









 本文深入解析Transformer模型,详细介绍了注意力机制、Encoder和Decoder结构,以及Positional Encoding、MultiHeadAttention、Normalization和Residual Connection等关键组件。Transformer摒弃了传统的RNN结构,仅基于注意力机制构建,提高了长序列计算效率,增强了模型捕捉长期依赖的能力。文章还探讨了编码器和解码器的掩码机制,以及训练过程中的Label Smoothing策略和学习率调整方法。
本文深入解析Transformer模型,详细介绍了注意力机制、Encoder和Decoder结构,以及Positional Encoding、MultiHeadAttention、Normalization和Residual Connection等关键组件。Transformer摒弃了传统的RNN结构,仅基于注意力机制构建,提高了长序列计算效率,增强了模型捕捉长期依赖的能力。文章还探讨了编码器和解码器的掩码机制,以及训练过程中的Label Smoothing策略和学习率调整方法。
最近看了看Transformer,来做一下笔记,代码部分并非我写的,我只是借用解析一下,至于是谁写的我也不太清楚,如果有人知道可以回复我一下,到时候我贴上引用。
文章目录
Attention机制
Seq2Seq也就是序列到序列模型,是用于解决诸如机器翻译,文本摘要,人机对话等问题的一个强力工具,以机器翻译为例它的原理如下
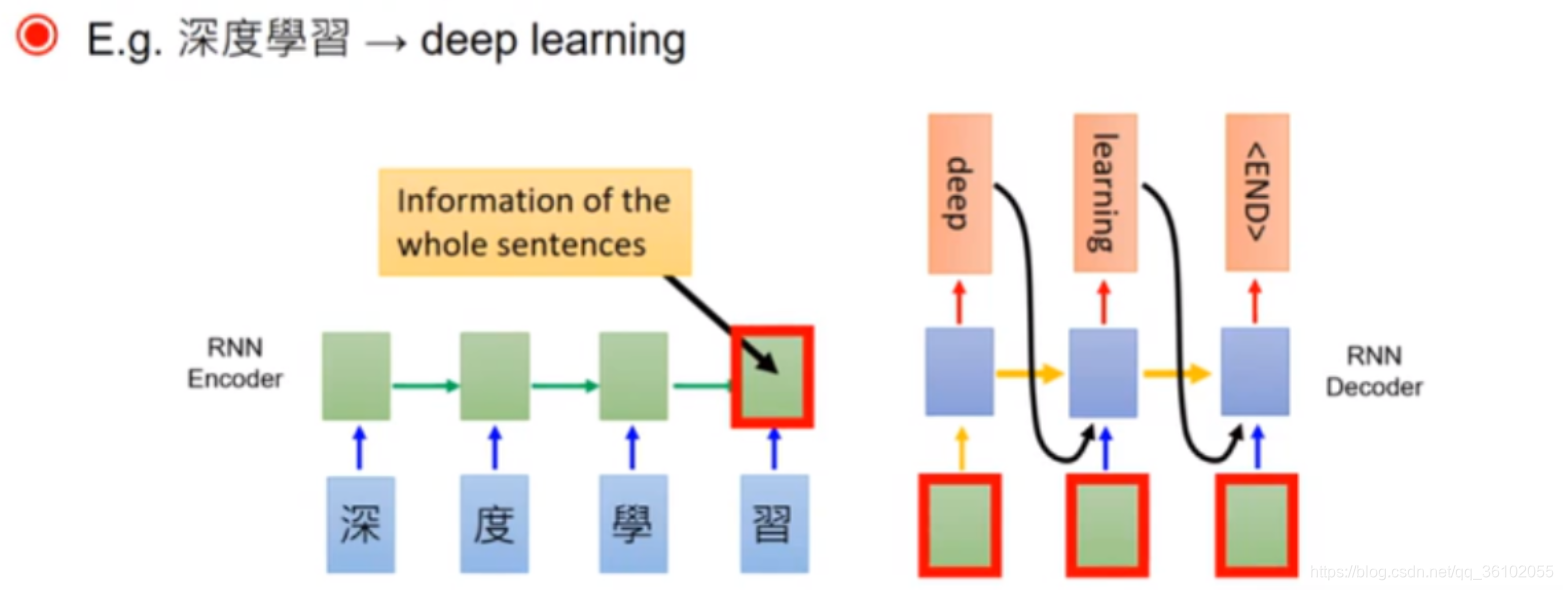
它利用两个RNN,一部分作为Encoder,一部分作为Decoder,分别用于编码序列和解码序列。
首先由encoder依次读入序列得到一个最终的输出,再把这个输出输入给解码器依次解码出最终结果。
可以发现解码过程每次输入由编码器的输出和每一次解码输出的前一个值构成。
Encoder-Decoder的出现解决了Seq2Seq由于输入和输出长度不相等的问题,但是由于Encoder最终输出的大小所限,导致最终传递给Decoder的信息量很有限,这样就使Decoder无法获取到足够的输入序列的信息,也就导致了模型无法在长序列的解码上做出很好的效果。
为了解决这一问题,Attention机制就派上了用场。类似于人在注意特定物体时会忽略其他物体。我们在翻译句子时,对于某一指定的一个短语,我们不会把所有的原文都拿来决定这个短语应该是什么。而是只把原文的几个词拿来翻译。
基于这种思想,我们给Encoder-Decoder加上了Attention。我们在每次进行解码时不仅关注Encoder的最终输出,同时也关注Encoder的每一次输出,并且把它们进行加权,通过不同的权重来表达我们对这些信息的一个关注度。
再拿机器学习举例,首先我们用一个可学习的向量
Z
0
Z^0
Z0和我们的Encoder的每一次输出求一个score
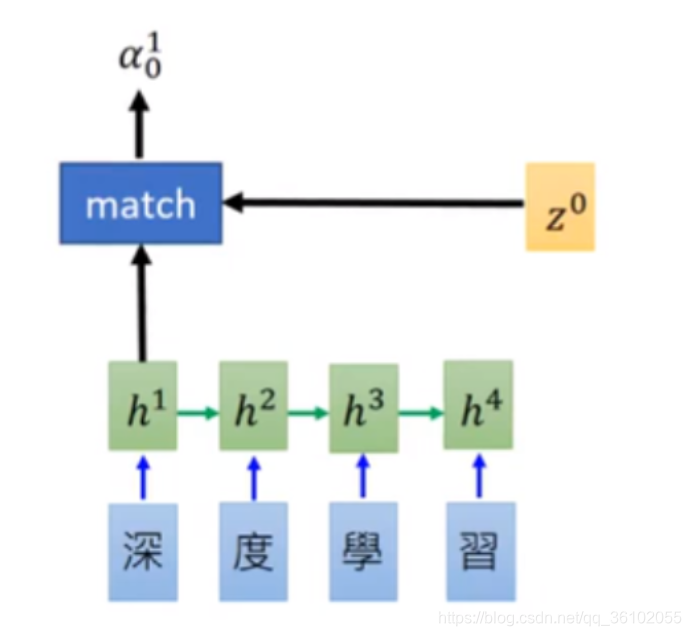
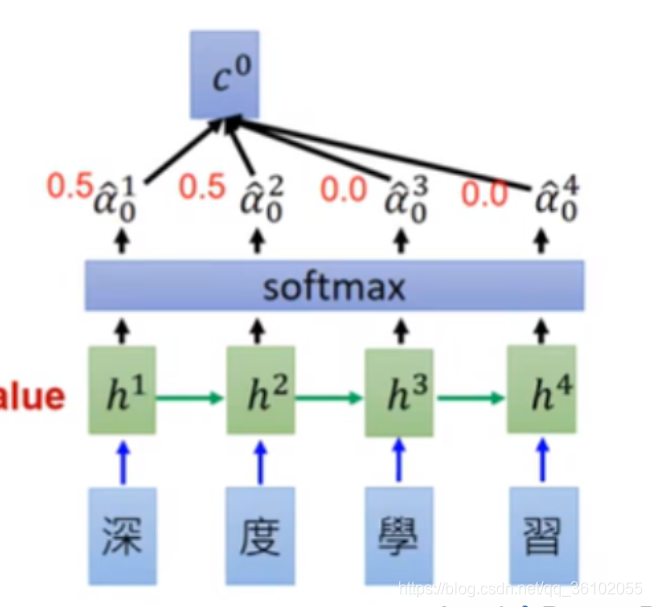
得到这些值之后,我们在做一个softmax,得到他们的权重的分布,最后依据权重分布对Encoder的每一次输出做加权求和得到
c
0
c^0
c0
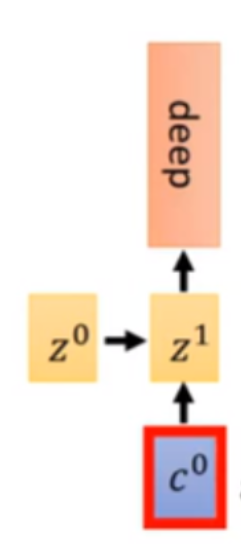
然后我们把
c
0
c^0
c0作为输入送给Decoder,让他和
Z
0
Z^0
Z0相加得到
Z
1
Z^1
Z1然后作为Decoder输入做解码
然后我们就可以把
Z
1
Z^1
Z1当做
Z
0
Z^0
Z0做同样的的事,于是就可以不断地进行解码,同时我们也把前一时刻解码信息作为下一次的输入。
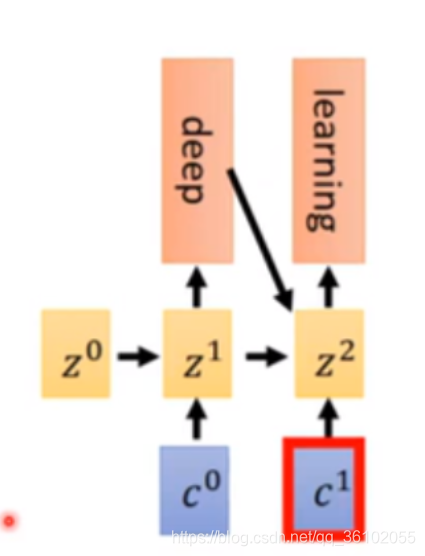
Attention机制的引入使得Encoder-Decoder结构能够捕捉到更长距离的依赖关系。
但是这种结构仍存在着巨大的缺陷:
- 由于RNN本身的限制导致所以在输入长序列时会导致计算时间过长,因为每个词的输入都需要等待上一个词的输出。
- 即使引入了Attention但是捕捉依赖的能力依然有限
这些缺点在Transformer中被进一步的弥补
Transformer结构
Transformer就是变形金刚(不是)。提出Transformer的那篇论文叫做《Attention is all you need》从这个文章的名字就可以知道Transformer抛弃了RNN的结构,纯基于注意力机制做出来这个模型。
同样的Transformer也是Encoder-Decoder结构,论文上的图如下
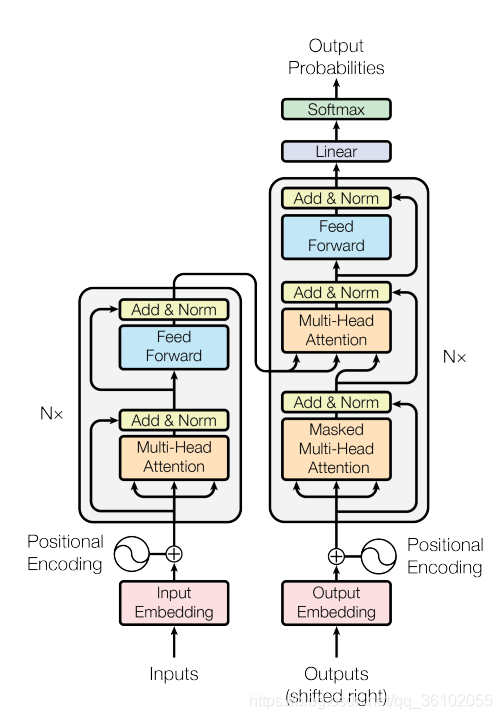
左边输入的那一数列就是Encoder,右边OutPut的那一列就是Decoder。我们从宏观到微观的角度来剖析Transformer的结构。
首先,Encoder和Decoder都是由6个相同的层构成的。
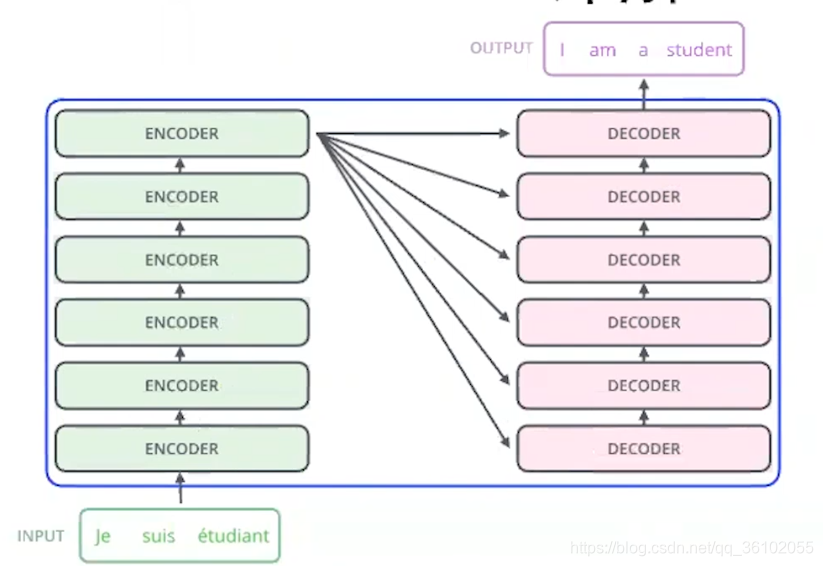
既然每一层都相同,那就说明他们的输入和输出都是相同的,我们把Encoder的每一层叫做EncoderLayer,把Decoder的每一层叫做DecoderLayer。
EncoderLayer
我们再来看EecoderLayer。
每个DecoderLayer都由如下的成分构成
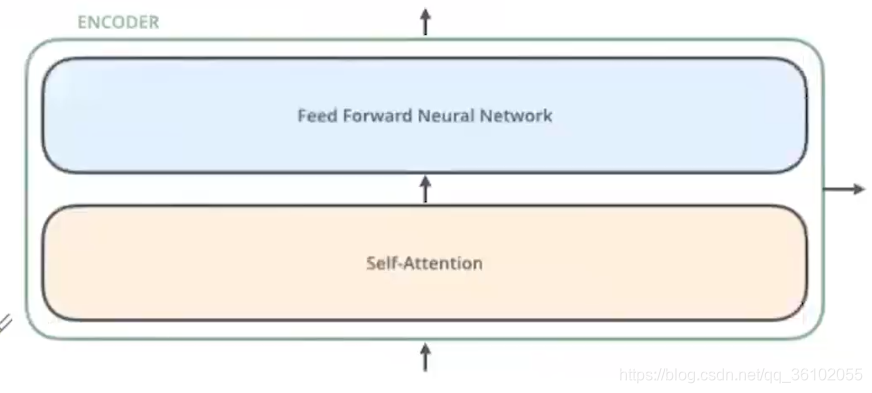
