









相关地址:
(1)论文地址:https://arxiv.org/pdf/2002.10120
(2)本人打包好数据可运行代码,SFNet.zip: https://pan.baidu.com/s/1oBCpsHHuquk3AoI4cieWVQ?pwd=1efd 提取码: 1efd
(3)修改前模型代码来源:https://github.com/sithu31296/semantic-segmentation
如有谬误请指正。
概要
光流的理念来自于视频处理任务,在对齐两个相邻的视频帧特征时光流非常有效且灵活,这启发作者设计了一种基于流对齐模块(FAM),通过在网络内部预测流场来对齐两个相邻层次的特征图。作者将这种流场定义为语义流,它是在特征金字塔的不同层次之间生成的。以下是论文《Semantic Flow for Fast and Accurate Scene Parsing》原理解析及可执行代码分享,用于滑坡检测示例。
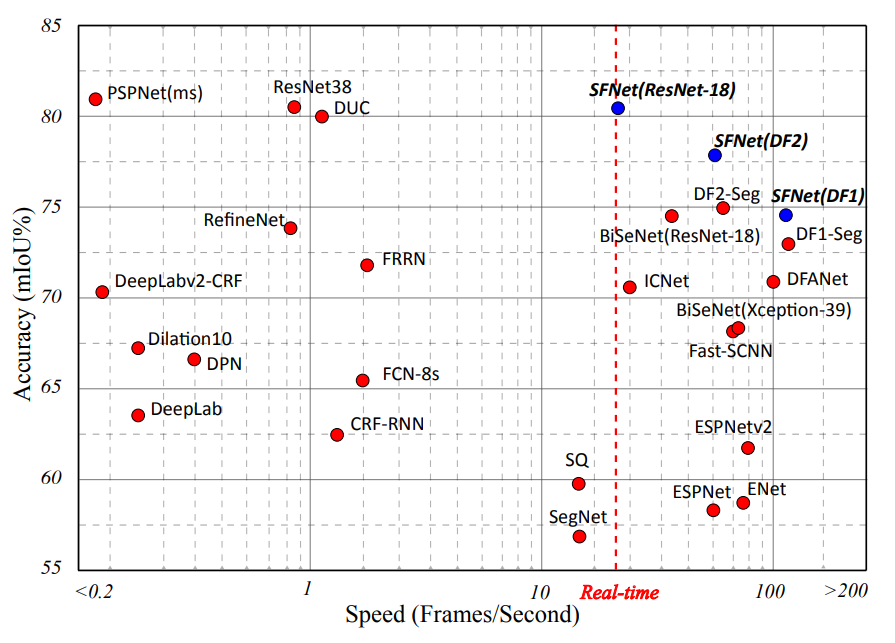
理论知识
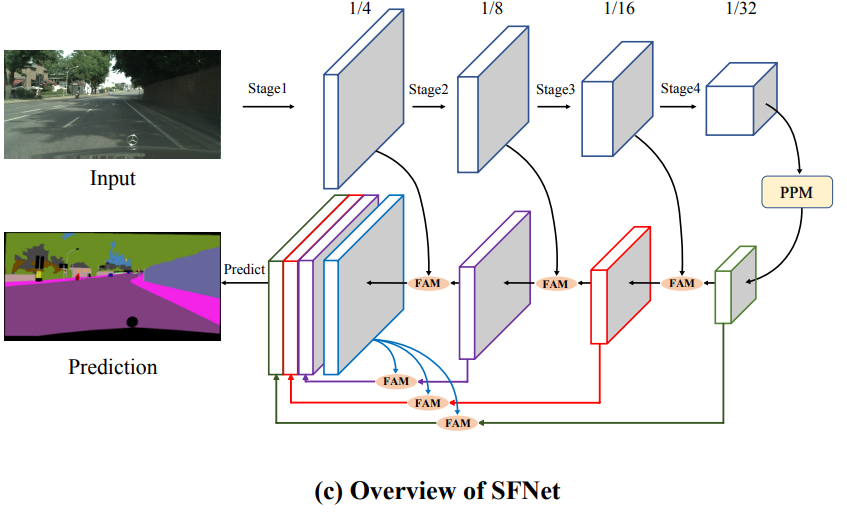
整体架构流程
作者提出的SFNet网络架构形似U型结构,以ResNet-18为骨干网络,包含四个阶段,各阶段通过FAM(Flow Alignment Module,语义流对齐模块)来进行跳跃连接;最深层采用PPM(Pyramid Pooling Module,金字塔池化模块)提供多尺度特性,以下仅介绍FAM相关,PPM学习见文章【Pyramid scene parsing network】。
