






规定时间内达到终点的最小花费

从题目看就应该可以看出这是一个双权重的问题(约束条件有两个,一个是时间限制,一个是cost最小化),与787. K站内最便宜的航班类似。
参考讲解:
Python3 - Modified Djikstra’s
Python modified Dijkstra / hybrid SPFA
This is sort of like Dijkstra on fees, with times “along for the ride”. Typically, Dijkstra stores the result for node u as it pops the next item off the min heap, and then never returns to the same node. In this case, there are three changes:
- We only care about the shortest edge between two vertices in the graph, so when building the graph always take the min weight edge.
- Normally, Dijkstra only adds a neighbor v of the current node u to the queue if u hasn’t been processed before (this is also why Dijkstra can’t handle negative edge weights). However, in our case we have two changes: first, we re-process the node u if the new time is an improvement over the existing time; second, we only add a neighbor if its new_time is within the time constraint.
- Normally, Dijkstra is SSSP and we would need to store intermediate fee values in something like a dictionary. However, this is shortest path between two nodes. Hence, we can use the heap to store our result (which will be the popped fee when u == n - 1).
The algorithm we end up with feels like a hybrid between Dijkstra and SPFA (shortest path faster algorithm, a modified Bellman-Ford). It’s like Dijkstra in that we’re using a heap (and adding an early exit condition because we don’t care about all destinations). But it’s like SPFA in that we only add vertices to the heap if they can contribute to the solution (which means new_time <= maxTime for this problem).
通常,Dijkstra在将下一个项目从最小堆中取出时存储节点u的结果,然后永远不会返回相同的节点。在这种情况下,有三个变化:
- 我们只关心图中两个顶点之间的最短边,所以在构建图时总是取权值最小的边。
- 通常情况下,Dijkstra只会在u之前没有被处理过的情况下,将当前节点u的邻居v加入队列(这也是Dijkstra不能处理负权边的原因)。然而,在我们的例子中,我们有两个更改:首先,如果新时间比现有时间有改进,我们将重新处理节点u;其次,只有在它的new_time在时间限制内时才添加邻居节点。
- 通常,Dijkstra是正权图单源最短路(SSSP),我们需要将中间费用值存储在像字典这样的东西中。然而,这是两个节点之间的最短路径。因此,我们可以使用堆来存储我们的结果(当u == n - 1时,这将是弹出的费用)。
我们最后得到的算法感觉像是Dijkstra和SPFA(最短路径快速算法,一种改进的Bellman-Ford)的混合。就像Dijkstra一样,我们使用堆(并添加早期退出条件,因为我们不关心所有目的地)。但它与SPFA类似,我们只向堆添加顶点,前提是它们对解决方案有贡献(这意味着这个问题的new_time <= maxTime)。
Python modified Dijkstra / hybrid SPFA
class Solution:
def minCost(self, maxTime, edges, passingFees):
n = len(passingFees)
g = collections.defaultdict(list)
for u, v, t in edges:
g[u].append((v, t))
g[v].append((u, t))
times = [0] + [float('inf')] * (n - 1)
q = [(passingFees[0], 0, 0)] # cost, time, node
while q:
cost, time, node = heapq.heappop(q)
if node == n - 1: return cost
