






Attention机制:在encoder过程中,输出是一个不同长度向量构成的序列
Attention应用于解码过程中,根据单词的不同赋予不同的权重。在encoder过程中,输出不再是一个固定长度的中间语义,而是一个由不同长度向量构成的序列,decoder过程根据这个序列子集进行进一步处理。
没有注意力机制:
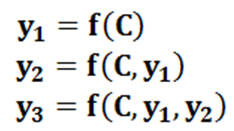
C是语义编码,表明不论生成哪个单词,句子source中任意单词对生成目标单词yi影响力都是相同的,没有体现注意力机制,就像眼中没有注意焦点。
加入注意力机制后:

其中,f2函数表示encoder对输入英文单词的某种变换函数,若encoder用的是RNN模型,这个f2结果往往是某个时刻隐层节点的状态值;g表示encoder根据单词的中间表示合成整个句子的中间语义表示。一般,g是对构成元素加权求和:
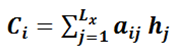
卷积编解码器:convolutional Encoder-Decoder,主要结构与 自编码类似,通过编码、解码复原图片上每一个点所属的类别

概括就是:从主干模型中提取出卷积了多次,具有一定特征的层(典型的是hw经过了4次压缩后的层),然后利用UpSampling2D函数进行三次上采样,得到输出层
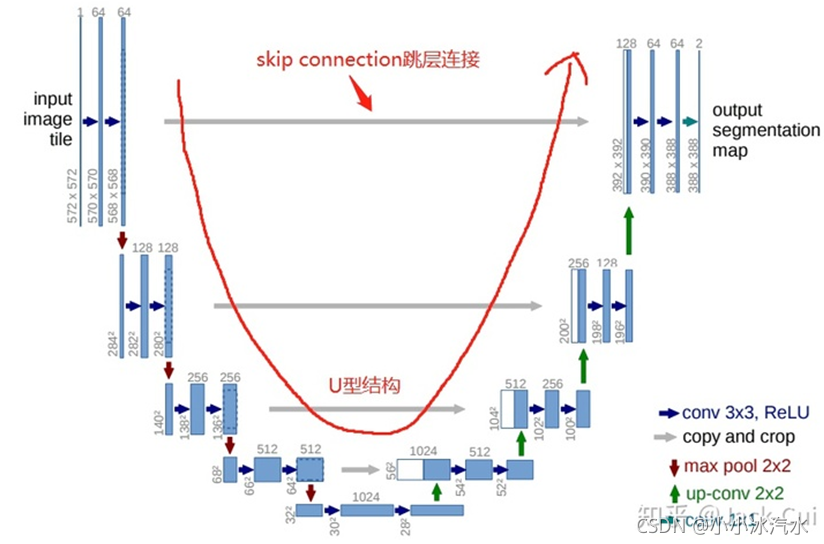
Unet是一个对称的网络结构,左侧为下采样(encoder),右侧为上采样(decoder)
Skip connection:中间四条灰色平行线,在上采样过程中,融合下采样过程中的feature map。融合操作就是讲feature map的通道进行叠加,俗称concat

https://zhuanlan.zhihu.com/p/142985678
transformer https://blog.youkuaiyun.com/tg229dvt5i93mxaq5a6u/article/details/78422216
Layer Normalization
LN是针对深度网络的某一层的所有神经元的输入按以下公式进行normalize操作
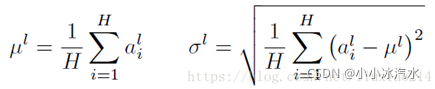
特征匹配:通过为生成器指定一个新的目标来解决GANs的不稳定性,以防止生成器对当前判别器的过度训练,新的目标不是直接对判别器的输出最大化,而是要求生成器生成与实际数据的统计信息相匹配的数据,我们使用鉴别器仅指定我们认为值得匹配的统计信息。即 我们对生成器进行训练,以匹配判别器的中间层特征的期望值。通过训练判别器,我们要求它找到那些最能区分真实数据和当前模型生成的数据的特征。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