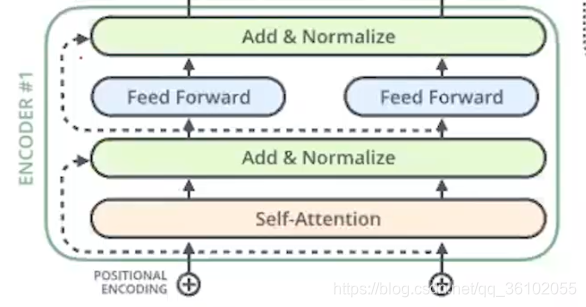
一个是自注意力层也就是self-attention,一个是前馈连接层即Feed Forward Neural Network。
除此外为了加快计算和训练,Transformer又给Encoder层加上了两个残差链接和归一化
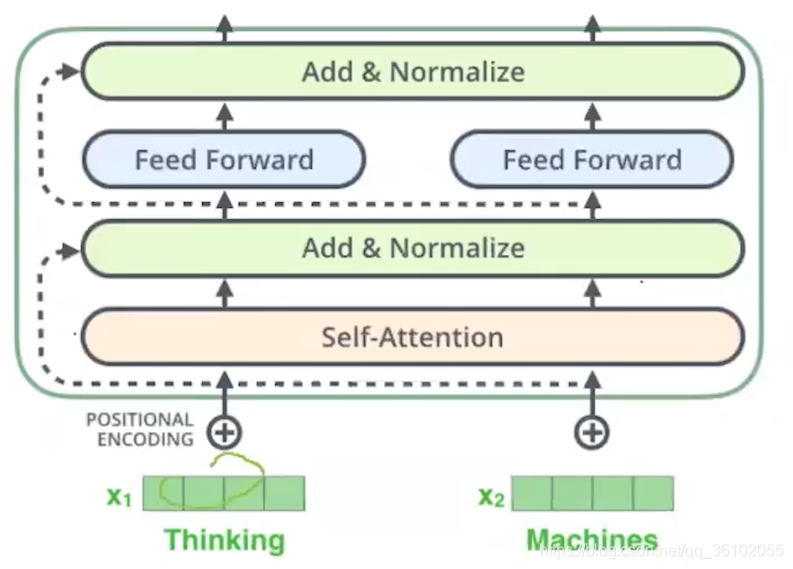
残差链接可以让前面的梯度直接传到后面,从而避免梯度消失加快训练速度。两个残差链接分别加在了:输入到自注意力的输出,自注意力的输出到前馈网络的输出。
在两个残差链接的末尾我们紧接着进行了Normalize,即归一化,以此把均值和方差变成0和1从而加速接下来的计算。到此EncoderLayer的结构就剖析完了
DecoderLayer
DecoderLayer和EncoderLayer很相似,只不过多了一个Encoder-Decoder Attention。
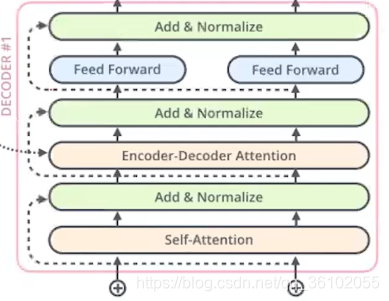
其中self-attention和feed forward,以及归一化和残差连接都和EncoderLayer一致,不过在中间多添加了一个Encoder-DecoderLayer。
它的作用是用于获取Encoder中最终输出的信息,并且结合Decoder中当前已经得到的前一部分的序列的信息。
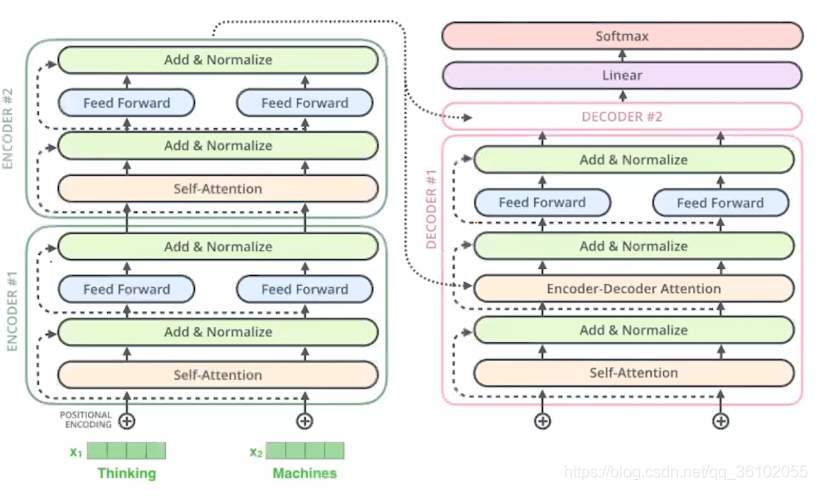
如上图,其最终获得的Encoder信息来自于Encoder的最终输出。
Decoder整体经过若干层,然后再通过一个线性层最后通过Softmax得到对应的输出。
以上就是Transformer的整体结构。
值的注意的是,Transformer的输入并没有体现出一个一个序列元素输入。而是直接把整个序列进行输入。
Position Encoding
我们先来看我们的输入的数据,我们要做一个从英文到中文的翻译任务。假设我们已经做好了数据的处理。现在得到的是 英文: (batch, seq_len), 中文: (batch, seq_len)
我们先导入依赖包
import copy
import math
import matplotlib.pyplot as plt
import numpy as np
import os
import seaborn as sns
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import Counter
from langconv import Converter
from nltk import word_tokenize
from torch.autograd import Variable
我们让英文作为输入数据,中文作为预测数据,然后开始训练。
首先,我们需要把输入数据通过一个embedding层得到对应的词向量。得到之后的矩阵为(batch, seq_len, embedding_size),然后把这个数据输入encoder中,但是再输入之前还需要做一件事,那就是加上位置编码(position_encoding)。
之所以加上位置编码是由于我们的输入进去的序列中的每一个词都是并行的去进行计算的,也就是说没有位置的先后关系。为了体现出位置的前后关系,Transformer的论文中提到了位置编码这种做法
做法
首先需要明确,位置编码是加在输入序列上的,注意这里是加,而不是进行拼接。我们抽出我们的训练数据的一个,得到(seq_len, embedding_size)的矩阵。然后我们沿着seq_len的的方向展开得到

如上图所示,seq_len=3, embedding_size=4。
那我们将来计算出的位置编码也和他们长得一样。

然后我们把他们相加
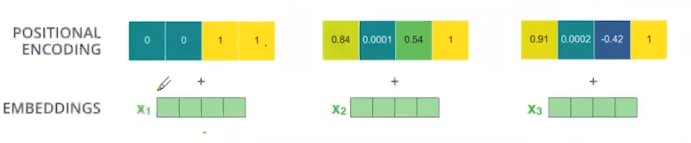
就得到了最终的输入。接下来我们看位置编码究竟如何计算,首先我们定义:

其中,这里的奇数/偶数维度是指我们embedding方向的维度,其大小就为上面的4。于是就有位置编码函数
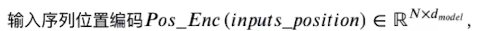
其中
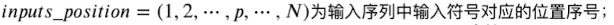
注意这里不要搞混,这个inputs_position是沿着序列的方向,不是embedding的方向,其得到的结果是(seq_len, embedding_size)的矩阵。
Pos_Enc的计算方法为
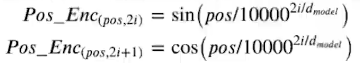
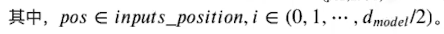
当偶数维度时,我们用第一个式子计算,当奇数维度时我们用第二个式子计算。其中pos为单词的位置,2i和2i + 1为embedding的维度,注意i不是维度,2i和2i + 1才是。
接下来我们就来手算一下第二个单词的position_encoding

首先明确,由于是第二个单词,所以此时pos=1(这里我们从0开始记)
然后我们算偶数维度的值(即i * 2 = 0, i * 2 = 2时)
p
o
s
_
e
n
c
(
1
,
1
∗
0
)
=
s
i
n
(
1
1000
0
0
4
)
=
0.84
p
o
s
_
e
n
c
(
1
,
1
∗
2
)
=
s
i
n
(
1
1000
0
2
4
)
=
0.01
