







1.DataX安装
1.1上传并解压安装包
cd /opt/module/software
[root@hadoop001 software]# tar -zxvf datax.tar.gz -C /opt/module/
1.2执行自检脚本
cd /opt/module/datax/bin
[root@hadoop001 bin]# python datax.py ../job/job.json
2.DataX使用案例
2.1从stream流读取数据打印到控制台
2.1从stream流读取数据打印到控制台
第一步:创建job的配置文件模板(JSON格式),查看输出结果
[root@hadoop001 bin]# python datax.py -r streamreader -w streamwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
第二步:根据模板编写配置文件
cd /opt/module/datax/job
vim stream2stream.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": "10",
"column": [
{
"type":"long",
"value":"10"
},
{
"type":"string",
"value":"你好,datax!"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "5",
"bytes":"0"
},
"errorLimit":{
"record":"10",
"percentage":"0.02"
}
}
}
}
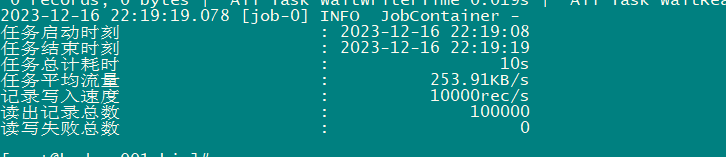
第三步:启动datax并观察输出结果
[root@hadoop001 job]# python ../bin/datax.py stream2stream.json

2.2从mysql数据库读取表数据打印到控制台
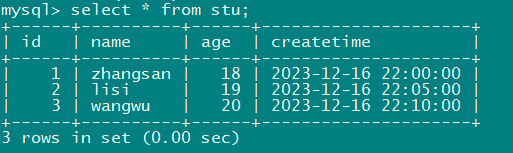
第一步:mysql创建数据库和表
mysql> create database datax;
Query OK, 1 row affected (0.00 sec)
mysql> use datax;
Database changed
create table stu(id int,name varchar(20),age int,createtime timestamp);
insert into stu values('1','zhangsan','18','2023-12-16 22:00:00');
insert into stu values('2','lisi','19','2023-12-16 22:05:00');
insert into stu values('3','wangwu','20','2023-12-16 22:10:00');
第二步:创建配置文件模板
[root@hadoop001 bin]# python datax.py -r mysqlreader -w streamwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
第三步:根据模板编写配置文件
cd /opt/module/datax/job
vim mysql2stream.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"age"
"createtime"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hadoop002:3306/datax"],
"table": ["stu"]
}
],
"password": "mysql",
"username": "root"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "3"
},
"errorLimit":{
"record":0,
"percentage":0.02
}
}
}
}
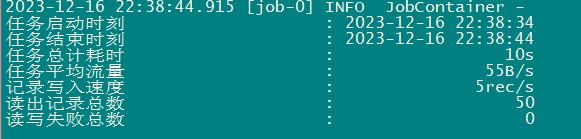
第四步:启动datax,观察输出结果
[root@hadoop001 job]# python ../bin/datax.py mysql2stream.json

2.3从mysql数据库读取表增量数据打印到控制台
第一步:编写配置文件
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"age"
"createtime"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hadoop002:3306/datax"],
"table": ["stu"]
}
],
"password": "mysql",
"username": "root",
"where":"createtime > '${start_time}' and createtime < '${end_time}'"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "3"
},
"errorLimit":{
"record":0,
"percentage":0.02
}
}
}
}
第二步:向stu表中插入一条数据
insert into stu values('3','wangwu','20','2023-12-15 23:10:00');
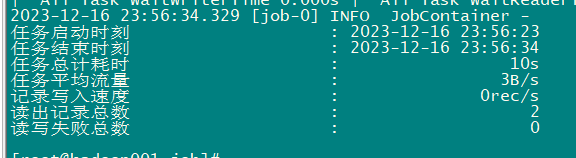
第三步:启动datax并观察输出
[root@hadoop001 job]# python ../bin/datax.py mysqlAdd2stream.json -p "-Dstart_time='2023-12-15 00:00:00' -Dend_time='2023-12-15 23:59:59'"

