




文章目录
hbase是啥
hadoop的大数据存储库,适合随机实时读取大数据量。
HBase vs RDBMS
列式存储方式
缺少SQL
分布式:可扩展性
KV存储
支持的列多
表之间耦合性低(解耦)(大宽表)
支持大数据量
存在冗余 (数据更新不会overwrite,而是增加,会有版本)
查询性能高
数据类型(只有Bytes类型)
null不存储
二级索引不支持
trigger不支持
HBase基本术语
Table -> N * rows
row: rowkey(rk):[一行数据的唯一标识]
column family(cf):[一行数据同属一个cf, table-> N * cf, cf-> N * col, 多行数据可以有不同col]
cell:[rk, cf:col, version]
timestamp: [ts肯定在version数据内的 ts <= count(vesion)]
eg: row => row1 column=f1:a, timestamp=1550349258503, value=value1, version
hbase shell
start-hbase.sh
http://hadoop000:16010/master-status
hbase shell
hbase架构
https://mapr.com/blog/in-depth-look-hbase-architecture/
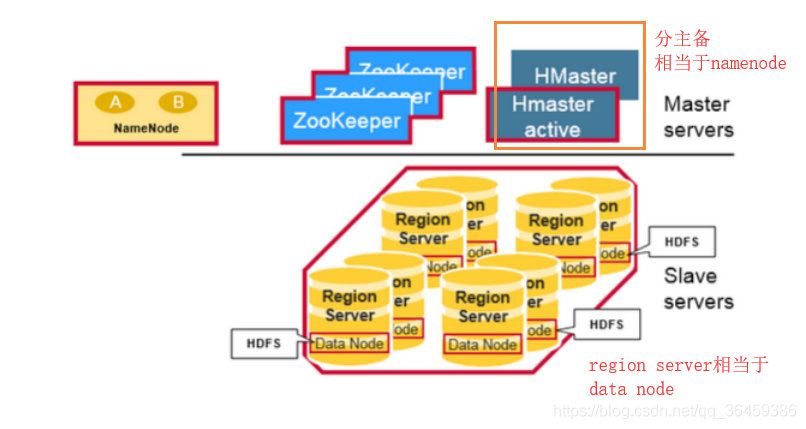
HBase架构也是主从架构,由三部分构成HRegionServer、HBase Master和ZooKeeper。
RegionServer负责数据的读写与客户端交互,对于region的操作则是由HMaster处理,ZooKeeper则是负责维护运行中的节点。