pos\_enc_{(1, 1 * 0)}=sin(\frac{1}{10000^{\frac{0}{4}}})=0.84\\ pos\_enc_{(1, 1 * 2)}=sin(\frac{1}{10000^{\frac{2}{4}}})=0.01
pos_enc(1,1∗0)=sin(10000401)=0.84pos_enc(1,1∗2)=sin(10000421)=0.01
然后是奇数维度的值(即i * 2 + 1 = 1, i * 2 + 1 = 3时)
p
o
s
_
e
n
c
(
1
,
0
∗
2
+
1
)
=
c
o
s
(
1
1000
0
0
4
)
=
0.54
p
o
s
_
e
n
c
(
1
,
1
∗
2
+
1
)
=
c
o
s
(
1
1000
0
2
4
)
=
1.00
pos\_enc_{(1, 0 * 2 + 1)}=cos(\frac{1}{10000^{\frac{0}{4}}})=0.54\\ pos\_enc_{(1, 1 * 2 + 1)}=cos(\frac{1}{10000^{\frac{2}{4}}})=1.00
pos_enc(1,0∗2+1)=cos(10000401)=0.54pos_enc(1,1∗2+1)=cos(10000421)=1.00
最后得到[0.84, 0.54, 0.01,1] (与上图不符,这个无所谓,position_encoding计算方法不唯一,有很多论文提出新的方法)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 位置编码矩阵,维度[max_len, embedding_dim]
pe = torch.zeros(max_len, d_model, device=DEVICE)
# 单词位置
position = torch.arange(0.0, max_len, device=DEVICE)
position.unsqueeze_(1)
# 使用exp和log实现幂运算
div_term = torch.exp(torch.arange(0.0, d_model, 2, device=DEVICE) * (- math.log(1e4) / d_model))
# 由于不管是偶数还是奇数维度其2 * i的值都是(0, 2, 4 , ...)所以我们同一的算出一个向量
div_term.unsqueeze_(0)
# 计算单词位置沿词向量维度的纹理值
pe[:, 0 : : 2] = torch.sin(torch.mm(position, div_term)) # 计算偶数维度上的值
pe[:, 1 : : 2] = torch.cos(torch.mm(position, div_term)) # 计算奇数维度上的值
# 增加批次维度,[1, max_len, embedding_dim]
pe.unsqueeze_(0)
# 将位置编码矩阵注册为buffer(不参加训练)
self.register_buffer('pe', pe)
def forward(self, x):
# 将一个批次中语句所有词向量与位置编码相加
# 注意,位置编码不参与训练,因此设置requires_grad=False
x += Variable(self.pe[:, : x.size(1), :], requires_grad=False)
# 这里加法在batch维度上进行了broadcast
return self.dropout(x)
我们去掉dropout直接返回x,然后初始化一个zero tensor然后输入查看输出结果
x = torch.zeros(size=(1, 3, 4))
pe = PositionalEncoding(4, 0.1, 100)
print(pe(x)[0])
"""
tensor([[ 0.0000, 1.0000, 0.0000, 1.0000],
[ 0.8415, 0.5403, 0.0100, 0.9999],
[ 0.9093, -0.4161, 0.0200, 0.9998]])
"""
与我们计算结果一致
encoder
encoder分为若干个EncoderLayer,他们首尾相连串了起来。我们只需要初始化一个EncoderLayer然后通过deepcopy的方式我们复制出其它五个即可。
首先写出一个clones方法
def clones(module, N):
"""
克隆基本单元,克隆的单元之间参数不共享
"""
return nn.ModuleList([
copy.deepcopy(module) for _ in range(N)
]
那么对于encoderlayer,它的结构如下
那么我们第一个需要实现的就是self-attention
self-attention
我们做好了position_encoding之后我们就得到了(batch, seq_len, embedding_size)的矩阵。接下来我们就需要进行计算self-attention。首先我们来看self-attention是怎么计算的
假设现在我们有两个词

他们对应的有经过位置编码后的两个向量

然后我们创建三个可学习的矩阵Q, K, V
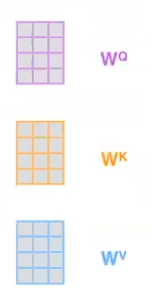
他们的形状都是相同的,都是(embedding_size, k)其中这个k的由来后面继续解释。
使用使用这三个矩阵的目的就是,把我们输入的单词转换为对应的q,k,v向量。
为了实现这一目的,我们只需要让embedding乘以这三个矩阵即可。
