




 本文介绍了一种名为RecurrentU-Net的新结构,它通过集成递归单元解决了实时语义分割的问题,同时保持了高性能。与依赖预训练骨干网络的传统方法相比,RecurrentU-Net在GPU内存使用和推理时间上更为高效,适用于资源受限的环境。
本文介绍了一种名为RecurrentU-Net的新结构,它通过集成递归单元解决了实时语义分割的问题,同时保持了高性能。与依赖预训练骨干网络的传统方法相比,RecurrentU-Net在GPU内存使用和推理时间上更为高效,适用于资源受限的环境。
1. Introduction
目前的语义分割结构倾向于集中于高分辨率和大规模数据集,并依赖于经过预训练的骨干网络(ResNet101)。 这导致较高的GPU内存使用量和推理时间,在需要实时性能的环境下的操作并不理想。 之前的ICNet 之类的架构已解决了这一问题,但代价是性能大幅下降,作者提出了一个新的结构来解决这个问题——Recurrent U-Net。
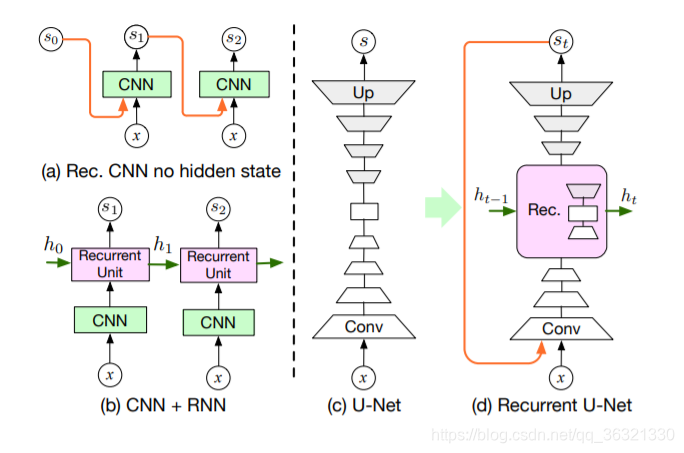
图2 循环分割(Recurrent Segmentation)。 (a)将先前的分割mask st-1与图像x concatenating,并将其循环馈送到网络。 (b)对于序列分割(sequence segmentation),要考虑网络的内部状态,可以改为将CNN与标准的循环单元结合起来。 在这里,我们以(c)的U-Net结构为基础,并提出在其多个层上构建一个循环单元。
