







记录自己使用VMware搭建Spark集群的过程,使用三台虚拟机。
若只需要Hadoop集群,则将5和7跳过即可;
若只需要Spark Standalone模式的集群,则将6和7跳过即可。
文章目录
1. 环境
- 系统:VM下的ubuntu16.04,本次实验中使用3个VM
- JDK版本:jdk1.8.0_201
- hadoop版本:hadoop-2.6.5
- Spark版本: spark-2.4.1-bin-hadoop2.6
2. 第一台虚拟机
2.1 虚拟机创建
- 下载Ubuntu16.04的ISO镜像,使用VMware创建虚拟机,本次实验中分配内存为2GB,硬盘100G,用户命名为
node(自己在做的时候命名成vm01了) - 启动虚拟机,使用
ifconfig查看自己分配到的ip地址,如下:
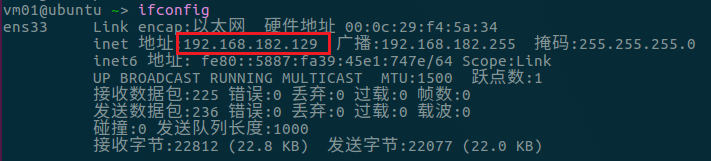
-
测试下ping外网(比如www.baidu.com)能不能ping通,再测试与物理机是否可以互相ping通,若可以则网络没问题
-
修改源,本次实验使用清华源如下(网上找下就有),复制到
/etc/apt/sources.list即可(覆盖原来的)
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
- 修改后更新下软件,如下:
sudo apt update
sudo apt upgrade
- 下载
vim(编辑文件方便)、fish(无敌shell)
sudo apt install vim
sudo apt install fish
- 修改hosts文件,给ip取个名字,方便访问
sudo vim /etc/hosts
#这里有个127.0.1.1的,注释掉,不然后面启动的时候master会被解释成这个地址,导致slave节点访问不到
#127.0.1.1 master
#增加内容如下,预计ip是下面三个,之后其他虚拟机ip不对也可以直接改
192.168.182.129 master
192.168.182.130 slave1
192.168.182.131 slave2
2.2 Hadoop安装
Hadoop的安装按照之前的笔记操作,但是配置部分就不用了,也就是安装好jdk和hadoop就可以了。
关于Hadoop开发环境配置等问题,可参考之前有关的另一篇笔记。
2.3 Spark安装
- 从官网上下载跟之前hadoop版本匹配的spark版本,如下:
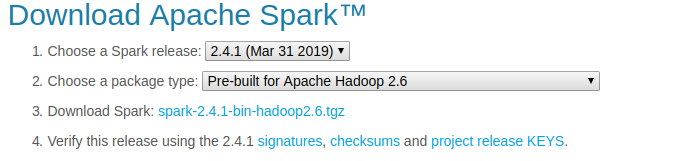
- 解压文件,放到/opt目录下
tar -xf spark-2.4.1-bin-hadoop2.6.tgz
mv spark-2.4.1-bin-hadoop2.6 /opt
- 建立spark-2.4.1-bin-hadoop2.6的软链接(方便使用不同版本),并在/etc/profile中配置环境变量
ln -snf spark-2.4.1-bin-hadoop2.6/ spark
vim /etc/profile
#spark环境变量
SPARK_HOME=/opt/spark
PATH=$PATH:${SPARK_HOME}/bin
source /etc/profile #运行使环境变量生效
- 运行spark-shell(若环境变量配置成功,任何目录下都可以),如下(
:quit退出):
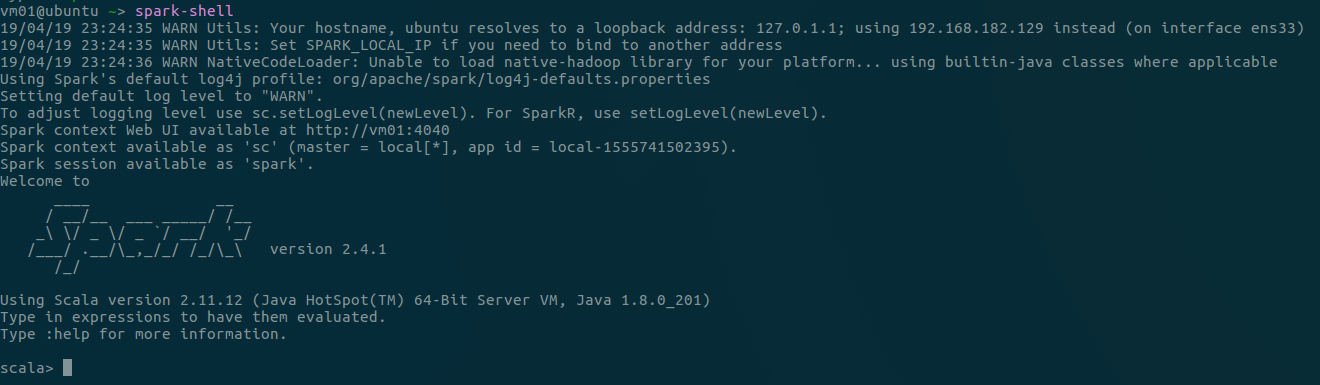
3. 虚拟机复制
直接复制第一台配置好的虚拟机,后面的集群搭建只需要修改一些配置文件即可。
3.1 修改用户名/组(看黑体)
若刚才用户命名为node这步就可以跳过了,这步是我一开始把用户命名成vm01了,改成node好看点。
对vm01修改用户名和所属组,参考Reference.2,具体如下(以命名为Node为例):
- 查看某个目录下的文件,如下以
/opt为例:

- 修改
/etc/sudoers,提前给用户权限,如下:
sudo vim /etc/sudoers
#User privilege specification
root ALL=(ALL:ALL) ALL #这一行本来有的
vm01 ALL=(ALL:ALL) ALL
Node ALL=(ALL:ALL) ALL
- 修改
/etc/shadow,修改登录时的用户,如下:
sudo vim /etc/shadow
vm01:$1$RnoyuyTk$OHTSf0TNpJajOkmim7uFD/:18006:0:99999:7::: #原来的,把vm01改成下面的Node
Node:$1$RnoyuyTk$OHTSf0TNpJajOkmim7uFD/:18006:0:99999:7:::
- 修改home下的文件
cd /home
sudo mv vm01 Node
- 修改passwd文件
sudo vim /etc/passwd
vm01:x:1000:1000:vm01,,,:/home/vm01:/bin/bash #原来的,把vm01改成下面的Node
Node:x:1000:1000:Node,,,:/home/Node:/bin/bash
- 修改用户的组
sudo vim /etc/group
vm01:x:1000: #原来的,把vm01改成下面的Node
Node:x:1000:
- 再次进入
/etc/sudoers,将刚才增加的vm01去掉 reboot重启,再次查看/opt下的文件,如下,可以看到已经成功修改

3.2 克隆虚拟机
- 在VMware中选择
vm01,右键“管理”,点击“克隆”,按提示进行克隆即可(以命名为vm02为例)
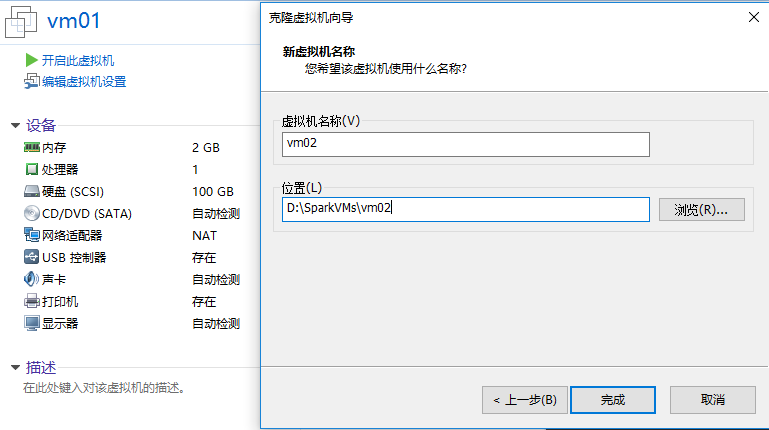
- 重复上述过程,本次实验中克隆2个虚拟机,分别为
vm02和vm03
3.3 修改主机名称
把三台VM的主机名分别改为master,slave1,slave2,参考Reference.2,具体如下:
- 修改主机名,进入文件改成要的名字
sudo vim /etc/hostname
- 修改hosts文件,把原来的主机名改成新的主机名
sudo vim /etc/hosts
- 重启即可
4. 配置ssh免密登陆
启动Spark节点的时候之前的通信使用ssh,若没有ssh,则启动会报错如下:

-
先确定三台VM是否能互相ping通
-
在三台主机上都安装
ssh
sudo apt install openssh-server
- 检查ssh是否开启,若输出类似下方则成功开启,若无反应则未开启
ps -e | grep ssh
#开启命令
sudo service ssh start #安装好应该会自动开启,一般上面这步就可以看到输出了

- 在主节点
master上生成公钥,使用如下命令,一路回车即可
ssh-keygen -t rsa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