(batch, seq_len, embedding) x (embedding, k) = (batch, seq_len, k)
于是我们得到了对应的每个词的q,k,v。
对于一个词,它的q向量表示查询,用于查询别的词和自己的关系,k向量用于被别的词查询。v向量可以看作为这个词的表示。
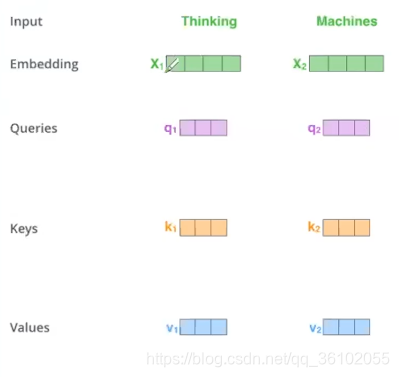
有了这些之后我们就可以做self-attention了,我们以thinking这个词为例子。
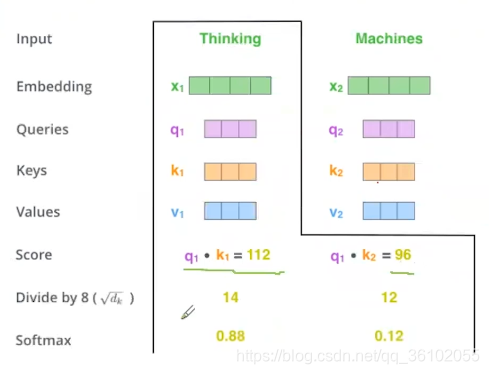
- 我们用thinking的q和所有词的的k做点乘,然后对得到的score,再把所有的score都除以 d \sqrt d d。这里d为embedding_size
- 我们对上述得到的结果做softmax得到每个词的权重
- 随后我们把对应的权重乘以每个词对应的v向量,再求和,最后得到的向量就是Thinking这个词做self-attention的结果
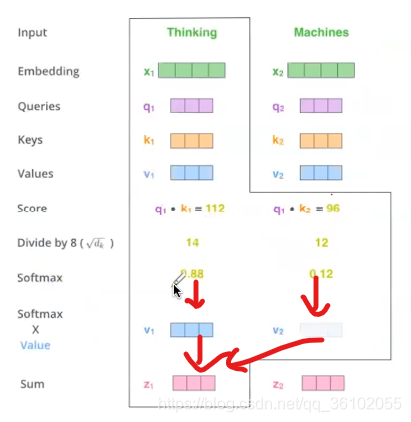
最后所得到的Z1即为thinking的self-attention的结果。同样道理,machines也可以这么做,得到Z2
我们把其转化为矩阵运算,得到
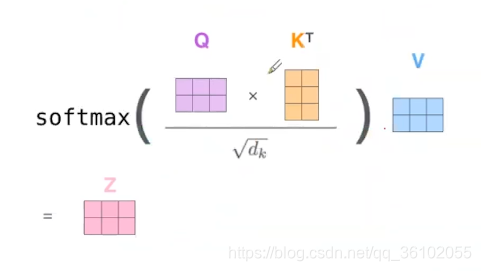
即
Z
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
Z=softmax(\frac{Q K^T}{\sqrt d})V
Z=softmax(dQKT)V
最后得到的这个Z矩阵形状为(batch, seq_len, k)即为我们最后self-attention的结果。
这里说一下为什么要除 d \sqrt{d} d是为了让随后的点积结果通过softmax时更稳定。显然,当数目相同时,除的数越大,通过softmax后得到的权重之间的差异越小。这个可以自己试验一下。
MultiHeadedAttention
除了self-attention,Transformer为了捕捉多重语义,所以引入了MultiHeadedAttention即多头注意力。
所谓的多头注意力即若干个self-attention,我们知道一个self-attention需要一个配套的Q,K,V矩阵,而多个self-attention则需要多个,所以多头注意力只是单纯的扩充了Q, K ,V的数目,但是扩充的Q,K,V并不共享权重。
假设我们使用了八个头,即用了八组Q,K,V,于是就得到
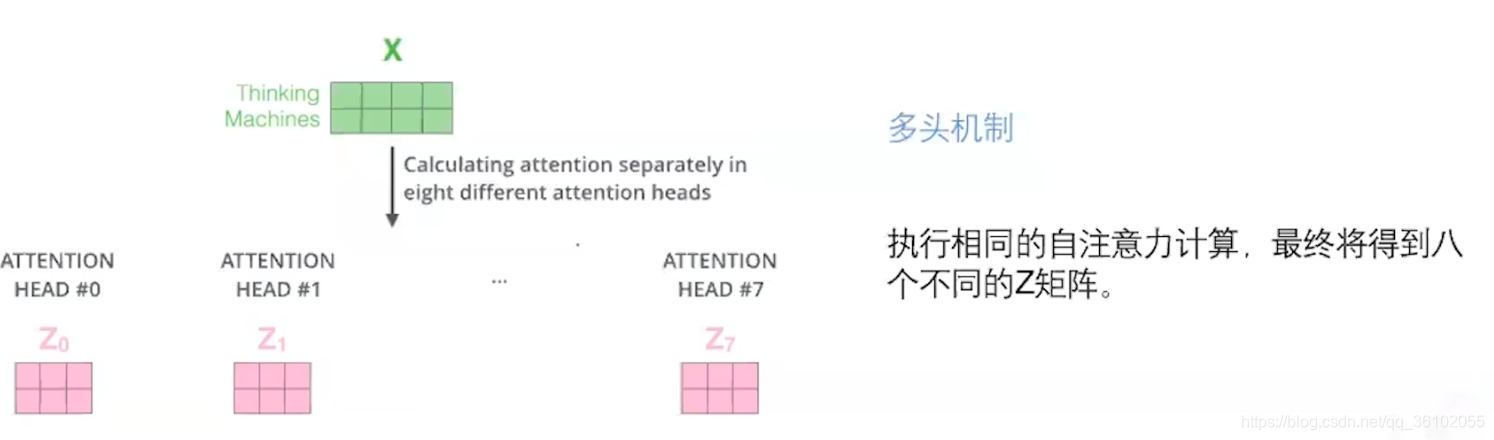
然后我们把这些Z拼接起来
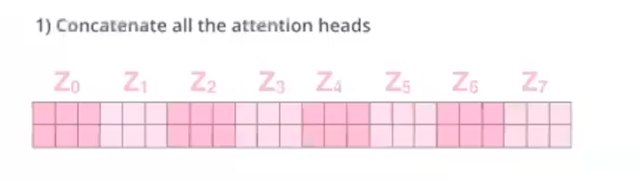
我们把所有的头的结果拼接之后,在通过一个矩阵,把其转换为embedding_size的大小

这样我们就得到了结果Z,这个Z的形状为(batch, seq_len, embedding_size)
最后我们看一下全过程
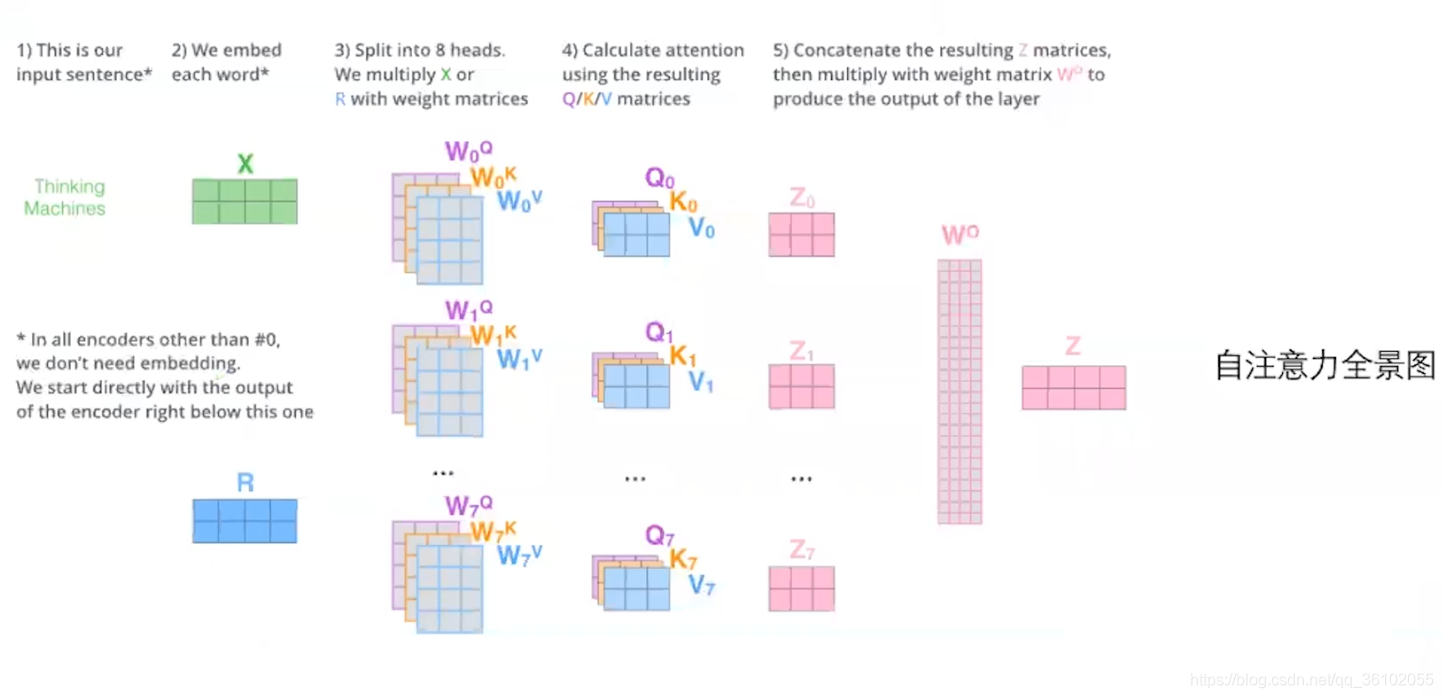
其中X即我们通过embedding的向量,R为位置编码。Z为最终self-attention层的输出。
接下来我们看看代码是怎么写的
首先是单个注意力
def attention(query, key, value, mask=None, dropout=None):
"""
Scaled Dot-Product Attention(方程(4))
输入的query, key, value皆为(batch, h, seq_len, d_k)
"""
# q、k、v向量长度为d_k
d_k = query.size(-1)
# 矩阵乘法实现q、k点积注意力,sqrt(d_k)归一化
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # (batch, h, seq_len, seq_len)
# 注意力掩码机制
if mask is not None:
scores = scores.masked_fill(mask==0, -1e9)
# 注意力矩阵softmax归一化
p_attn = F.softmax(scores, dim=-1)
# dropout
if dropout is not None:
p_attn = dropout(p_attn)
# 注意力对v加权
return torch.matmul(p_attn, value), p_attn # (batch, h, seq_len, d_k), (batch, h, seq_len, seq_len)
然后是多头注意力,这里我们采用Transformer论文中方法,我们让头的数目h,嵌入层大d_model(也就是embedding_size)和value的大小v遵循以下关系
d
_
m
o
d
e
l
=
h
∗
v
d\_model = h * v
d_model=h∗v
class MultiHeadedAttention(nn.Module):
"""
Multi-Head Attention(编码器(2))
"""
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
"""
`h`:注意力头的数量
`d_model`:词向量维数
"""
# 确保整除
assert d_model % h == 0
# q、k、v向量维数
self.d_k = d_model // h
