




 本文介绍了多种聚类算法,包括K-means系列和密度、层次、谱聚类。同时,详细阐述了距离表示方法,如闵可夫斯基距离、标准化欧氏距离、夹角余弦、KL距离和杰卡德相似系数。此外,还讨论了聚类效果的评价指标,如均一性、完整性、兰德指数、互信息和轮廓系数,并指出这些指标在评估聚类质量中的作用。
本文介绍了多种聚类算法,包括K-means系列和密度、层次、谱聚类。同时,详细阐述了距离表示方法,如闵可夫斯基距离、标准化欧氏距离、夹角余弦、KL距离和杰卡德相似系数。此外,还讨论了聚类效果的评价指标,如均一性、完整性、兰德指数、互信息和轮廓系数,并指出这些指标在评估聚类质量中的作用。
1.可以实现聚类的算法大概有这么多:
K-means系列的:K-means,K-means++,K_means||,canopy,mini Batch K-means
密度聚类:
层次聚类:
谱聚类:
2.相似度/距离表示:
2.1 闵可夫斯基距离
两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
其中p是一个变参数。
当p=1时,就是曼哈顿距离
两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离
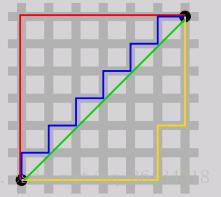
示例图:
当p=2时,就是欧氏距离
- 1. 欧氏距离,最常见的两点之间或多点之间的距离表示法,它定义于欧几里得空间中,如点 x = (x1,...,xn) 和 y = (y1,...,yn) 之间的距离为:
当p→∞时,就是切比雪夫距离


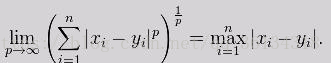
证明过程如下:
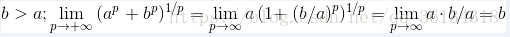
注:
1.闵可夫斯基距离比较直观,但是它与数据的分布有关,如果 x 方向的幅值远远大于 y 方向的值,这个距离公式就会过度放大 x 维度的作用。
2.离散属性不能直接在属性值上计算闵式距离
2.2 标准化欧氏距离 标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。
假设样本集X均值为m,标准差为s,那么X的“标准化变量”X*表示为
经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:

经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









