




 本文介绍了如何在Spark Streaming中整合Kafka,包括receiver方式和直接使用Direct方式,讨论了两种方式的优缺点。同时,文章涵盖了胖包和瘦包的打包上传方法,并详细讲解了操作Zookeeper的两种方式,包括使用Curator与Zookeeper交互的示例代码。
本文介绍了如何在Spark Streaming中整合Kafka,包括receiver方式和直接使用Direct方式,讨论了两种方式的优缺点。同时,文章涵盖了胖包和瘦包的打包上传方法,并详细讲解了操作Zookeeper的两种方式,包括使用Curator与Zookeeper交互的示例代码。
文章目录
测试kafka正常工作
[hadoop@hadoop000 kafka]$ bin/kafka-topics.sh \
> --create \
> --zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka \
> --replication-factor 1 --partitions 1 --topic ruozeg5sparkkafka
[hadoop@hadoop000 kafka]$ bin/kafka-console-producer.sh \
> --broker-list 192.168.137.190:9092,192.168.137.190:9093,192.168.137.190:9094 \> --topic ruozeg5sparkkafka
[hadoop@hadoop000 kafka]$ bin/kafka-console-consumer.sh \
> --zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka \
> --topic ruozeg5sparkkafka --from-beginning
streaming整合kafka idea
有两种方式写的方式,一种是receiver的,一种是没有receiver的
receiver要0.8之前才行

添加dependency
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
receiver的代码
package com.ruozedata.bigdata.streaming04
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object ReceiverKafkaApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("ReceiverKafkaApp")
val ssc = new StreamingContext(conf,Seconds(10))
val topic ="ruozeg5sparkkafka"
//注意kafka分区和partition分区无关
val numPartitions=1
val zkQuorum="192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka"
var groupId="test_g5"
//元祖转map
val topics =topic.split(",").map((_,numPartitions)).toMap
//返回个receiver,带有kafka keyvalue的DStream
val messages = KafkaUtils.createStream(ssc,zkQuorum,groupId,topics)
//第一列是null
messages.map(_._2)
.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
receive方式注意的点

1.在Receiver的方式中,Spark中的partition和kafka中的partition并不是相关的,所以如果我们加大每个topic的partition数量,仅仅是增加线程来处理由单一Receiver消费的主题。但是这并没有增加Spark在处理数据上的并行度。
2.对于不同的Group和topic我们可以使用多个Receiver创建不同的Dstream来并行接收数据,之后可以利用union来统一成一个Dstream。
3.如果我们启用了Write Ahead Logs复制到文件系统如HDFS,那么storage level需要设置成 StorageLevel.MEMORY_AND_DISK_SER,也就是KafkaUtils.createStream(…, StorageLevel.MEMORY_AND_DISK_SER),因为hdfs自动会有3个副本,不需要这里再设置副本。
打包上传,胖包瘦包
胖包:打包的时候就把依赖打进去
瘦包:不把依赖打进去
正常打包不带依赖,脚本比较麻烦
[hadoop@hadoop000 data]$ cat kafka_receiver.sh
$SPARK_HOME/bin/spark-submit \
--master local[2] \
--class com.ruozedata.bigdata.streaming04.ReceiverKafkaApp \
--name ReceiverKafkaApp \
--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.4.0 \