# 头的数量
self.h = h
# WQ、WK、WV矩阵及多头注意力拼接变换矩阵WO
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1)
# 批次大小
nbatches = query.size(0)
# WQ、WK、WV分别对词向量线性变换,并将结果拆成h块
query, key, value = [
l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))
]# 皆为(batch, h, seq_len, d_k)
# 注意力加权
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 多头注意力加权拼接
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k) # (batch, seq_len, embedding_size)
# 对多头注意力加权拼接结果线性变换
return self.linears[-1](x)
这里来解释一下多头注意力的代码
首先看init里面的代码
self.linears = clones(nn.Linear(d_model, d_model), 4)
# 这里是复制了四个(embedding_size, embedding_size)的矩阵
# 前三个分别是Q, K, V的矩阵,后面那个是转换的矩阵
# 因为embedding_size = h * v所以这里前三个每个矩阵都是若干个头叠起来的
再来看forward里,关于mask相关的事情,我们之后再说
query, key, value = [
l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))
]
# 这里的query,key,value都是同一矩阵,也就是经过位置编码和嵌入层的词序列
# 他们通过l后,相当于得到了q,k,v,然后通过view把各个头拆开再交换一下位置
Normalization&ResidualConnection
Normalization
接下来我们进行层归一化(Layer Normalization)这个操作可以使我们的计算结果的某一维度的方差和均值分布在1和0之间。这样可以加快训练的速度。
我们先来看一张图
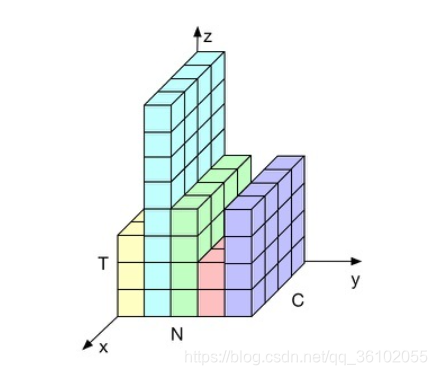
其中X轴方向为词向量的维度,y轴方向为batch维度,z轴方向为seq维度。
那么有三个这样的维度,我们如何进行归一化呢?应该选择哪个维度,进行正则化比较合理呢?
首先看y方向,这个方向最不合理,因为我们沿着这个方向归一化会导致一些没有词的地方也被归一化,这样就会导致哪些有词的位置的值受到没词位置的值的印象,这样必定会导致误差的产生。
再来看其他两个方向,一个是x方向,这个是词向量方向,沿着这个方向归一化好像挺正常的。
另一个沿着z方向,也是可以的,这里给出的解释是,这样沿着句子方向归一化后我可以表示出一个句子的意思。
这里我们采用第二种,即归一化词向量的方式
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
# α、β分别初始化为1、0
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
# 平滑项
self.eps = eps
def forward(self, x):
# 沿词向量方向计算均值和方差
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
# 沿词向量和语句序列方向计算均值和方差
# mean = x.mean(dim=[-2, -1], keepdim=True)
# std = x.std(dim=[-2, -1], keepdim=True)
# 归一化
x = (x - mean) / torch.sqrt(std ** 2 + self.eps)
return self.a_2 * x + self.b_2
由于归一化会导致一些信息损失,所以这里又加上了两个可学习的参数a和b来对损失的信息进行一些弥补。至于归一化的公式,我之前的博客有写过,这里就不再写了。
ResidualConnection
ResidualConnection 即残差连接,残差连接可以让前面的梯度直接绕过某一层传到后面去,这样可以避免由于网络过深导致的梯度消失。
在上图中,虚线即为残残差连接,其实残差连接做法很简单,只需要相加即可,即把后面的层的值直接加到前面去
class SublayerConnection(nn.Module):
"""
通过层归一化和残差连接,连接Multi-Head Attention和Feed Forward
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# 层归一化
x_ = self.norm(x) # 正则化
x_ = sublayer(x_) # 其中sublayer是位于前后残差连接线的中间层
x_ = self.dropout(x_)
# 残差连接
return x + x_ # 直接把结果传到下一层
Feed forward net
在进行归一化和残差连接后,就可以直接送入一个前馈网络了,其中网络的输入维度必须保证和输出维度一致
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.w_1(x)
