







 本文详细介绍使用Puppeteer在Windows环境下实现网页爬虫的过程,包括安装配置、模拟用户操作、抓取图片资源等关键步骤。
本文详细介绍使用Puppeteer在Windows环境下实现网页爬虫的过程,包括安装配置、模拟用户操作、抓取图片资源等关键步骤。
puppeteer 实现爬虫(windows)
因为puppeteer中大量api都是异步函数,所以首先需要对异步函数async/await有一定的了解,await会暂停当前async函数的执行,等待后面的Promise的计算结果返回以后再继续执行,也就是说程序会在这停止,直到到await后面的函数有返回才继续执行,但是前提是返回必须是一个Promise对象,也就是await只对函数有返回Promise对象时才进行等待,其他情况不进行等待。
①首先安装一下puppeteer
因为安装Chromium十分的慢浪费时间,所以建议跳过该步骤
npm i --save puppeteer --ignore-scripts
②手动安装Chromium
贴上下载网址:https://www.chrome64bit.com/index.php/chromium-64-bit-for-windows
下载时候安装之后就是一个文件夹。
③安装完成之后启用Chromium,这里headless控制是否弹出浏览器,executablePath,指定Chromium的安装位置
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch({
headless: false,
executablePath: 'C:\\Users\\lenovo\\AppData\\Local\\Chromium\\Application\\chrome.exe', //指定chromium浏览器位置;
});
④启用Chromium之后,访问百度图片网址,模拟搜索关键字并查询的操作,查询的时候起初使用的,page.click(‘selector’),模拟点击,但是发现click函数总是报Error: Node is either not visible or not an HTMLElement。
await page.click('.s_btn');

检查网页元素发现,按钮的display属性是none,因此获取不到
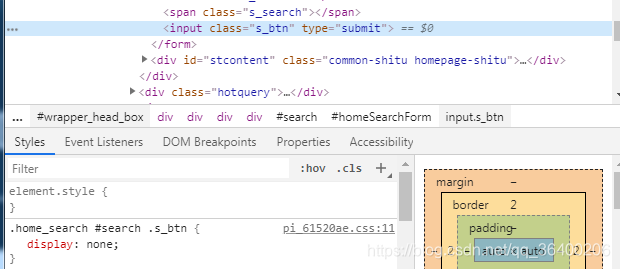
因此最后使用DOM的方法获取,利用的page.evaluate()方法。
await page.evaluate(()=> {
document.querySelector('.s_btn').click()
});
⑤查询关键字之后,将网页中所有的img标签匹配,并获取图片的src地址,并交由srcToImg函数进行处理。代码如下所示。
const puppeteer = require('puppeteer');
const {
mn } = require('../config/defualt');
const srcToImg = require('../helper/srcToImg');
(async () =>  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