class SFNet(BaseModel):
def __init__(self, backbone: str = 'ResNetD-18', num_classes: int = 2):
assert 'ResNet' in backbone
super().__init__(backbone, num_classes)
self.head = SFHead(self.backbone.channels, 128 if '18' in backbone else 256, num_classes)
self.apply(self._init_weights)
def forward(self, x: Tensor) -> Tensor:
outs = self.backbone(x)
out = self.head(outs)
out = F.interpolate(out, size=x.shape[-2:], mode='bilinear', align_corners=True)
return out
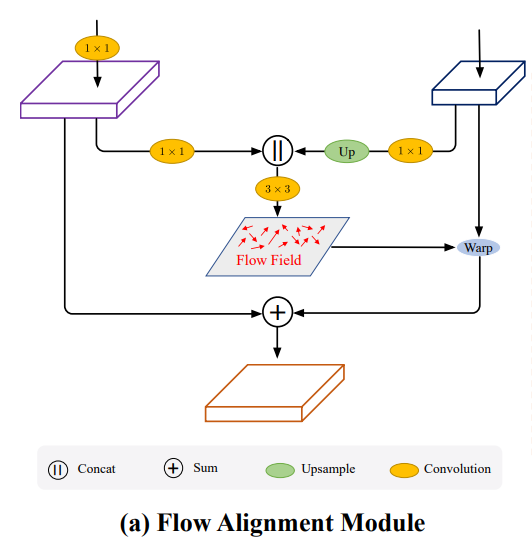
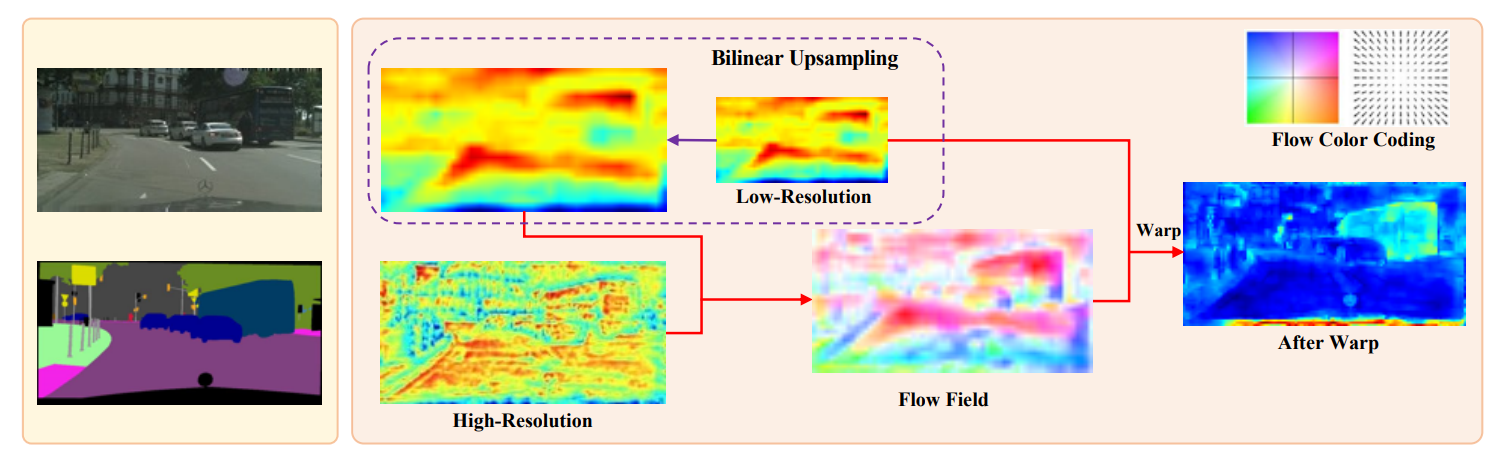
语义流对齐是什么?