在底层,它将数据存储于HDFS文件中,因而涉及到HDFS的NN、DN等。RegionServer会搭配HDFS中的DataNode节点,可以将数据放在本节点的DataNode上。NameNode则是维护每个物理数据块的元数据信息。
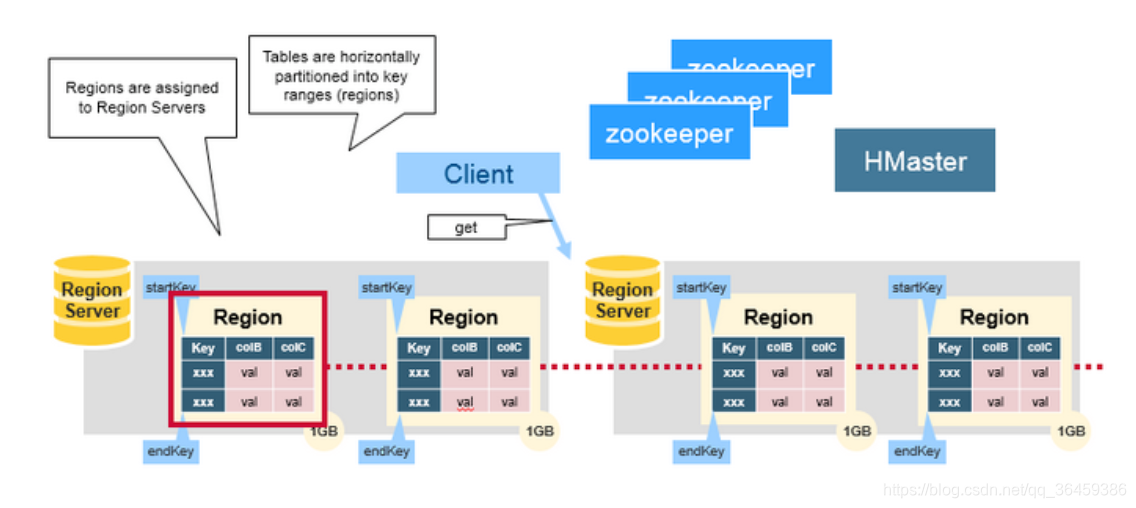
region
region是把表水平切分的,每个Region中存储着从startKey到endKey中间的记录,这些部分的表就是region,region是存在region server上的,region server负责数据读写,一个region server 大约能存1000个region(可以是不同表的数据)。每个region默认是1G
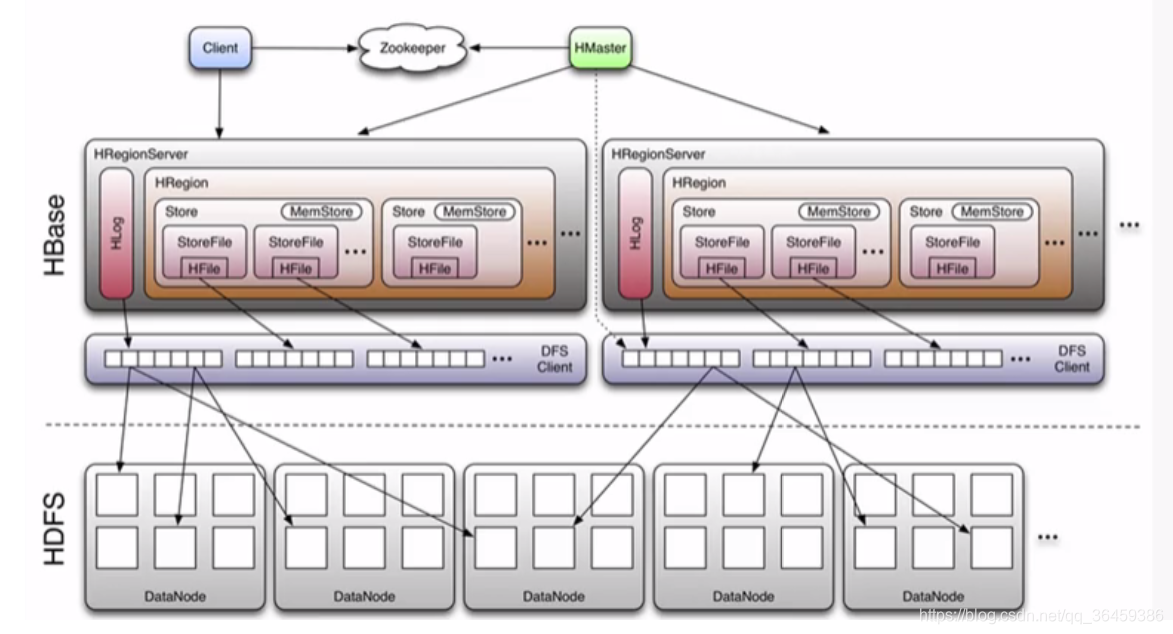
region由许多个store组成,每个store由Memstore和许多HFile组成,而每个列族对应一个Memstore,这就相当于region实际上是做了列裁剪的,所以是列式存储。
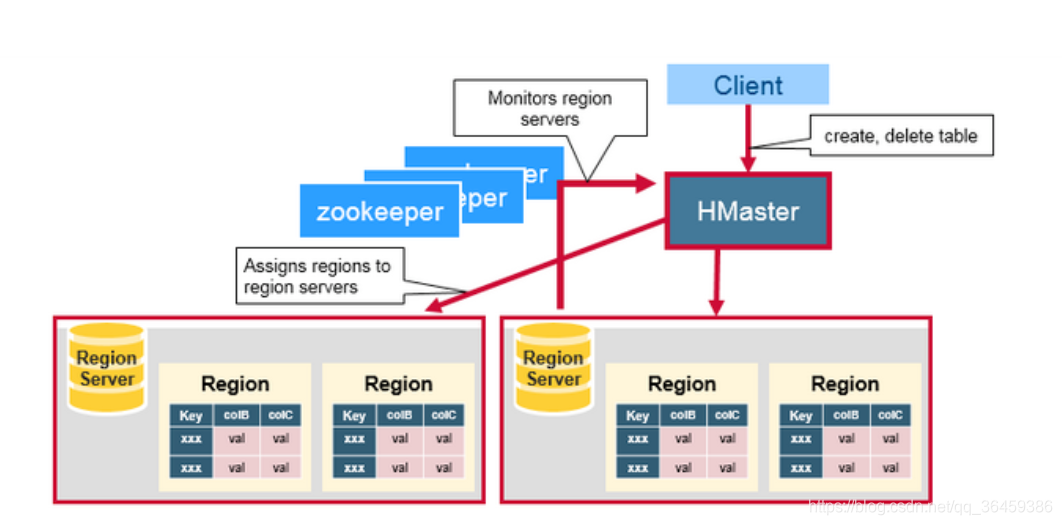
hmaster
hMaster可以重新分配region(启动的时候会分配,负载均衡和故障恢复的时候也会),hMaster会通过zookeeper监控regionServer实例。
hMaster是创建删除更新表接口的管理
zookeeper
协处理器,管理集群服务器状态(maintains)
提供故障通知(notification)
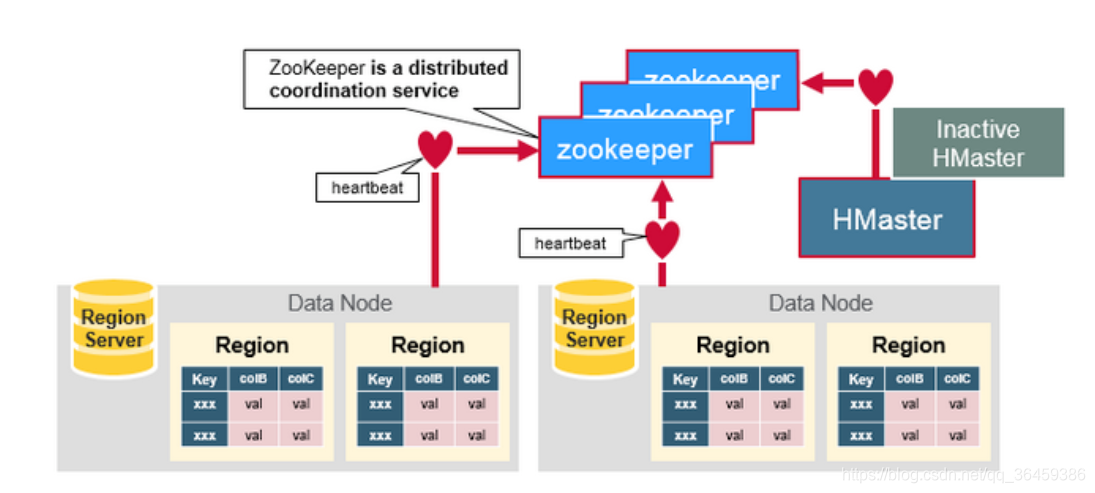
协作工作
1.在HMaster和RegionServer连接到ZooKeeper后创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点失效,则HMaster会收到通知,并做相应的处理。