x = F.relu(x)
x = self.dropout(x)
x = self.w_2(x)
return x
encoder整体代码
有了上述的实现,我们可以拼出一个完整的encoderlayer了
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
"""
size即为embedding_size
这里的self_attn即为MultiHeadedAttention
feed_forward即为全连接层
上面的所有方法都已经在我们上面实现过了,直接实例化然后传入即可。
"""
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
# SublayerConnection作用连接multi和ffn
self.sublayer = clones(SublayerConnection(size, dropout), 2)
# d_model
self.size = size
def forward(self, x, mask):
# 将embedding层进行Multi head Attention
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # 多头注意力上下之间的残差连接
# attn的结果直接作为下一层输入
return self.sublayer[1](x, self.feed_forward) # 前馈网络上下之间的残差连接
然后我们把这样的encoderlayer堆叠起来6个,组成encoder
class Encoder(nn.Module):
def __init__(self, layer, N):
"""
layer = EncoderLayer
"""
super(Encoder, self).__init__()
# 复制N个编码器基本单元
self.layers = clones(layer, N)
# 层归一化
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"""
循环编码器基本单元N次
"""
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
到此,编码器已经全部讲完
decoder
我们再来复习一下解码器的结构
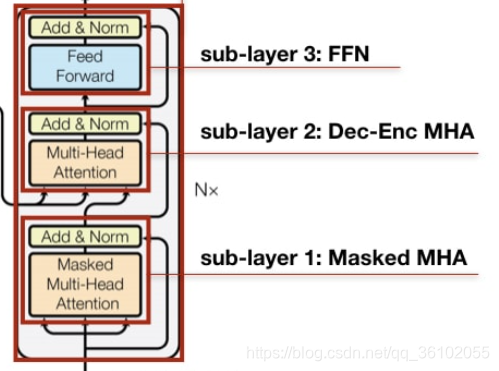
首先是最下面的这个,被称之为masked MHA,即加上掩码的多头注意力,其实就是在数据上做了点手脚,其代码和上面的多头注意力完全一致。
然后就是encoder-decoder注意力,这个其实就是把encoder的最终输出作为key,把decoder的当前query当做查询,然后做多头注意力,本质还是换了换数据,其结构不变。
最后一个前馈网络就不说了,还是一样的。
到了这里我们发现decoder所需要的结构在前面都是先过了,只需要调用即可
decoder实现
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
# 自注意力机制
self.self_attn = self_attn
# 上下文注意力机制
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
# memory为编码器输出隐表示
m = memory
# 自注意力机制,q、k、v均来自解码器隐表示
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# 上下文注意力机制:q为来自解码器隐表示,而k、v为编码器隐表示
x = self.sublayer[1](x, lambda x: self.self_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
这里m是最后encoder的输出,再经过了一个矩阵进行变换后得到的结果,我们用它在获取上下文注意力的key和value。
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
"""
循环解码器基本单元N次
"""
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
由于我们最后输出得到的是词,所以我们还需要把最后的结果通过线性变换到vocabulary大小然后通过softmax
class Generator(nn.Module):
"""
解码器输出经线性变换和softmax函数映射为下一时刻预测单词的概率分布
"""
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
# decode后的结果,先进入一个全连接层变为词典大小的向量
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
# 然后再进行log_softmax操作(在softmax结果上再做多一次log运算)
return F.log_softmax(self.proj(x), dim=-1)
掩码机制
接下来我们来说说Transformer中的掩码机制。其大体可以分为两类。
- 编码器上的注意力掩码
- 解码器上的注意力掩码
编码器掩码
编码器上的掩码即我们的pad上的部分,比如有如下句子
[Anyone, can, do, that, .]