2.4使用datax实现mysql to mysql
第一步:创建配置文件模板
[root@hadoop001 job]# python ../bin/datax.py -r mysqlreader -w mysqlwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the mysqlwriter document:
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
第二步:根据模板编写配置文件
vim mysql2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hadoop002:3306/datax"],
"querySql":["select id,name,age,createtime from stu where age > 19;"]
}
],
"password": "mysql",
"username": "root",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name",
"age",
"createtime"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop002:3306/datax",
"table": ["person"]
}
],
"password": "mysql",
"preSql": ["delete from person"],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
第三步:创建目标表
mysql> create table person as stu;
第四步:启动datax,查询person表数据
[root@hadoop001 job]# python ../bin/datax.py mysql2mysql.json
select * from person;
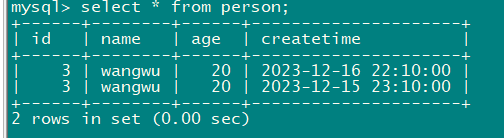
2.5将数据从mysql导入到hdfs
第一步:创建配置文件模板
[root@hadoop001 job]# python ../bin/datax.py -r mysqlreader -w hdfswriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the hdfswriter document:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
第二步:编写配置文件
vim mysql2hdfs.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hadoop002:3306/datax"],
"querySql":["select id,name,age,createtime from stu where age < 20;"]
}
],
"password": "mysql",
"username": "root",
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"id",
"type":"int"},
{"name":"name",
"type":"string"},
{"name":"age",
"type":"int"},
{"name":"createtime",
"type":"timestamp"},
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop002:9000",
"fieldDelimiter": "\t",
"fileName": "stu.txt",
"fileType": "text",
"path": "/datax/mysql2hdfs/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
第三步:hdfs创建对应路径
[root@hadoop001 job]# hdfs dfs -mkdir -p /datax/mysql2hdfs/
第四步:启动datax,查看hdfs文件是否存在
[root@hadoop001 job]# python ../bin/datax.py mysql2hdfs.json
hdfs dfs -ls /datax/mysql2hdfs

2.6将hdfs数据导入到mysql表
第一步:创建配置文件模板
[root@hadoop001 job]# python ../bin/datax.py -r hdfsreader -w mysqlwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the hdfsreader document:
https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md
Please refer to the mysqlwriter document:
https://github.com/alibaba/DataX/blob/master/mysqlwriter/doc/mysqlwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [],
"defaultFS": "",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileType": "orc",
"path": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
第二步:根据模板编写配置文件
vim hdfs2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
{
"index":0,
"type":"long"
},
{
"index":1,
"type":"string"
},
{
"index":2,
"type":"long"
},
],
"defaultFS": "hdfs://hadoop002:9000",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"fileType": "text",
"path": "/user.txt"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name",
"age"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop002:3306/datax",
"table": ["user"]
}
],
"password": "mysql",
"preSql": ["delete from user"],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
第三步:准备数据并上传到hdfs
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 35
5 maqi 40
hdfs dfs -put user.txt /
第四步:创建目标表
create table user(id int,name varchar(20),age int);
第五步:启动datax,查询目标表
[root@hadoop001 job]# python ../bin/datax.py hdfs2mysql.json
select * from user;
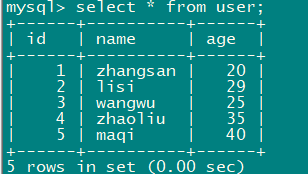
2.7mysql表同步数据到hive表中
第一步:创建hive表
[root@hadoop001 module]# hiveserver2
[root@hadoop001 ~]# beeline
beeline> !connect jdbc:hive2://hadoop002:10000
0: jdbc:hive2://hadoop002:10000> create external table ext_user(id int,name string,age int) row format delimited fields terminated by '\t';
第二步:编写配置文件
vim mysql2hive.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column":["id","name","age"]
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hadoop002:3306/datax"],
"table":["user"],
}
],
"password": "mysql",
"username": "root",
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"id",
"type":"int"},
{"name":"name",
"type":"string"},
{"name":"age",
"type":"int"}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop002:9000",
"fieldDelimiter": "\t",
"fileName": "user.txt",
"fileType": "text",
"path": "/user/hive/warehouse/datax.db/ext_user",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
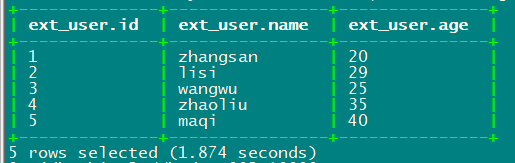
第三步:启动Datax,hive查询ext_user表数据
[root@hadoop001 job]# python ../bin/datax.py mysql2hive.json
0: jdbc:hive2://hadoop002:10000> select * from ext_user;

















 7217
7217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