2.HMaster通过监听ZooKeeper中的Ephemeral节点来监控HRegionServer的加入或宕机。
3.在第一个HMaster连接到ZooKeeper时会创建Ephemeral节点来表示Active的HMaster,其后加进来的HMaster则监听该Ephemeral节点,如果当前Active的HMaster宕机,则该节点消失,因而其他HMaster得到通知,而将自身转换成Active的HMaster,在变为Active的HMaster之前,它会创建在/hbase/back-masters/下创建自己的Ephemeral节点
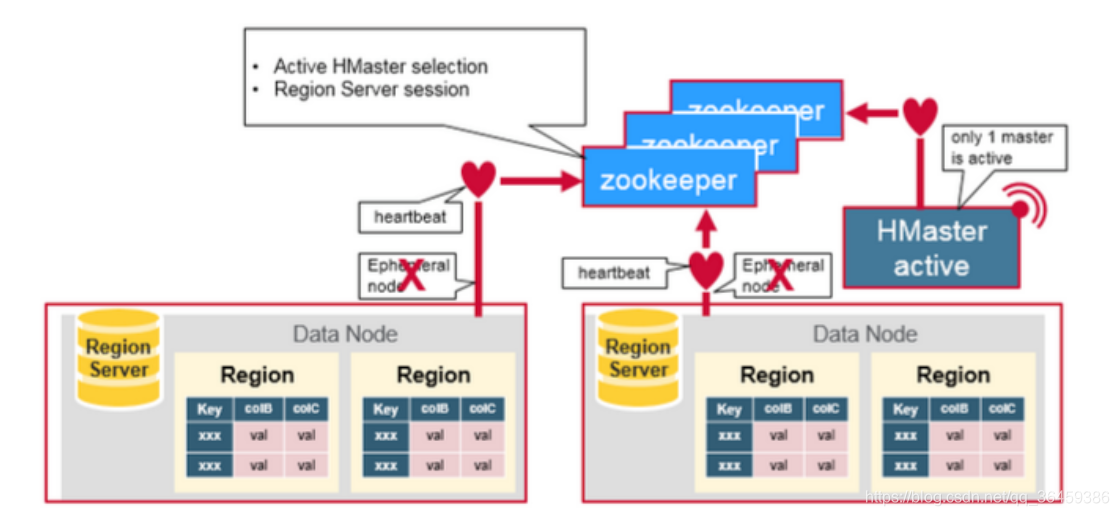
Hbase 第一次读写
元数据存储regions在集群中的位置,元数据存储在zookeeper上。
客户端从zookeeper得到元数据信息缓存起来,再在regionserver操作。
HBase中有个特殊的日志表叫做META table,这个表里存储着每个region在集群的哪个节点上,回想一下region是什么,它是一张完整的表被切分的每个数据块。这张表的地址存储在ZooKeeper上,也就是说这张表实际上是存在RegionServer中的,但具体是哪个RegionServer,只有ZooKeeper知道。
当客户端要读写数据的时候,无法避免的一个问题就是,我要访问的数据在哪个节点上或者要写到哪个节点上?这个问题的答案就与META table有关。
第一步,客户端要先去ZooKeeper找到这这表存在哪个RegionServer上了。
第二步,去那个RegionServer上找,怎么找呢?当然是根据要访问数据的rows key来找。找到后客户端会将这些数据以及META的地址存储到它的缓存中,这样下次再找到相同的数据时就不用再执行前面的步骤了,直接去缓存中找就完成了,如果缓存里没找到,再根据缓存的META地址去查META表就行了。