[How, about, another, piece, of, cake]
[She, married, him, .]
他们显然长短不一,此时我们加上一些来进行补齐,并且把句子前后加上BOS, EOS于是得到
[['BOS', 'anyone', 'can', 'do', 'that', '.', 'EOS', '<PAD>', '<PAD>'],
['BOS', 'how', 'about', 'another', 'piece', 'of', 'cake', '?', 'EOS'],
['BOS', 'she', 'married', 'him', '.', 'EOS', , '<PAD>', '<PAD>', '<PAD>']]
由于使我们硬加上去的,所以它并不具有特定的语义,甚至会给模型带来一定的偏差。所以在训练时我们需要使用一些方法把这一部分掩盖掉,这就是编码器掩码。
我们在掩盖时的具体办法就是把这一部分值用0替换掉,这样他们就不会占权重了。
也就是我们希望在做self-attention时,其它单词对他们计算的权重为0。
既然权重为0,那么我们就需要从softmax之前做手脚,我们利用pytorch的masked_fill的方法把所有为pad的地方给复制为-1e9,这样在做完softmax之后就会得到0了。
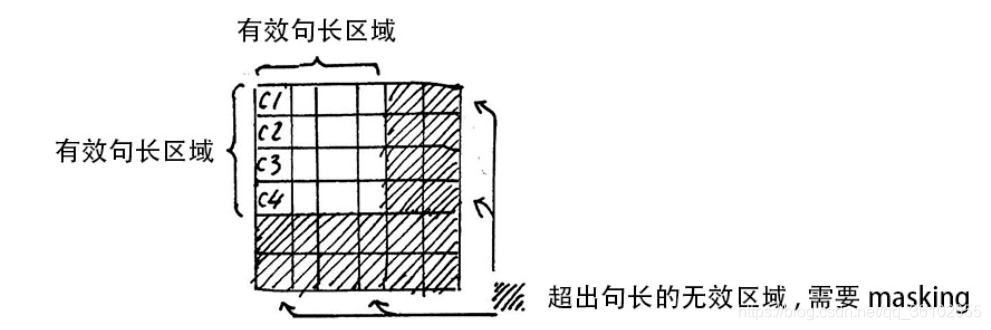
比如第三个句子,做完掩码和softmax后计算出来的score矩阵就是
tensor([[0.0696, 0.3435, 0.2350, 0.1003, 0.0445, 0.2069, 0.0000, 0.0000, 0.0000],
[0.2212, 0.2448, 0.1136, 0.2054, 0.1636, 0.0513, 0.0000, 0.0000, 0.0000],
[0.0943, 0.2362, 0.3986, 0.1347, 0.0965, 0.0397, 0.0000, 0.0000, 0.0000],
[0.0664, 0.0570, 0.2411, 0.4843, 0.1019, 0.0493, 0.0000, 0.0000, 0.0000],
[0.1248, 0.1910, 0.1925, 0.1452, 0.2076, 0.1390, 0.0000, 0.0000, 0.0000],
[0.1909, 0.0326, 0.2673, 0.3830, 0.0396, 0.0867, 0.0000, 0.0000, 0.0000],
[0.1250, 0.2868, 0.1094, 0.1444, 0.3191, 0.0154, 0.0000, 0.0000, 0.0000],
[0.3218, 0.1196, 0.1033, 0.1128, 0.3161, 0.0264, 0.0000, 0.0000, 0.0000],
[0.2035, 0.0814, 0.1306, 0.1901, 0.3765, 0.0180, 0.0000, 0.0000, 0.0000]],
grad_fn=<SelectBackward>)
可以看到后面三个pad的地方的注意力权重为0。
可以发现,下面的三行并没有被mask,这里我认为是最后三行本身就是pad的权重,mask和不mask都不影响,而且即使mask了做完softmax后也不会都是0,反而都是相同的数。
解码器掩码
解码器掩码稍微复杂一点,解码器掩码在编码器掩码之上又加上了一层掩码,这个掩码用于方式训练时真实数据泄露给模型。
我们在进行解码时,是一个一个解码的,也就是在解码的过程中,我们只知道我们前面解码出的句子,后面的我们是不知道的。
比如,对于第一个句子: Anyone can do that.的真实答案是"任何人都可以做到"(这里应该加上EOS和BOS的,我嫌麻烦就没加)
那么机器解码时依次注意到的序列就是
[任何人, masked, masked, masked, masked]
[任何人, 都, masked, masked, masked]
[任何人, 都, 可以, masked, masked]
[任何人, 都, 可以, 做, masked]
[任何人, 都, 可以, 做, 到]
也就是说我们需要生成这样的一个掩码
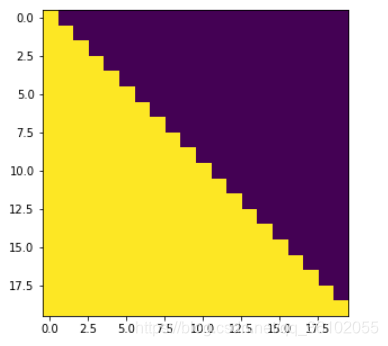
其中黑色部分是掩码,我们把掩码部分和之前的编码器注意力部分进行叠加,就可以得到解码器的掩码了
class Batch:
"""
批次类
1. 输入序列(源)
2. 输出序列(目标)
3. 构造掩码
"""
def __init__(self, src, trg=None, pad=PAD):
"""
scr是原文其形状为(batch, seq_len_1)
trg就是目标值其形状为(batch, seq_len_2)
"""
# 将输入、输出单词id表示的数据规范成整数类型
src = torch.from_numpy(src).to(DEVICE).long()
trg = torch.from_numpy(trg).to(DEVICE).long()
self.src = src
# 对于当前输入的语句非空部分进行判断,bool序列
# 并在seq length前面增加一维,形成维度为 1×seq length 的矩阵
self.src_mask = (src != pad).unsqueeze(-2)
# 如果输出目标不为空,则需要对解码器使用的目标语句进行掩码
if trg is not None:
# 解码器使用的目标输入部分
self.trg = trg[:, : -1]
# 解码器训练时应预测输出的目标结果
self.trg_y = trg[:, 1 :]
# 将目标输入部分进行注意力掩码
self.trg_mask = self.make_std_mask(self.trg, pad)
# 将应输出的目标结果中实际的词数进行统计
self.ntokens = (self.trg_y != pad).data.sum()
# 掩码操作
@staticmethod
def make_std_mask(tgt, pad):
"""
把编码器掩码和下三角矩阵进行叠加
"""
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
def subsequent_mask(size):
"""
产生一个下三角矩阵
"""
"Mask out subsequent positions."
