







 本文介绍了作者参加Kesci预选赛的大数据挑战,任务是建立文本情感分类模型,使用FastText进行二分类(Negative/Positive)。通过预处理数据、训练模型并进行预测,作者分享了参赛过程和代码片段,提供了FastText参数介绍的链接,并祝参赛者好运。
本文介绍了作者参加Kesci预选赛的大数据挑战,任务是建立文本情感分类模型,使用FastText进行二分类(Negative/Positive)。通过预处理数据、训练模型并进行预测,作者分享了参赛过程和代码片段,提供了FastText参数介绍的链接,并祝参赛者好运。
比赛链接:https://www.kesci.com/home/competition/5cb80fd312c371002b12355f
预选赛题——文本情感分类模型
本预选赛要求选手建立文本情感分类模型,选手用训练好的模型对测试集中的文本情感进行预测,判断其情感为「Negative」或者「Positive」。所提交的结果按照指定的评价指标使用在线评测数据进行评测,达到或超过规定的分数线即通过预选赛。
比赛数据
数据样本格式:
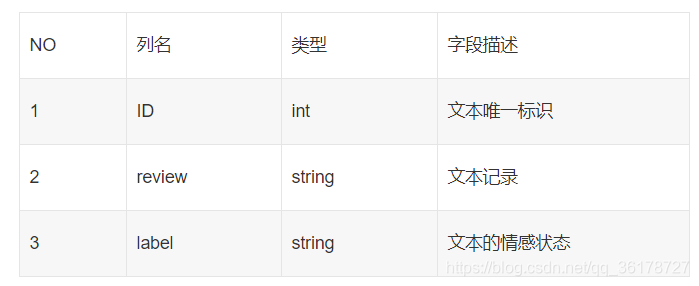
其中,训练集的样本规模为6328,测试集的样本规模为2712。为保证比赛结果的真实性。每周一中午12点,将替换为新的测试集数据,供队伍答题使用。
提交结果
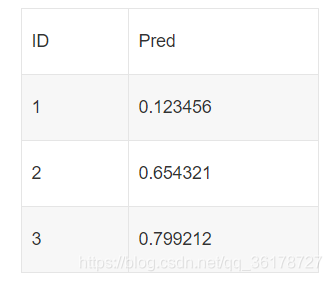
选手提交.csv的结果文件,文件名可以自定义,但文件内的字段需要对应。其中,ID表示文本唯一标识,pred表示预测该条文本的情感状态是否为「Positive」。
结果文件的内容示例:
解答
这个题目我是当作了一个二分类问题,之前参加比赛使用过Fasttext感觉还不错,就想到了用这个尝试一下,下面附上代码。(没有系统学习过Python和机器学习,代码有些丑,见谅)
首先是预处理,去掉数据集中的符号并且将数据转化为fasttext要求的格式。
fasttext的使用较为简单,要求的格式为 “内容xxxxxx __label__标签"
import re
import fasttext
import pandas as pd
from sklearn.model_selection import train_test_split
# train处理
train_pre = open('../data/train_pre.csv', 'w', encoding='utf-8')
cnt = 0
for line in open('../data/train.csv', 'r'): # 打开文件
cnt = cnt + 1
if cnt == 1:
train_pre.write('review,label\n')
line = line.replace('ID,review,label', '')
line = line.replace('\r', '') # 替换换行符
line = line.replace(',', '')
line = line.replace('\n', '')
if (line == '\n'):
line = ''
comp = re.compile('[^A-Z^a-z\n ]')
line = comp.sub('', line)
line = line.replace('Positive', ', __label__Positive\n')
line = line.replace('Negative', ', __label__Negative\n')
train_pre.write(line)
之后就可以愉快地调用fasttext啦,不过为了训练效果更好,我使用train_test_split进行乱序划分测试集和训练集,以便查看分类效果。代码如下
data = pd.read_csv('../data/train_pre.csv')
x = data['review']
y = data['label']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=12345)
train_true = open('../data/train_true.csv', 'w', encoding='utf-8')
for i in zip(x_train, y_train):
t = str(i[0]) + ' ' + str(i[1]) + '\n'
train_true.write(t)
train_true = open('../data/train_test.csv', 'w', encoding='utf-8')
for i in zip(x_test, y_test):
t = str(i[0]) + ' ' + str(i[1]) + '\n'
train_true.write(t)
之后就是真正地调用fasttext进行分类了
classifier = fasttext.supervised('../data/train_true.csv', 'classifier.model')
result = classifier.test('../data/train_test.csv')
print("准确率:", '{:.2%}'.format(result.precision))
由于比赛还没结束,supervised涉及到很多参数调整可以优化分类效果,这里我就不公布参数了。
分享一个fasttext的参数介绍:https://blog.youkuaiyun.com/qq_32023541/article/details/80845913
最后,调用训练好的模型对测试集进行预测并保存
import fasttext
import pandas as pd
import re
classifier = fasttext.load_model("classifier.model.bin", label_prefix="__label__")
test = pd.read_csv('../data/test.csv', header=0)
t = list(test['review'])
print(t)
comp = re.compile('[^A-Z^a-z\n ]')
num = 0
result = open('../data/result.csv', 'w', encoding='utf-8')
result.write('ID,Pred\n')
for i in t:
num = num + 1
line = comp.sub('', i)
pred = classifier.predict_proba([line], 1)
myType = pred[0][0][0]
myPrec = pred[0][0][1]
if myType == 'Negative':
myPrec = 1 - myPrec
result.write(str(num)+','+str(round(myPrec,6))+'\n')
提交通过

祝各位比赛顺利~
另外附上我之前在服创比赛的博客链接,欢迎大家
https://blog.youkuaiyun.com/qq_36178727/article/details/89712858

















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