2. Related Work
解决资源受限的网络主要有两种,第一种是采用encoder-decoder的网络,第二种是多分支结构,比如空间金字塔结构。
3. Method
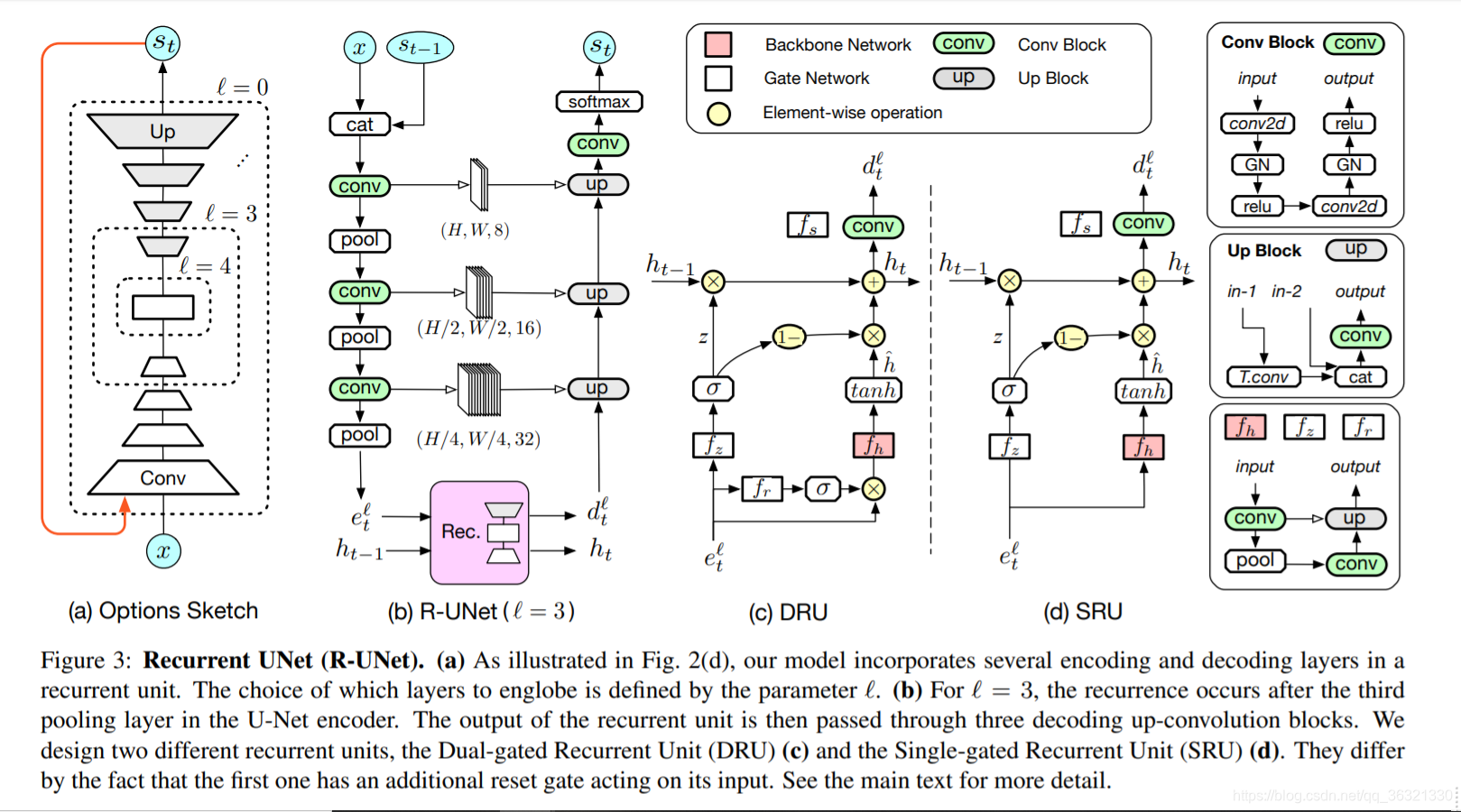
3.1. Recurrent U-Net
如图3(a),我们的U-Net encoder和decoder之间有跳跃连接,在所有卷积层中使用组归一化,作者的贡献是在分割结果 s 和 网络的多个内部状态 集成递归,分别是 在每次循环迭代t上简单的将之间的分割mask st-1 与 输入图像进行concatenating,和 我们用循环单元代替U-Net结构的编码和解码层的自己。
下面只考虑在循环迭代t处的过程,
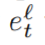 第L个编码层的激活值
第L个编码层的激活值
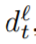 对应的解码层的激活值
对应的解码层的激活值
ht-1: 之前的隐藏张量
ht: 新的隐藏张量
我们可以选择循环单元插入的特定级别,在图3(b)中所展示的是级别为3时候的网络结构,当级别为0的时候,整个U-Net包含在其中。
3.2. Dual-gated Recurrent Unit
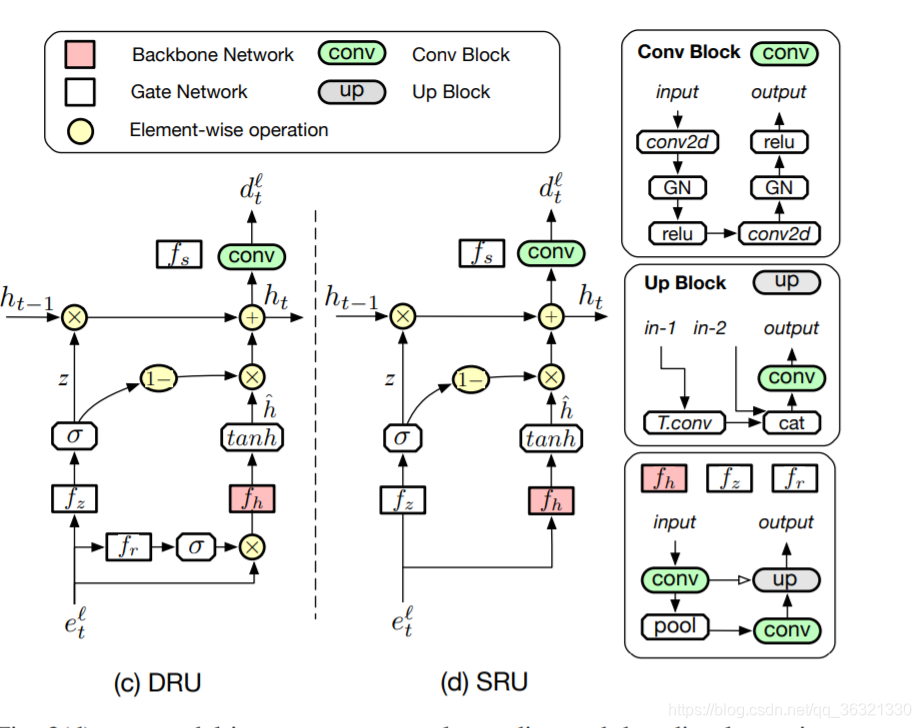