/home/hadoop/data/g5-spark-1.0.jar
还要改下权限
[hadoop@hadoop000 data]$ chmod u+x kafka_receiver.sh
瘦包方式
要把这几个pom改成provided,这样就是瘦包
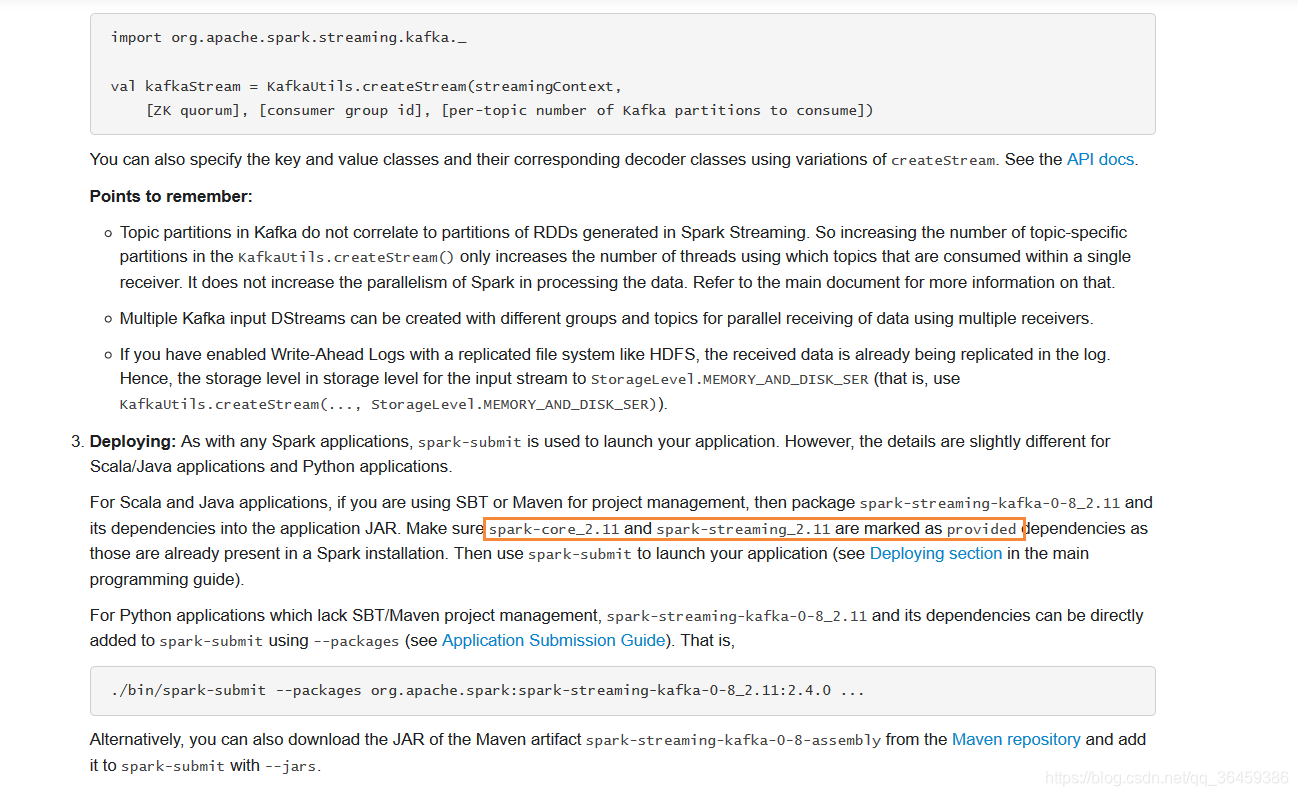
添加下面的
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
改成provided的就是不需要打进包里的,使用系统的
下面举例
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
</dependency>
最后会同时生成一个带自定义后缀的文件
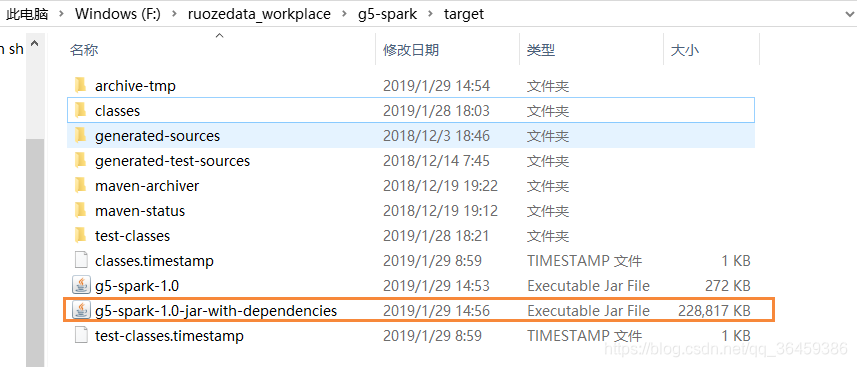
瘦包脚本
[hadoop@hadoop000 data]$ cat kafka_receiver_dep.sh
$SPARK_HOME/bin/spark-submit \
--master local[2] \
--class com.ruozedata.bigdata.streaming04.ReceiverKafkaApp \
--name ReceiverKafkaApp \
/home/hadoop/data/g5-spark-1.0-jar-with-dependencies.jar
开启生产者输入数据测试成功
[hadoop@hadoop000 kafka]$ bin/kafka-console-producer.sh \
> --broker-list 192.168.137.190:9092,192.168.137.190:9093,192.168.137.190:9094 \--topic ruozeg5sparkkafka
直接上传不带receiver
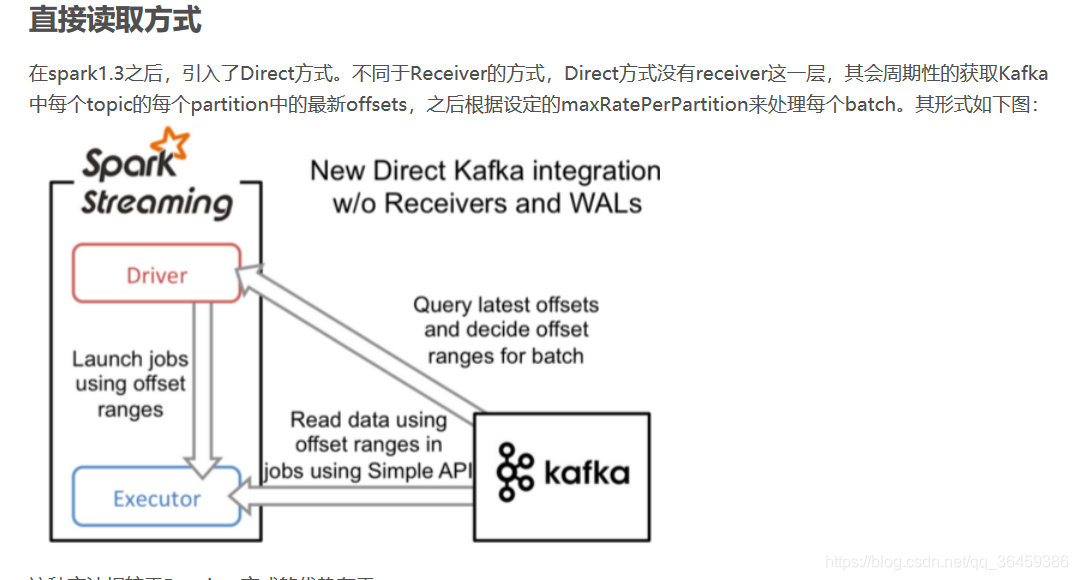
这种在Spark-1.3引出的新的不基于Receriver的"Direct"方式确保更强大的端对端保证。跟过去的基于Receiver接收数据相比,这种新的方式周期性的查询kafka中的每个partition的最新offset偏移范围。通过这个offset范围来指定这个时间段内批次数据的范围。当对应的处理这个批次数据的task启动起来的时候,默认会使用Kafka’s simple Consumer API来按照这个offset范围读取数据。
代码
package com.ruozedata.bigdata.streaming04
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectKafkaApp {
def main(args: Array[String]) {
// 准备工作
val conf = new SparkConf().setMaster("local[2]").setAppName("DirectKafkaApp")
val ssc = new StreamingContext(conf, Seconds(10))
val topic = "ruozeg5sparkkafka"
val kafkaParams = Map[String, String]("metadata.broker.list"->"hadoop000:9092","metadata.broker.list"->"hadoop000:9093","metadata.broker.list"->"hadoop000:9094")
val topics = topic.split(",").toSet
//[]里是[key class], [value class], [key decoder(解码) class], [value decoder class] ]
//(streamingContext, [map of Kafka parameters], [set of topics to consume])
val messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams, topics)
messages.map(_._2) // 取出value
.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}
1.简化的并行:在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
2.高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
3.精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
4.这种方式也有一个缺点,就是基于zookeeper的kafka管理工具,将不显示topic的消费进度,也不更新Zookeeper上的偏移量。然而,用户可以手动自己保存topic的每个partition的offset到zookeeper中。
Receiver的方式,是从Zookeeper中读取offset值,那么自然zookeeper就保存了当前消费的offset值,那么如果重新启动开始消费就会接着上一次offset值继续消费。而在Direct的方式中,我们是直接从kafka来读数据,那么offset需要自己记录,可以利用checkpoint、数据库或文件记录或者回写到zookeeper中进行记录。