如图所示,模型中提取的高分辨率特征图和低分辨率特征图生成语义流场(图中Flow Field),该语义流场用于将低分辨率特征图变换到高分辨率特征图,这个变换过程在图中标记为Warp。
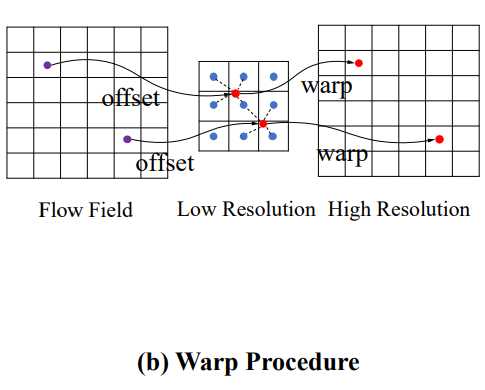
warp过程如图 (b) 所示,特征和光流场之间存在分辨率差距,扭曲后的网格及其偏移量应当按公式2进行缩小。接着,使用空间变换网络 [Spatial transformer networks.] 中提出的可微双线性采样机制,该机制通过线性插值来近似 pl 周围 4 个邻居(左上、右上、左下、右下)的位置,从而获得 FAM 的最终输出。
流对齐代码
FAM 构建在 FPN 框架内,其中每个层次的特征图通过两个 1×1 卷积层压缩到相同的通道深度,然后进入下一个层次。
class SFHead(nn.Module):
def __init__(self, in_channels, channel=256, num_classes=19, scales=(1, 2, 3, 6)):
super().__init__()
self.ppm = PPM(in_channels[-1], channel, scales)
self.fpn_in = nn.ModuleList([])
self.fpn_out = nn.ModuleList([])
self.fpn_out_align = nn.ModuleList([])
for in_ch in in_channels[:-1]:
self.fpn_in.append(ConvModule(in_ch, channel, 1))
self.fpn_out.append(ConvModule(channel, channel, 3, 1, 1))
self.fpn_out_align.append(AlignedModule(channel, channel//2))
................
def forward(self, features: list) -> Tensor:
f = self.ppm(features[-1])
fpn_features = [f]
for i in reversed(range(len(features) - 1)):
feature = self.fpn_in[i](features[i])
f = feature + self.fpn_out_align[i](feature, f)
fpn_features.append(self.fpn_out[i](f))
................
