割的整体来执行,并且不被其他任何进程所影响。例如,将刚才的例子改写为:
byte state=1;
proctype A(){atomic{(state==1)->state=state+1}}
proctype B(){atomic{(state==1)->state=state-1}}
init{run A();runB()}这时state的最终值将为0或2,具体值取决于哪一个进程先执行,同时另一个进程将被永远阻塞。
因此,使用原子序列atomic可以显著地降低验证模型的复杂性。
2.4通道与消息传递
(1)Promela模型中进程间可以使用消息通道(chan)来进行通信。通道是按先进先出(FIFO: first in first out)的顺序来传递消息。
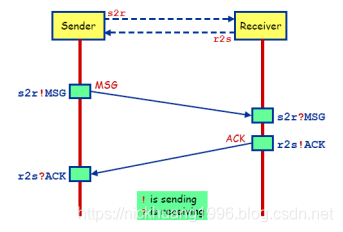
(2)通道分会面点通道(握手)与缓冲通道两种。按先进先出(FIFO: first in first out)的顺序来传递消息。定义通道和定义基本的数据类型一样,定义格式如下:
chan <name>=[<dim>] of {<t1>,<t2>,…<tn>};参数name是通道的名称,<dim>是通道所能容纳的消息的个数(最多为255个)<t1>,<t2>,…<tn>是通道要传递的数据类型。
例如:
chan a,b; chan c[3]定义了a,b,c三个通道,其中c是一个通道数组。
(3)
chan qname=[16] of {short}表示该通道可存储16个short类型的消息。如果通道所传递的消息有多个消息域,则其说明可能如下:
chan qname=[16] of {byte,int,chan,byte} 定义的通道可存储16条消息,其中每个消息又由4个域组成。
(4)定义完通道以后就可以进行消息的传递。
①在Promela中用“!”来表示向一个通道送入数据:
ch!<expr1>,<expr2>,…<exprn>; 表达式<expri>的数据类型要和通道声明时的数据类型相一致。只有在通道不满的时候,向通道送入信息的这个语句才会被执行。例如,语句
qname!exp1,exp2的意思是将表达式exp1和exp2的值发给通道qname,该值将挂到通道的尾部。
②相应的,用“?”来表示从一个通道中取出信息:
ch?<var1>,<var2>,…<varn>;如果通道不为空,则将信息从通道中取出并将值赋给相对应的变量<vari>。像这样使用完全是信息的传递。如,语句
qname?msg的意思是从通道的头部取出一个消息,并将值赋给变量msg。
(5)还有一种是用做判断的:
ch?<const1>,<const2>,…<constn>;当通道不为空,并且在通道中的消息的值和相应的<consti>值相等时,此语句被执行,并将相应的消息从通道中移出。
2.5线性时序逻辑 LTL 及其到自动机的转换
线性时序逻辑LTL是一种形式化符号,能描述系统在执行路径上的性质,还可以表示系统的安全性、 活性等。一个 LTL 公式由原子命题 p 和一元、二元、布尔、时序运算符的组合而成。其语法如下:
f ::= p
|true
|false
|(f)
|f binop f
| unop f
unop ::= [] (总是)
| <> (有时)
| ! (逻辑非)
binop ::= U (直到)
| && (逻辑与)
| || (逻辑或)
| -> (实现)
| <-> (等 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