操作Zookeeper
添加依赖
<zk.version>3.4.5-cdh5.7.0</zk.version>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>${zk.version}</version>
</dependency>
有两种写法,第二种写法是生产用的
第一种方式
与Zookeeper连接的代码模板
package com.ruozedata.bigdata.zk;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.swing.plaf.TableHeaderUI;
import java.util.concurrent.CountDownLatch;
public class ZKConnectApp implements Watcher {
private static Logger logger = LoggerFactory.getLogger(ZKConnectApp.class);
private static CountDownLatch connected = new CountDownLatch(1);
public static void main(String[] args) throws Exception {
ZooKeeper zooKeeper = new ZooKeeper("192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka", 5000, new ZKConnectApp());
System.out.println("客户端开始连接ZK Server...");
System.out.print(zooKeeper.getState());
// logger.warn("客户端开始连接ZK Server...");
// logger.warn("连接状况:{}", zooKeeper.getState());
// Thread.sleep(3000);
//0时继续执行下面的
connected.await();
System.out.print(zooKeeper.getState());
}
//Watcher的方法
public void process(WatchedEvent watchedEvent) {
//如果连接上了
if (Event.KeeperState.SyncConnected == watchedEvent.getState()) {
System.out.println(watchedEvent);
//减1,1-1=0
connected.countDown();
}
}
}
套用上面模板可以完善下面的代码
package com.ruozedata.bigdata.zk;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
public class ZKCreateNodeApp implements Watcher{
private static Logger logger = LoggerFactory.getLogger(ZKConnectApp.class);
public static void main(String[] args) throws Exception{
ZooKeeper zooKeeper = new ZooKeeper("192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka", 5000, new ZKConnectApp());
Thread.sleep(2000);
String path = zooKeeper.create("/g5_zk_test01", "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// logger.warn("成功创建节点:{}", path);
// System.out.println(path);
// Stat stat = zooKeeper.setData("/g5_zk_test01","ruozedata".getBytes(),-1);
// logger.warn("version:{}", stat.getVersion());
// byte[] data = zooKeeper.getData("/g5_zk_test01", true, new Stat());
// logger.warn("data:{}", new String(data));
// Stat stat = zooKeeper.exists("/g5_zk33333_test01", true);
// logger.warn("exist:{}", stat!=null);
// List<String> children = zooKeeper.getChildren("/g5_zk_test01", true);
// for(String child : children) {
// logger.warn(child);
// }
//zooKeeper.delete("/g5_zk_test01",-1);
}
public void process(WatchedEvent watchedEvent) {
}
}
查看Zookeeper
运行前