第三步,很简单,第二步已经知道键为key的数据在哪个RegionServer上了,直接去找就好了。
客户端缓存了meta 的位置和预先读取了row keys。下一次就不需要再去检索meta 表,除非region被移动了,这样就要重新检索,然后更新到缓存。
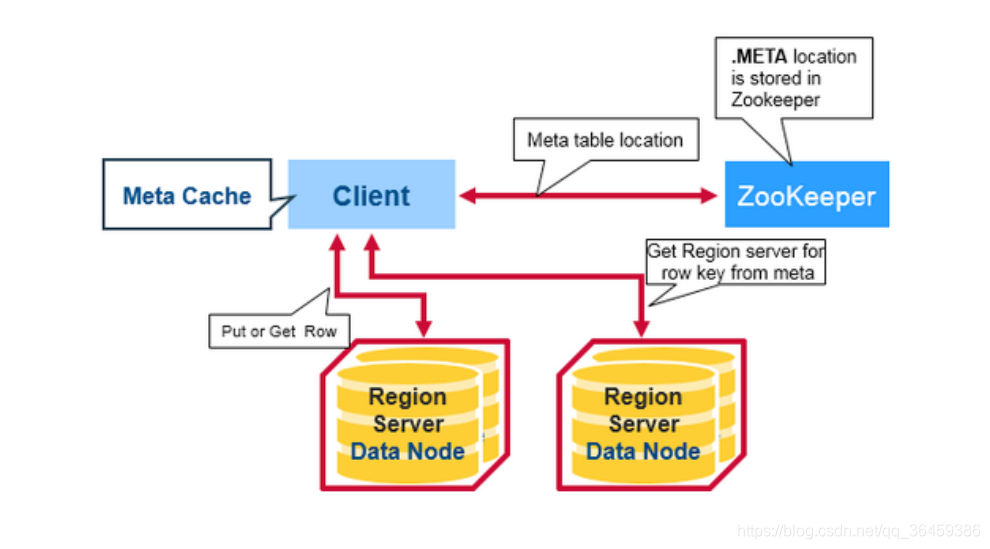
元数据信息
元数据的key是region start key(表切分时候的起始)和region id,values就是存储在哪个region server上。
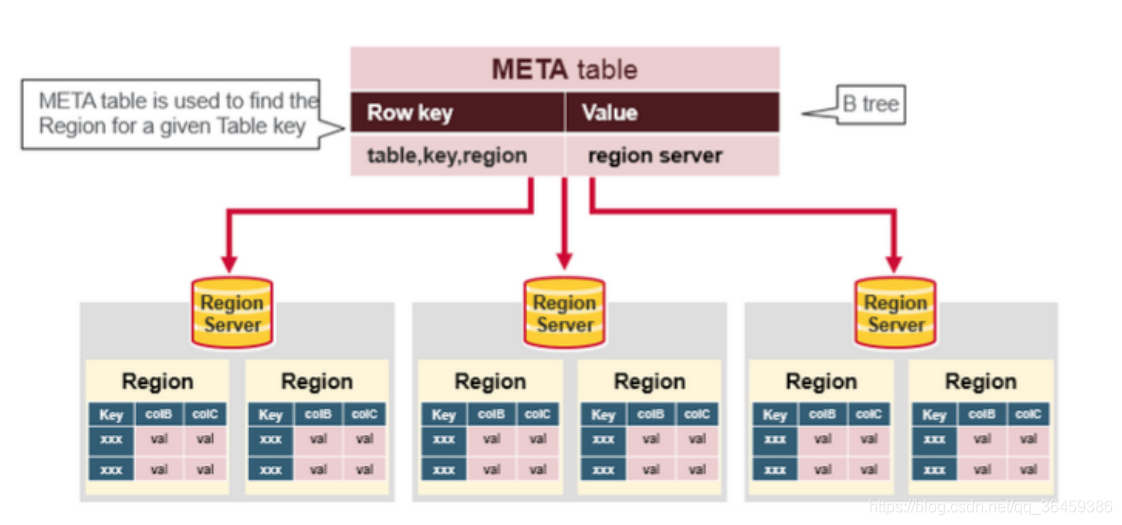
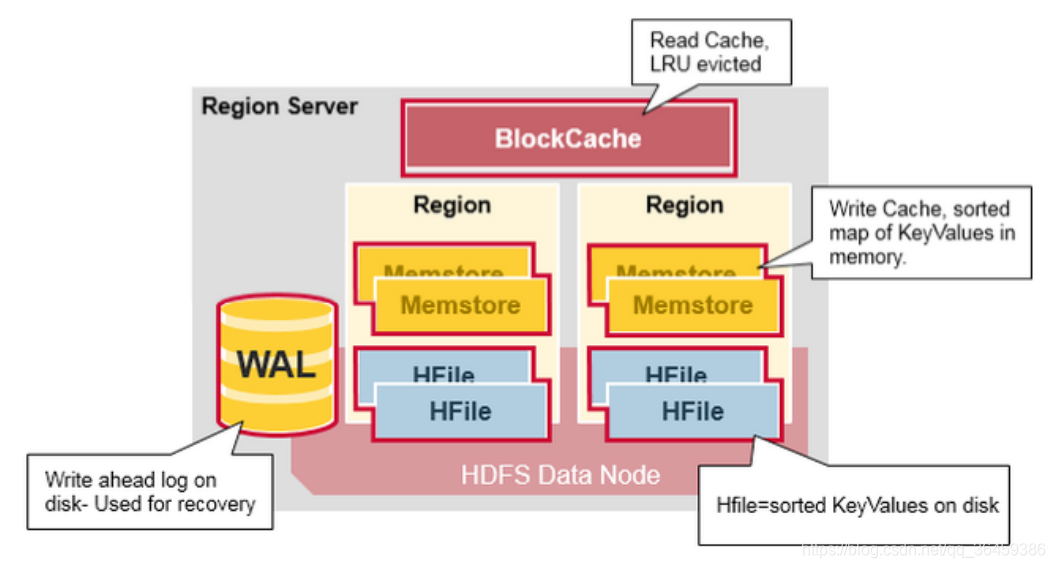
Region Server里的组成
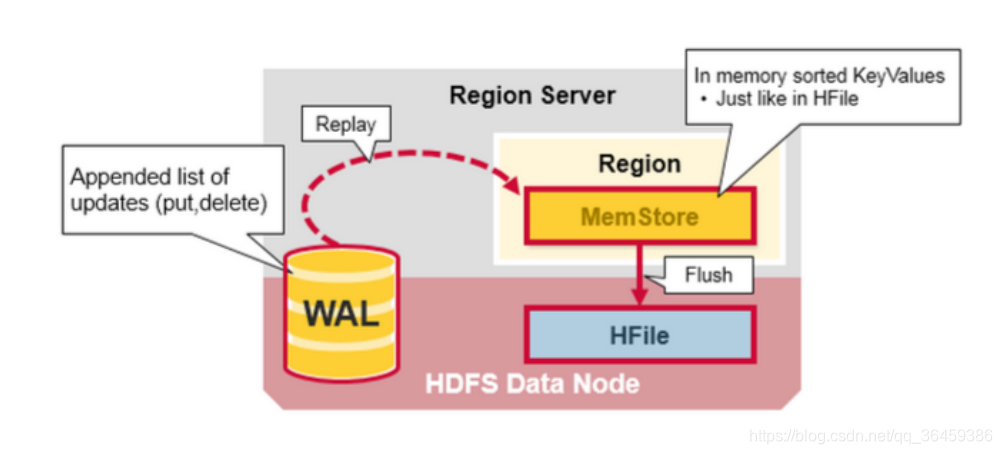
WAL:他是分布式文件系统的一个文件,存在硬盘,它用于存储新的还没有持久化存储的数据,它用于恢复数据预防失败。一个region Server一个WAL。
BlockCache:是读缓存。他存储频繁读取的数据,存储在内存里。当缓存满了,会清除最旧的缓存数据。一个region server只有一个blockcache。
MemStore:是写缓存。他存储还没被写到磁盘的新数据。写到磁盘前,数据会被排序。每个列族的每个region里有一个MemStore。
Hfiles存储行数据,以keyvalues的形式存储到磁盘。
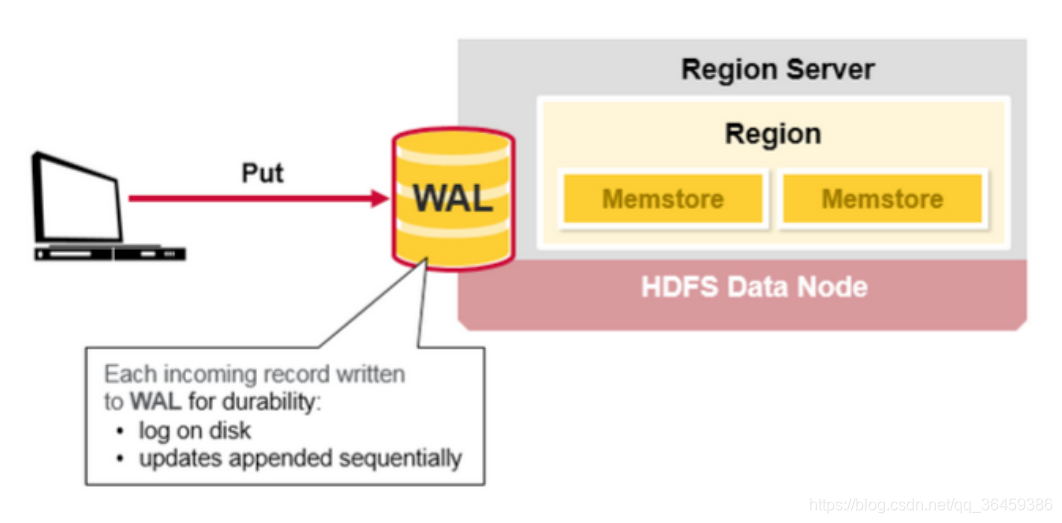
Hbase写步骤
1
当client发起一个put请求,第一步是写数据到WAL。
WAL的新增是数据增加在其末尾,WAL存在磁盘。
WAL是用于恢复没有持久化存储的数据防止服务宕机。
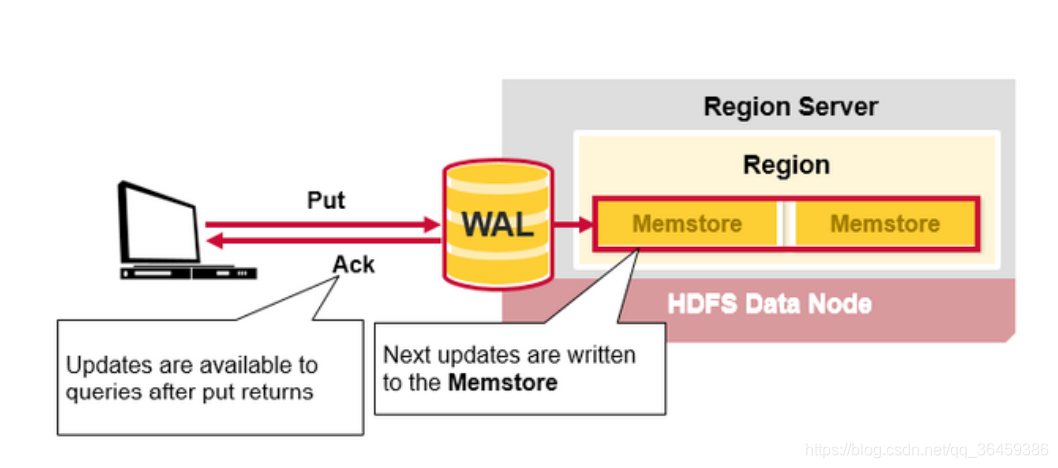
2