1、PPM 模块的应用
f = self.ppm(features[-1]):首先应用 PPM 对输入特征图的最后一层进行金字塔池化,生成不同尺度的上下文信息。
2、FPN 的特征处理
fpn_features = [f]:将 PPM 的输出存储在一个列表 fpn_features 中。
for i in reversed(range(len(features) - 1))::遍历从倒数第二个特征图到第一个特征图的所有层。
feature = self.fpn_ini:通过 1x1 卷积对每一层的输入特征进行处理。
f = feature + self.fpn_out_align[i](feature, f):将当前特征图与上一层的特征图对齐,并加和,增强特征图的表达能力。
fpn_features.append(self.fpn_outi):将处理后的特征图传入 3x3 卷积后加入fpn_features 列表中。
3、特征图大小对齐
fpn_features.reverse():由于从上到下处理了特征图,所以需要将其顺序反转。
for i in range(1,len(fpn_features)):对每个特征图进行插值,使其大小与第一层的特征图一致。
F.interpolate:采用双线性插值将特征图的大小对齐。
4、特征拼接与处理
output = self.bottleneck(torch.cat(fpn_features,
dim=1)):将所有处理后的特征图沿着通道维度拼接,并通过 bottleneck 进行卷积处理,减少通道数并融合特征。
5、最终分割输出
output = self.conv_seg(self.dropout(output)):将卷积后的特征图传入 Dropout2d 和
1x1 卷积层,最终生成每个像素的分类输出。
对齐过程特征图可视化
特征图通过沿通道维度进行平均来可视化。较大的值用热色表示,较小的值用冷色表示。文章使用(引文2)中提出的颜色编码来可视化语义流场。流向量的方向和幅度分别通过色调和饱和度表示。
模型实践
训练数据准备
提示:云盘代码已内置少量滑坡数据集
训练数据分为原始影像和标签(二值化,0和255),均位于Sample文件夹内,数据相对路径为:
Sample\landslide\train\ IMG_T1
------------------\ IMG_LABEL
----------------\val \ IMG_T1
------------------\IMG_LABEL
本示例中影像尺寸不一,在dp0_train.py文件parser参数项,crop_height 、crop_width设置为256、256,训练数据在CDDataset_Seg定义中进行了resize,模型训练中均为256*256。
模型训练
运行dp0_train.py,模型开始训练,核心参数包括:
| parser参数 | 说明 |
|---|---|
| num_epochs | 训练批次 |
| learning_rate | 初始学习率 |
| batch_size | 单次样本数量 |
| dataset | 数据集名字 |
| crop_height | 训练时影像重采样尺度 |
数据结构CDDataset_Seg定义在utils文件夹dataset.py中,注意读取后进行了数据增强(随机翻转),灰度化,尺寸调整,标签归一化、 one-hot 编码,以及维度和数据类型的转换,最终得到适用于 PyTorch 模型训练的张量。
# 读取训练图片和标签图片
image_t1 = cv2.imread(image_t1_path,-1)
#image_t2 = cv2.imread(image_t2_path)
label = cv2.imread(label_path)
# 随机进行数据增强,为2时不做处理
if self.data_augment:
flipCode = random.choice([-1, 0, 1, 2])
if flipCode != 2:
# image_t1 = normalized(image_t1, 'tif')
image_t1 = self.augment(image_t1, flipCode)
#image_t2 = self.augment(image_t2, flipCode)
label = self.augment(label, flipCode)
label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)
image_t1 = cv2.resize(image_t1, (self.img_h, self.img_w))
#image_t2 = cv2.resize(image_t2, (Config.img_h, Config.img_w))
label = cv2.resize(label, (self.img_h, self.img_w))
label = label/255
label = label.astype('uint8')
label = onehot(label, 2)
label = label.transpose(2, 0, 1)
label = torch.FloatTensor(label)
训练过程如下图所示,模型保存至checkpoints数据集同名文件夹内。
影像测试
运行dp0_AllPre.py,核心参数包括:
| parser参数 | 说明 |
|---|---|
| Checkpointspath | 预训练模型位置名称 |
| Dataset | 批量化预测数据文件夹 |
| Outputpath | 输出数据文件夹 |
数据加载方式:
pre_dataset = CDDataset_Pre(data_path=pre_imgpath1,
transform=transforms.Compose([
transforms.ToTensor()]))
pre_dataloader = torch.utils.data.DataLoader(dataset=pre_dataset,
batch_size=1,
shuffle=False,
pin_memory=True,
num_workers=0)
需要注意,预测定义的数据结构CDDataset_Pre与训练时CDDataset_Seg有区别,此处将其resize回原始尺寸,后续使用自己的数据训练时注意调整。。
结果示例



















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