[hadoop@hadoop000 bin]$ ./zkCli.sh
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper, kafka]
[zk: localhost:2181(CONNECTED) 2] ls /kafka
[cluster, controller_epoch, controller, brokers, admin, isr_change_notification, consumers, config]
运行后
[zk: localhost:2181(CONNECTED) 4] ls /kafka
[cluster, controller_epoch, controller, brokers, g5_zk_test01, admin, isr_change_notification, consumers, config]
[zk: localhost:2181(CONNECTED) 6] get /kafka/g5_zk_test01
cZxid = 0x2b00000048
ctime = Tue Jan 29 17:49:15 CST 2019
mZxid = 0x2b00000048
mtime = Tue Jan 29 17:49:15 CST 2019
pZxid = 0x2b00000048
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
第二种方式:Curator
添加依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
代码
package com.ruozedata.bigdata.zk;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.ZooDefs;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
*
@BeforeClass 全局只会执行一次,而且是第一个运行
@Before 在测试方法运行之前运行
@Test 测试方法
@After 在测试方法运行之后允许
@AfterClass 全局只会执行一次,而且是最后一个运行
@Ignore 忽略此方法
*/
public class CuratorApp {
CuratorFramework client = null;
@Test
public void testCreateNode() throws Exception{
//创建节点,没有父节点就创建
//持久化节点,瞬时节点session过了就看不到了
//最后的结果于在g5/huahua 的数据有 你爱花花吗?
client.create().creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT)
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
.forPath("/huahua","你爱花花吗?".getBytes());
}
@Test
public void testSetData() throws Exception {
client.setData().withVersion(0).forPath("/huahua","你爱花花吗?1111".getBytes());
}
@Before
public void setUp(){
//namespace就是zookeeper的一个目录,前面会自动拼个/,即/g5
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 5);
client = CuratorFrameworkFactory.builder().connectString("192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka")
.sessionTimeoutMs(20000).retryPolicy(retryPolicy)
.namespace("g5").build();
client.start();
}
@After
public void tearDown(){
client.close();
}
}
结果
[zk: localhost:2181(CONNECTED) 11] get /kafka/g5/huahua
你爱花花吗?1111
cZxid = 0x2b0000004f
ctime = Tue Jan 29 18:41:02 CST 2019
mZxid = 0x2b00000052
mtime = Tue Jan 29 18:41:02 CST 2019
pZxid = 0x2b0000004f
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 20
numChildren = 0
curator
https://www.cnblogs.com/sigm/p/6749228.html
http://blog.51cto.com/zero01/2109137
streaming kafka
https://blog.youkuaiyun.com/cql252283126/article/details/79926228

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