一旦数据被写到了WAL,它会被放到MemStore里。然后put请求待到放完返回到client。
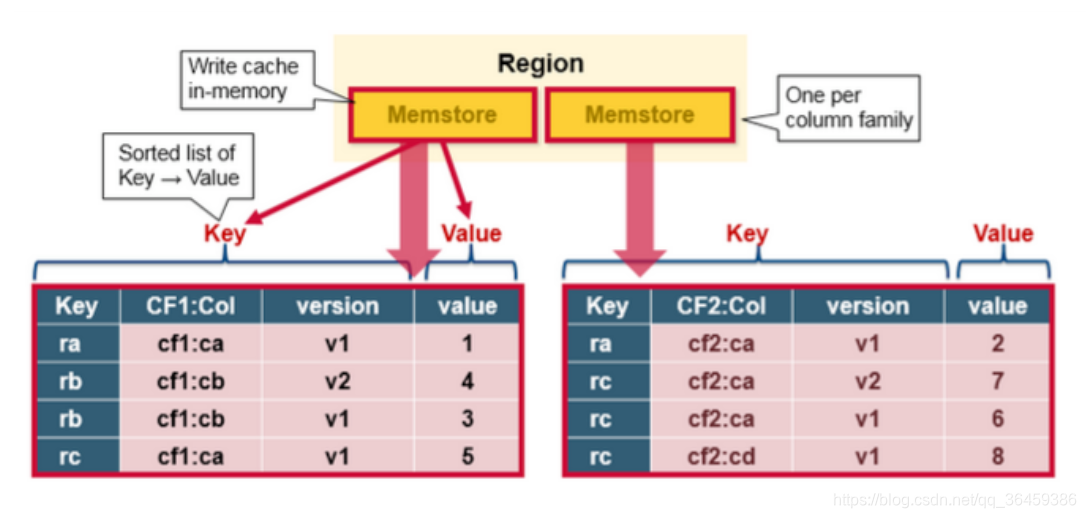
HBase MemStore
MemStore以keyvalues方式存储内存里跟新的数据,同时也会一模一样的存在HFile。每个列族会有一个MemStore。每个列族的更新会被排序。
HBase Region Flush
当MemStore累计存储了足够数据,全部数据会被写到HDFS上的一个新HFile里。HBase的每个列族可以有多个HFile,HFiles里包含了cells的值或者keyvalue的实例。这些文件在那些被Memstores编辑排序的keyvalue被刷到磁盘时创建。
注意HBase之所以有列族数量的限制。每个MemStore有一个列族,当一个MemStore满了,所有MemStore数据刷新,如果列族多会因为频繁刷新导致性能降低。同时也会保存最新的序列数据,这样系统就知道目前存储的情况。
缓冲区在刷新写入到HFile的时候,还会保存一个最后数据的序列数(sequence number),这个东西是干嘛的呢?其实是为了
反应从哪里结束从哪里开始,一旦region启动,这个序列数字会被读取,然后这个最高的序列数字会用做增加新数据的起点
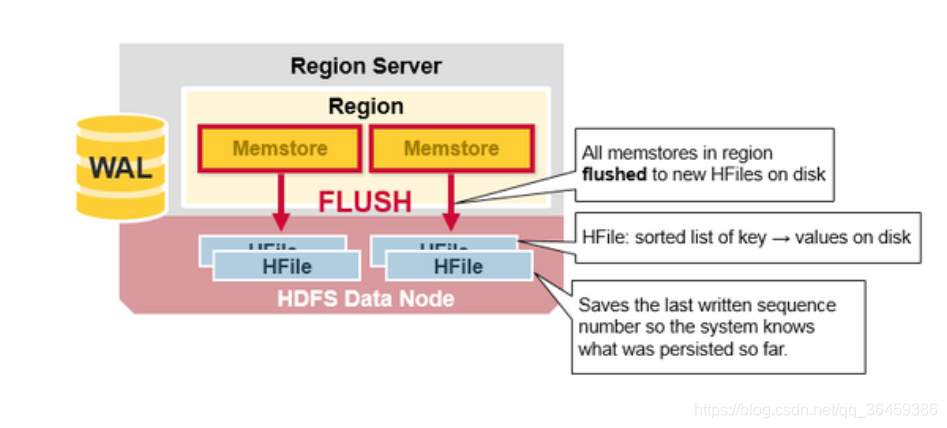
HBase HFile
数据以keyvalues的方式存在HFile上。当MemStore积累了足够数据,整个排好序的keyvalue会被写道HDFS的新HFile文件里。这是有顺序的写入。速度很快,因为顺序写disk,我们知到磁盘的顺序写性能很高,因为不需要不停的移动磁盘指针。
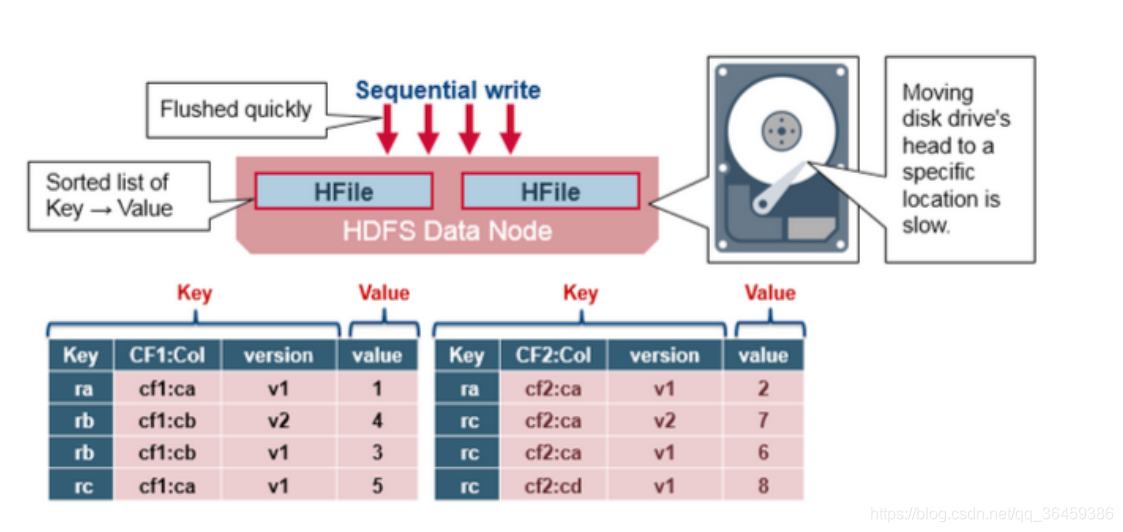
HBase HFile 结构
HFile包含一个多分层的索引结构,这样HBase寻找数据不需要读取整个文件。多分层的结构类似Btree。