DRU借鉴了GRU的设计灵感,
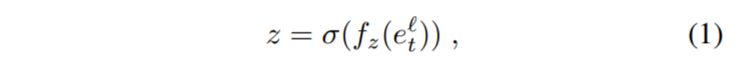
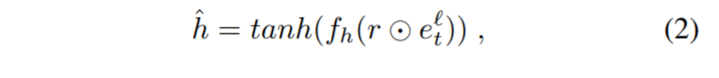
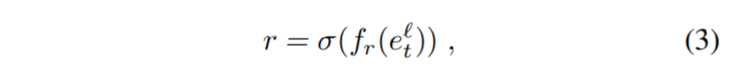
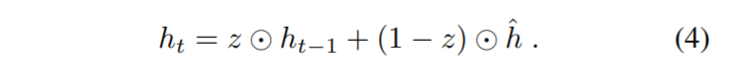
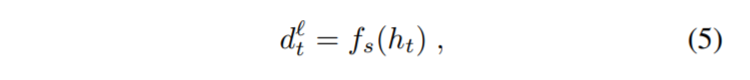
z:更新门
fz(.)表示一种编码器-解码器网络,其结构与我们用递归单元替换的U-Net部分相同
其中fh(.)是一个与fz(.) 具有相同结构的网络
 按照元素相乘
按照元素相乘
r:重置张量(reset tensor),允许我们屏蔽用于计算hˆ的部分输入。 。 计算为
其中fr(.)是一个与之间的网络具有相同结构的网络
ht:新的隐藏状态
3.3. Single-Gated Recurrent Unit
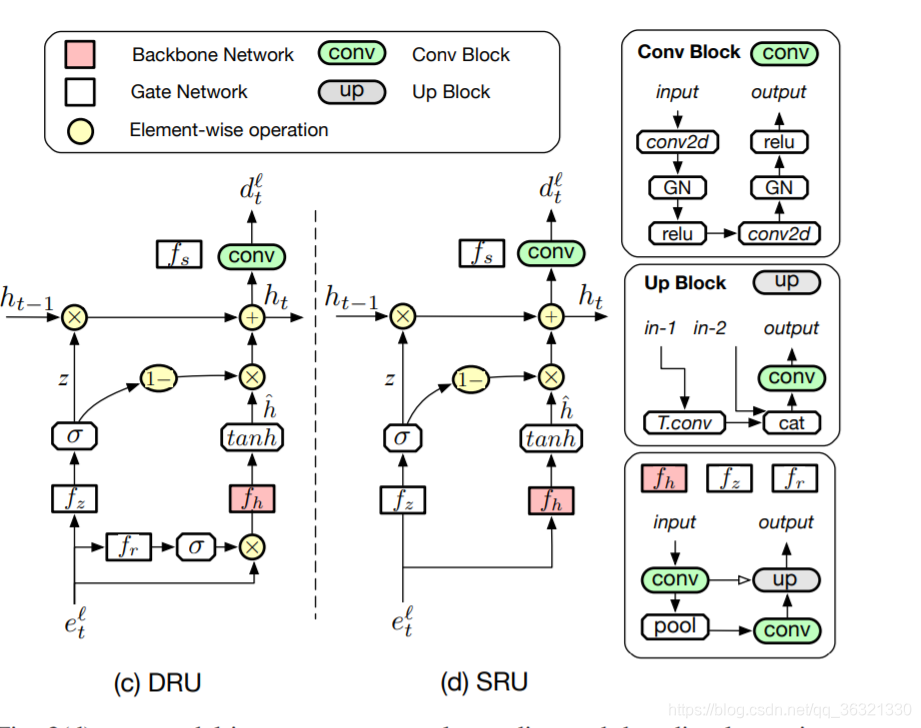
DRU的缺点:DRU合并了三个编码器-解码器网络,根据级别的选择,这可能变得占用大量存储器。 为了降低此成本,因此,我们引入了简化的循环单元,该单元依赖于单个门,因此被称为单门循环单元(SRU)。
具体来说,如图3(d)所示,我们的SRU具有与DRU相似的结构,但没有reset tensor r。 因此,方程式与上述基本相同,除了候选隐藏状态外,我们现在将其表示为