# 设定subsequent_mask矩阵的shape
attn_shape = (1, size, size)
# 生成一个右上角(不含主对角线)为全1,左下角(含主对角线)为全0的subsequent_mask矩阵
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
# 返回一个右上角(不含主对角线)为全False,左下角(含主对角线)为全True的subsequent_mask矩阵
return torch.from_numpy(subsequent_mask) == 0
到此Transformer模型就讲完了,加下来说说训练
训练
label smoothing
关于数据和数据处理包括代码我都放到github上了,想要的可以自己去拿。
训练时我们的LossFunction使用的是KLDivLoss,这个损失函数以KL散度作为评估标准来计算两个分部之间的差异。
之所以用它是因为Transformer中使用了标签平滑技术,每个标签不再是one-hot向量,所以不能用pytorch的cross-entropy来计算
比如原本target的one-hot向量为
[0, 0, 0, 1, 0]
平滑过后可能就变成
[0.05, 0.05, 0.05, 0.8, 0.05]
这里就是简单的把原本one-hot中真实值token的权重拿走一点均分给其它token,这么做可以提高模型的鲁棒性。同时也需要注意在做smoothing时,不能分给pad和EOS,BOS他们权重。
class LabelSmoothing(nn.Module):
"""
标签平滑并计算损失
"""
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction='sum') # 损失函数
self.padding_idx = padding_idx # pad的字典中对应的值
self.confidence = 1.0 - smoothing
self.smoothing = smoothing # 分给其它token的值
self.size = size
self.true_dist = None
def forward(self, x, target):
"""
x 的shape为(num_words, dictionary_size)
y的shape为(num_words)
"""
assert x.size(1) == self.size
true_dist = x.data.clone() # 复制一下x的shape
true_dist.fill_(self.smoothing / (self.size - 2)) # 全部填上均分后的值
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence) # 把分完之后的真实token的值填上去
true_dist[:, self.padding_idx] = 0 # 字典中pad部分为0
mask = torch.nonzero(target.data == self.padding_idx) # 获取所有target上的pad的部分
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0) # 对所有target上pad的部分进行掩码
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False)) # 计算损失
来测试一下这个结果
crit = LabelSmoothing(5, 0, 0.4) # 设定一个ϵ=0.4
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]])
v = crit(Variable(predict.log()),
Variable(torch.LongTensor([2, 1, 0])))
print(crit.true_dist)
"""
OutPut:
tensor([[0.0000, 0.1333, 0.6000, 0.1333, 0.1333],
[0.0000, 0.6000, 0.1333, 0.1333, 0.1333],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000]])
"""
然后就是损失函数
class SimpleLossCompute:
"""
简单的计算损失和进行参数反向传播更新训练的函数
"""
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm):
x = self.generator(x)
loss = self.criterion(x.contiguous().view(-1, x.size(-1)),
y.contiguous().view(-1)) / norm # 两次view是为了转换其到(num_words, dictionary_size)和(num_words)的形状
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
return loss.data.item() * norm.float()
学习率调整策略
这里使用了一个额外的NoamOpt对Adam优化器进行了封装,并且使用了wramup策略来调整学习率
其做法是先让学习率以固定增长率增长,然后再以反平方根比率逐渐下降
l
r
=
d
model
−
0.5
min
(
s
t
e
p
_
n
u
m
−
0.5
,
s
t
e
p
_
n
u
m
×
w
a
r
m
u
p
_
s
t
e
p
s
−
1.5
)
lr = d_{\text{model}}^{−0.5} \min(step\_num^{−0.5}, step\_num \times warmup\_steps^{−1.5})
lr=dmodel−0.5min(step_num−0.5,step_num×warmup_steps−1.5)
其学习率随着每次更新的变化如下图所示
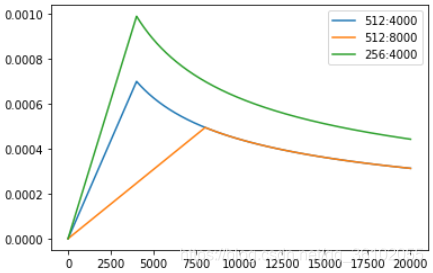
其具体代码如下
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
"""
optimizer是adam优化器
factor为初始的学习率
warmup为warmup_steps
"""
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate # 修改Adam的学习率
self._rate = rate
self.optimizer.step()
def rate(self, step = None): # 计算每一步后的学习率
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * (self.model_size ** (-0.5) * min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
然后就是加载数据,训练。
预测
预测这里主要起作用的是greedy_decode函数,其思路即每次传入decoder之前解码出的词,让它不断地解码一共解码max_len次,然后再用evaluate函数截出有用的部分(EOS)之前的
def greedy_decode(model, src, src_mask, max_len, start_symbol):
"""
传入一个训练好的模型,对指定数据进行预测
"""
# 先用encoder进行encode
memory = model.encode(src, src_mask)
# 初始化预测内容为1×1的tensor,填入开始符('BOS')的id,并将type设置为输入数据类型(LongTensor)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
# 遍历输出的长度下标
for i in range(max_len-1):
# decode得到隐层表示
out = model.decode(memory,
src_mask,
Variable(ys),
Variable(subsequent_mask(ys.size(1)).type_as(src.data)))
# 将隐藏表示转为对词典各词的log_softmax概率分布表示
prob = model.generator(out[:, -1])
# 获取当前位置最大概率的预测词id
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
# 将当前位置预测的字符id与之前的预测内容拼接起来
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
def evaluate(data, model):
"""
在data上用训练好的模型进行预测,打印模型翻译结果
"""
# 梯度清零
with torch.no_grad():
# 在data的英文数据长度上遍历下标
for i in range(len(data.dev_en)):
# 打印待翻译的英文语句
en_sent = " ".join([data.en_index_dict[w] for w in data.dev_en[i]])
print("\n" + en_sent)
# 打印对应的中文语句答案
cn_sent = " ".join([data.cn_index_dict[w] for w in data.dev_cn[i]])
print("".join(cn_sent))
# 将当前以单词id表示的英文语句数据转为tensor,并放如DEVICE中
src = torch.from_numpy(np.array(data.dev_en[i])).long().to(DEVICE)
# 增加一维
src = src.unsqueeze(0)
# 设置attention mask
src_mask = (src != 0).unsqueeze(-2)
# 用训练好的模型进行decode预测
out = greedy_decode(model, src, src_mask, max_len=MAX_LENGTH, start_symbol=data.cn_word_dict["BOS"])
# 初始化一个用于存放模型翻译结果语句单词的列表
translation = []
# 遍历翻译输出字符的下标(注意:开始符"BOS"的索引0不遍历)
for j in range(1, out.size(1)):
# 获取当前下标的输出字符
sym = data.cn_index_dict[out[0, j].item()]
# 如果输出字符不为'EOS'终止符,则添加到当前语句的翻译结果列表
if sym != 'EOS':
translation.append(sym)
# 否则终止遍历
else:
break
# 打印模型翻译输出的中文语句结果
print("translation: %s" % " ".join(translation))
效果
BOS look around . EOS
BOS 四 处 看 看 。 EOS
translation: 看 看 着 。
BOS hurry up . EOS
BOS 赶 快 ! EOS
translation: 快 点 。
BOS keep trying . EOS
BOS 继 续 努 力 。 EOS
translation: 继 续 努 力 。

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