键值对递增的存储
每个键值对大小是64KB的块
每个块有自己的子索引
每个块最新的key被放到intermediate index(放的是中间索引)
root index指向intermediate index
trailer指向元数据块,并且是被写到文件最后。trailer包含像布隆过滤和时间范围的信息。布隆过滤可以跳过没有row key的文件。时间范围信息用来跳过读取没有在读取数据所要求的时间范围内的数据。
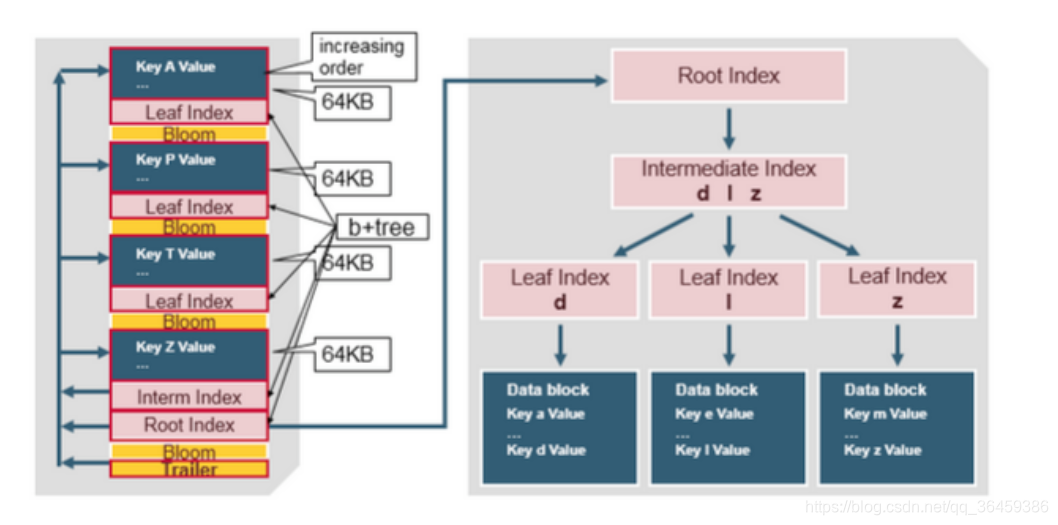
HFile Index
索引是当HFile被打开和保持在内存时加载的。查找工作在一个磁盘就可以完成
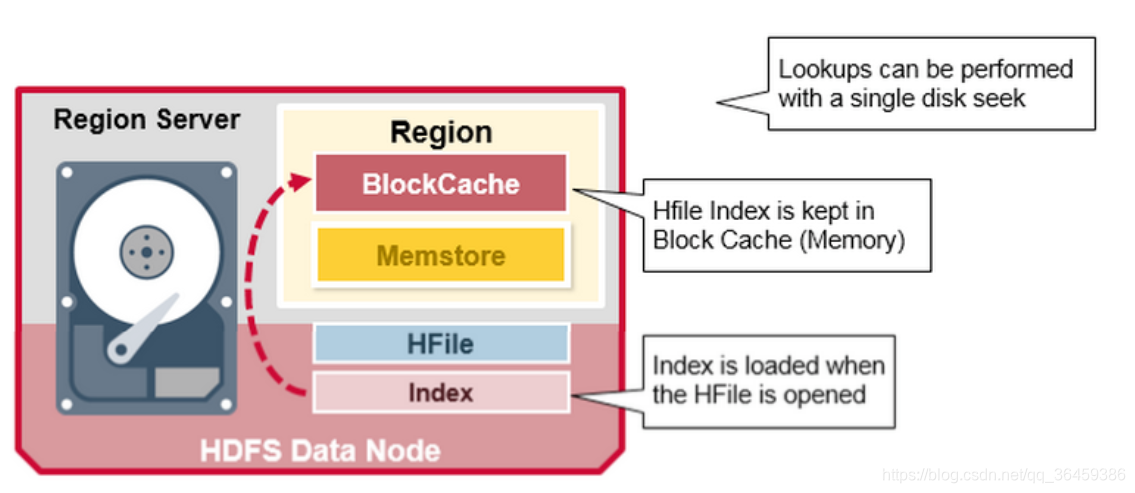
hdfs 读聚合
上面我们已经讨论了HBase的存储结构,在涉及读取操作的时候其实有个问题,一行数据可能存在的位置有哪些?一种是已经永久存储在HFile中了,一种是还没来得及写入到HFile,在缓冲区MemStore中,还有一种情况是读缓存,也就是经常读取的数据会被放到读缓存BlockCache中,那么读取数据的操作怎么去查询数据的存储位置呢?有这么几个步骤:
首先,设置读缓存的位置是什么?当时是为了高效地读取数据,所以读缓存绝对是第一优先级的,别忘了BlockCache中使用的是LRU算法。
其次,HFile和写缓存,选哪个?HFile的个数那么多,当然是效率最低的,而一个列族只有一个MemStore,效率必然比HFile高的多,所以它作为第二优先级,也就是说如果读缓存中没有找到数据,那么就去MemStore中去找。
最后,如果不幸上面两步都没能找到数据,那没办法只能去HFile上找了。
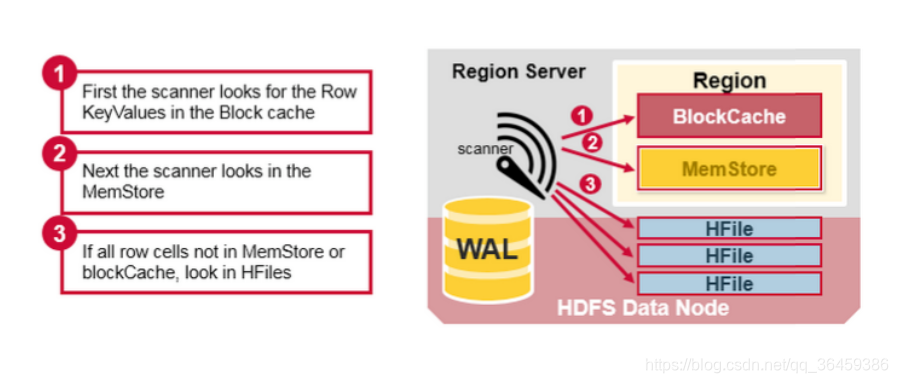 memstore每次刷新都会产生HFile文件,这样读的时候就要查好多文件,这就是读放大。