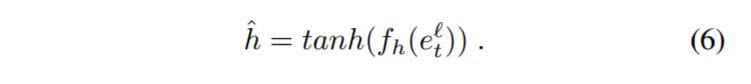
这种简单的修改使我们能够从循环单元中删除一个编码器/解码器网络,正如我们的结果所示,分割精度的损失很小。
3.4. Training
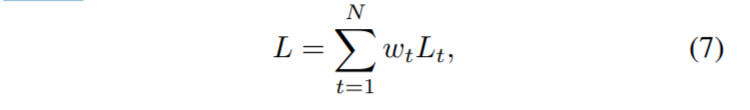
L是总损失,N是递归数目,Lt是在迭代t处的交叉熵损失,wt是加权系数。

在这个实验中,要么设置α= 1,要么α= 0.4
4. Experiments
作者将数据集划分为20% / 20% / 60% ,以进行 训练 / 验证 / 测试 。
数据集:



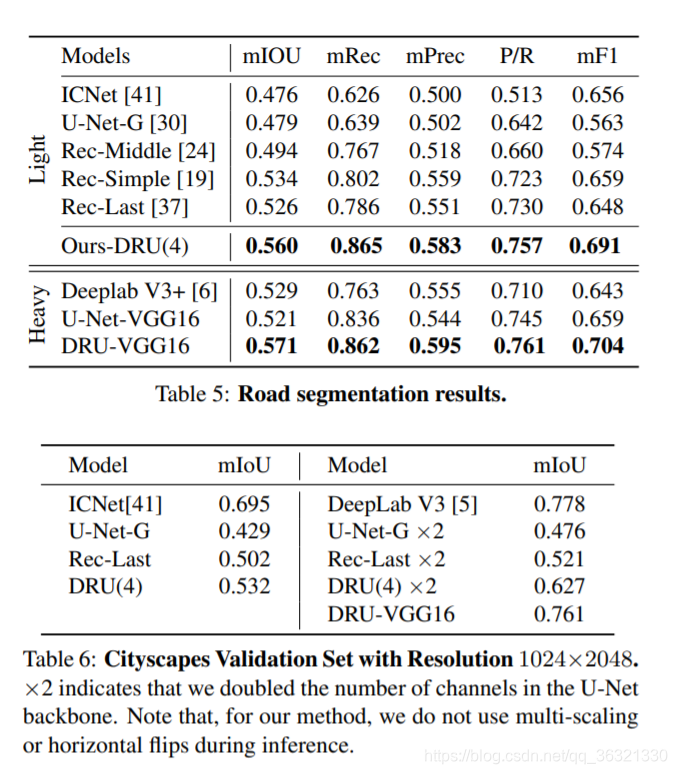
表3显示DRU-VGG16优于Ours-DRU,例如KBH上的0.02 mIoU点。 DRU-VGG16具有41.38M参数。 这是Ours-DRU(4)的100倍,后者只有0.36M参数。 此外,DRU-VGG16仅以18 fps运行,而Ours-DRU(4)达到61 fps。 这使得DRUVGG16和其他重型模型不适合VR摄像机等嵌入式系统,而Ours-DRU可以在资源受限的环境中更容易地利用

视网膜,手部和道路图像; 1、2和3次迭代后的结果、Ground Truth。


















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