for neighbor, t in g[node]:
if time + t < times[neighbor] and time + t <= maxTime:
times[neighbor] = time + t
heapq.heappush(q, (cost + passingFees[neighbor], time + t, neighbor))
return -1
Python3 - Modified Djikstra’s
class Solution:
def minCost(self, maxTime: int, edges: List[List[int]], passingFees: List[int]) -> int:
n = len(passingFees)
g = collections.defaultdict(list)
for u, v, t in edges:
g[u].append((v, t))
g[v].append((u, t))
times = {}
pq = [(passingFees[0],0,0)]
while pq:
cost, node, time = heapq.heappop(pq)
if node == n-1: return cost
for neighbor, t in g[node]:
if (neighbor not in times or times[neighbor] > t + time) and t + time <= maxTime:
times[neighbor] = t + time
heapq.heappush(pq, (passingFees[neighbor]+cost, neighbor, time+t))
return -1
让我在这里解释一下为什么他使用neighbor not in times or times[neighbor] > t + time:
如果没有时间限制的话,这是一个简单的Dijkstra问题。您可以使用visited集合来确保我们以前不会在pq中遇到相同的节点,因为它是怕pq。越往后,数值越大。但在这个问题中是不同的。我们会遇到相同的节点不止一次,只要我们第二次遇到相同的节点,就会用更少的时间。
想象在这种情况下,节点5到节点0的时间成本为10,费用为5,但限制为9,我们跳过这一条。当我们下次遇到节点5时,成本是8,费用是6。虽然它的费用较高,但它是第一个满足时间限制的最小的。如果像我们在简单的Dijkstra场景中所做的那样,在之前的访问中放入节点5,你会跳过这个答案。
另外,我们从来没有在第二次遇到pq时,在时间成本和费用上增加。(这就是if neighbor not in times or times[neighbor] > t + time的意思)所以从pq中弹出的第一个可能不是答案,您需要在pq中推入所有时间成本更小的路径。
在这题中,同一个节点,最多弹出两次。
求最短路
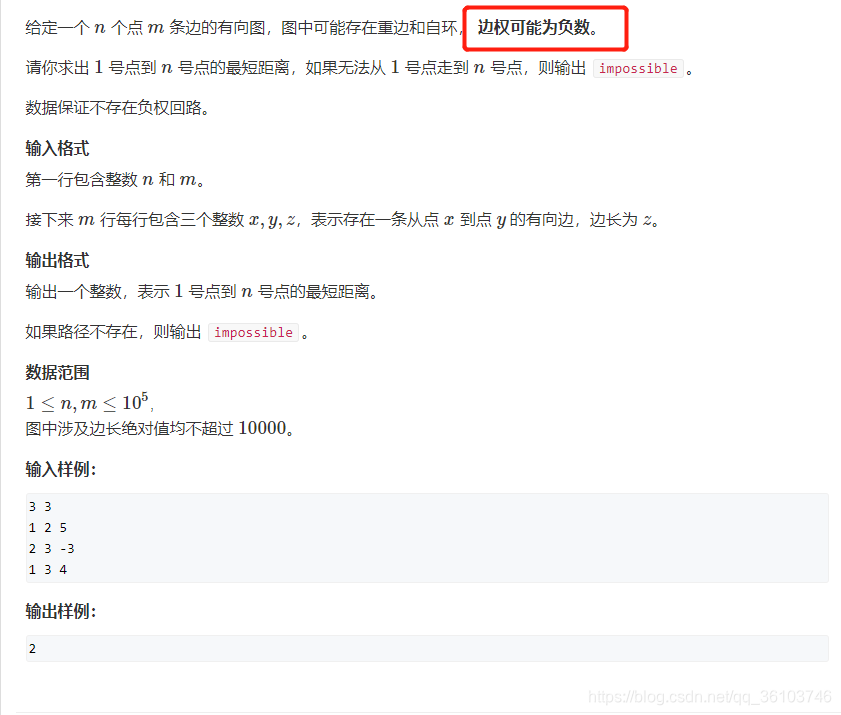
注意该题说明了边权可能存在负值,注意代码的不同之处!!!
# heapq实现spfa
from collections import defaultdict
from heapq import *
n, m = map(int, input().split())
g = defaultdict(list)
for _ in range(m):
u, v, w = map(int, input().split())
g[u - 1].append((v - 1, w))
def spfa(g, n):
weights = [0] + [float('inf')] * (n - 1)
q = [(0, 0)]
while q:
w, cur = heappop(q)
# 如果边权不存在负数,则下面的代码直接return,但存在负数,则不能!!!
# if cur == n - 1: return w
for nex, t in g[cur]:
if weights[nex] > t + w:
weights[nex] = t + w
heappush(q, (w + t, nex))
return str('impossible') if weights[n - 1] == float('inf') else weights[n - 1]
print(spfa(g, n))
# deque实现spfa
from collections import deque, defaultdict
n, m = map(int, input().split())
g = defaultdict(list)
for _ in range(m):
u, v, w = map(int, input().split())
g[u - 1].append((v - 1, w))
def spfa(g, n):
weights = [0] + [float('inf')] * (n - 1)
q = deque([(0, 0)])
while q:
s, cur = q.popleft()
#if cur == n - 1: return s 这里就算不存在负权重,也不能进行return
for nex, cost in g[cur]:
if cost + s < weights[nex]:
weights[nex] = cost + s
q.append((cost + s, nex))
return str('impossible') if weights[n - 1] == float('inf') else weights[n - 1]
print(spfa(g, n))

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