memstore每次刷新都会产生HFile文件,这样读的时候就要查好多文件,这就是读放大。
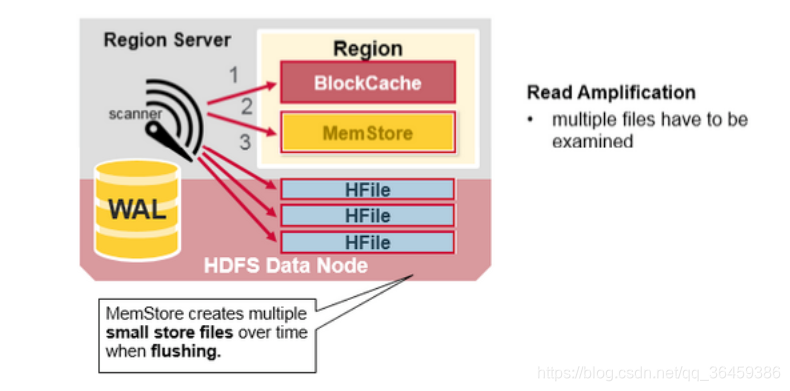
HBase文件聚合
如上所说,memstore刷新会产生很多HFile,那么这么多HFile检索会很麻烦。那么就可以把小文件聚合成大文件。
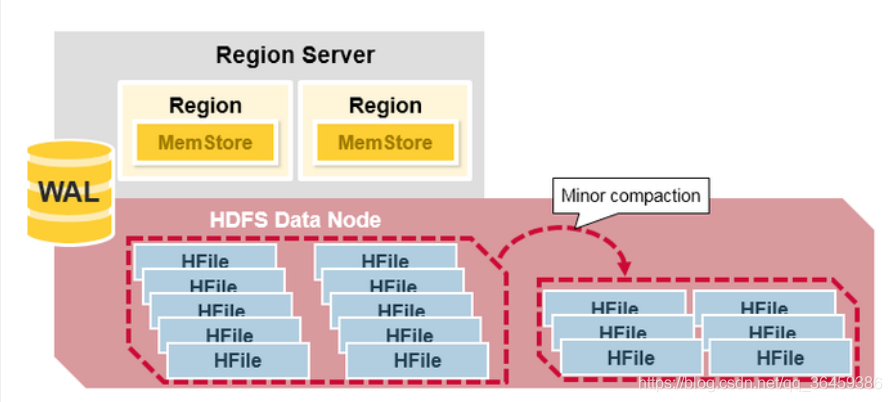
Minor聚合
Minor Compaction是将一些小的HFile文件合并成大文件,很明显它可以减少HFile文件的数量,并且在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的HFile。
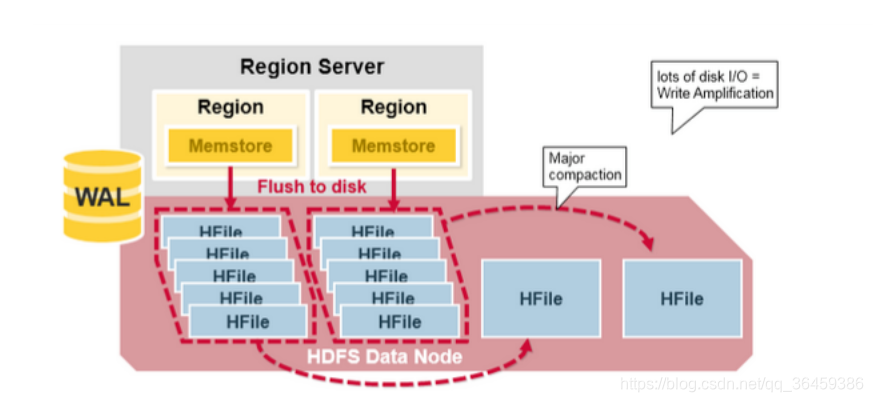
 Major聚合
Major聚合
Major Compaction是指将所有属于一个Region一个列族的HFile合并成一个HFile,也就是将同一列族的多个文件合并,在这个过程中,标记为Deleted的Cell会被删除,而那些已经Expired的Cell会被丢弃。但是这个合并操作会非常耗时。这就是写放大。
Region 切分
一开始假如每张表只有一个region。当一个region变得太大,就会分成两个子的region。然后这个切分的信息会上报给HMaster,然后可能为了负载均衡,会把region挪到其他regionserver上
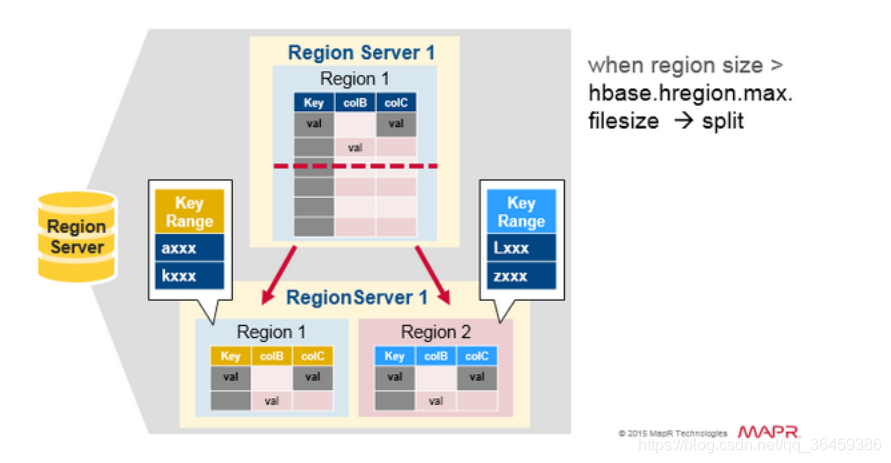
读的负载均衡
负载均衡可能使一个region server上的region被移到另一个region server上,但是当想聚合的时候,region的信息会回到原先的region做聚合。
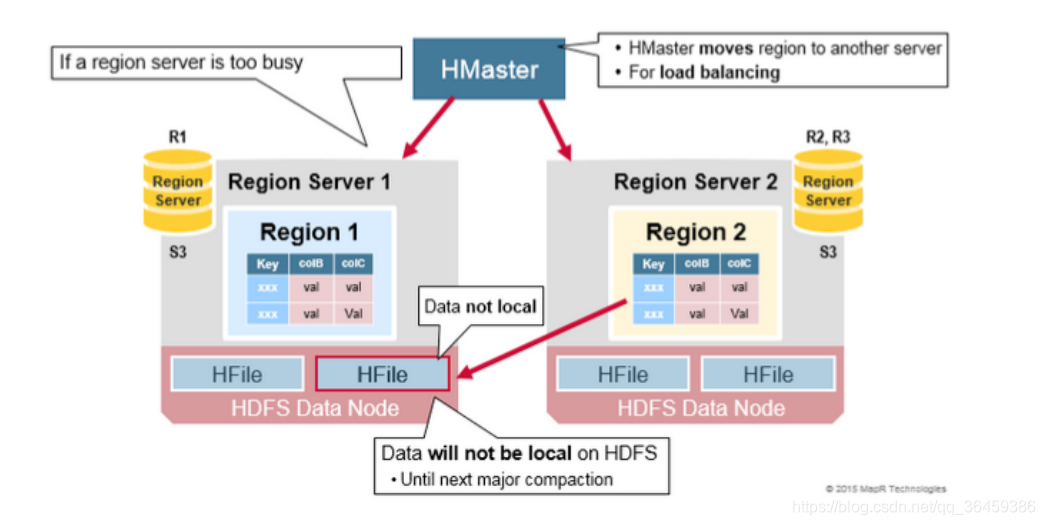
HDFS数据备份
WAL和HFile的数据会备份
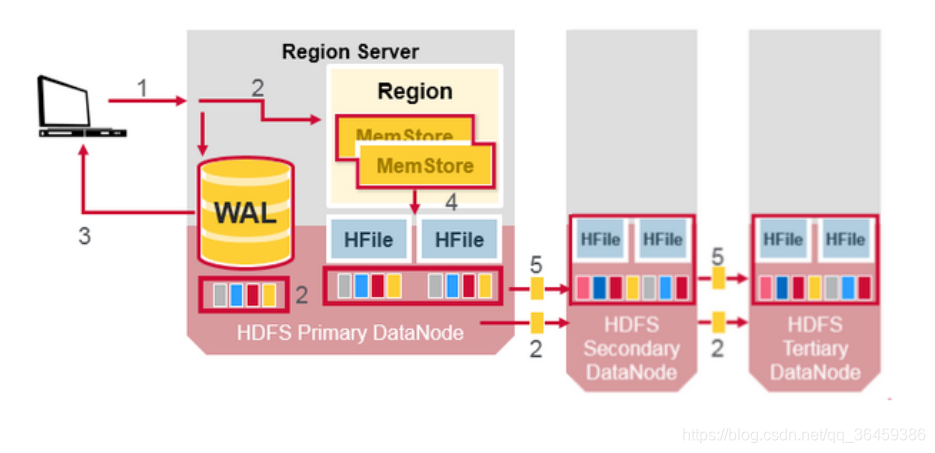
WAL和Hfile可以在磁盘上有副本,但是那些还在MemStore没被flush到Hfile的数据可怎么办呀?
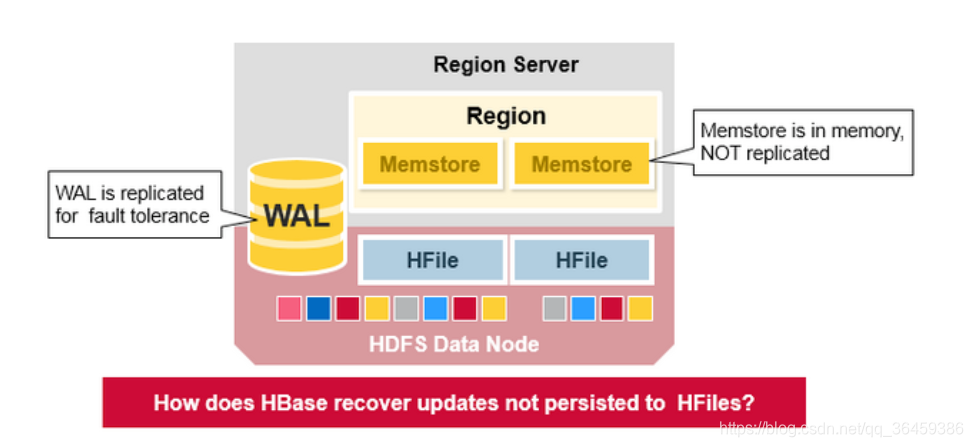
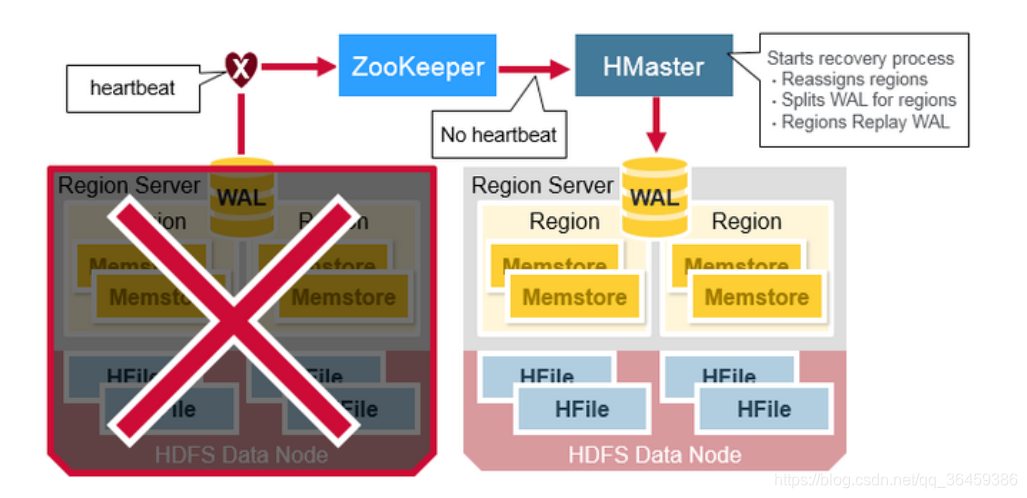
Hbase受冲击恢复
当一个RegionServer挂了,zookeeper监测到并通知HMaster
当HMaster检测到region Server出问题了,HMaster会把损坏的region Server上的regions重新分配到好的region Server上。
为了恢复损坏的region Server上的memstore的数据,HMaster会把损坏的地方的WAL(包含了很多个region的信息)切分成单独的文件(分成不同region),并且存储在新region server的datanode上。新的region server会重演被分到的WAL部分文件,来重建memstore
HBase的RIT问题
region合并的过程中,一直处于一种特殊状态,导致读写都不能处理。
解决方案:
1.MASTER切换(临时),使用jira做bug修复(打patch) hbase-17682(官网提及问题编号)
2.暴力方式:在hdfs上找到问题日志,删除,重启HBase等待自我修复即可(看问题原因)
HBase排查问题:
master日志
regionserver日志
WEB UI
hbck: 查看region
fsck: 查看block
jvm命令

















 3376
3376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









