






chapter 3 Parsing
3.1 context-free grammars 上下文无关文法
正则表达式(regular expression)可以用 DFA (deterministic finite automaton )描述,比如
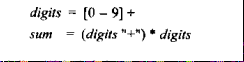
Digits 可以用[0-9]+来替换,sum可以用digits来substitute(替换)就可以得到sum的DFA,但是(however),像下图的expression
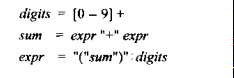
就不能用DFA(deterministic finite automaton) 表示出来,因为他们是 recursive ,递归的,sum用right side替换就是
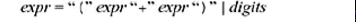
在把exp替换(substitute)
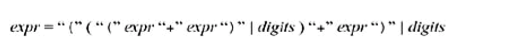
DFA(deterministic finite automaton) 在确定的state(状态)无法匹配出来不定长的expr,即使括号匹配也做不到。正则表达式(regular expression)本身也只能描述specifying 的 lexical token。
于是grammar也描述带有recursive的expression,像下图这种
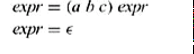
What we have left is a very simple notation, called context-free grammars
For example :
Grammar 3.1
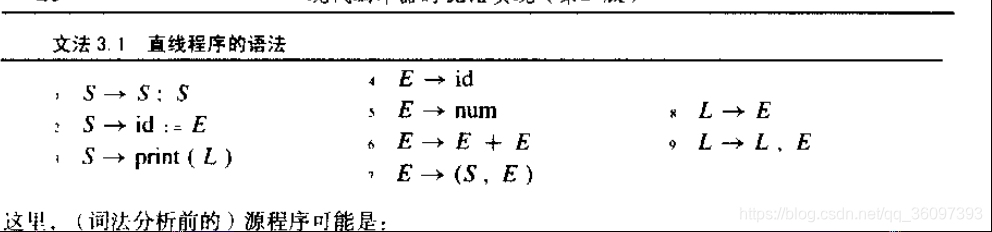
3.1.1 derivation推导
为了判断sentence是否符合grammar,就需要perform a derivation,比如推导( derivation):根据grammar 3.1的 perform a 推导( derivation)
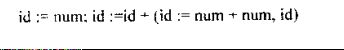

这时候就有 A leftmost derivation (最左推导)and A rightmost derivation (最右推导)
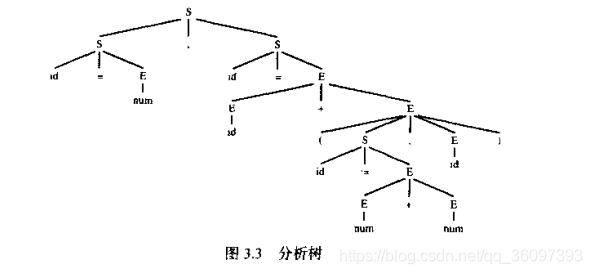
3.1.2 Parse tree
Paser tree是derivation的图形化表示
3.1.3 ambiguous grammar
A grammar is ambiguous If it can derive a sentence with two different parse trees.(如果根据某个文法可以将一个句子推导出两棵及两棵以上语法树,此文法就是二义性文法)
For example grammar 3.5
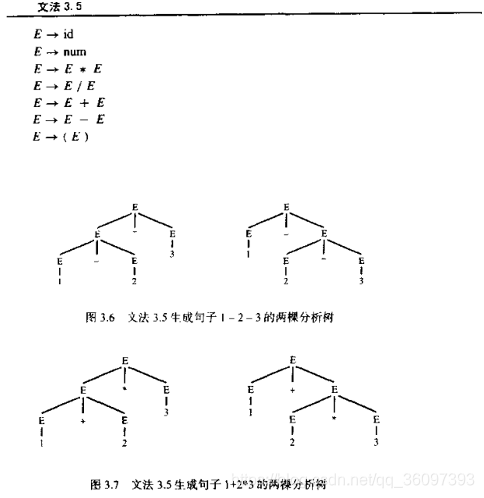
这时候需要加上:
- precedence(优先级)
- each operator associates to the left(左结合)
transforming the grammar 3.5 to grammar3.8
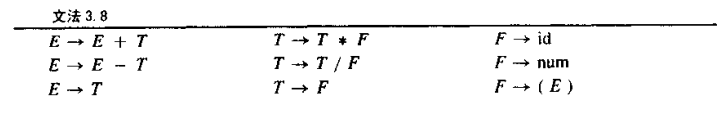
The symbols E, T, and F stand for expression, term, and factor; conventionally, factors are things you multiply and terms are things you add. E是表达式 T是项,F是因子,这样parse tree是左结合,即相同的precedence不会从右边生成
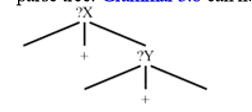
优先级也决定了加minus和乘times同时出现,不会先算加minus,后算乘法times
3.1.4 文件结束符 end od file market
文件结束符EOF标志着一个文件的结束
$ or EOF
重写grammar 3.10
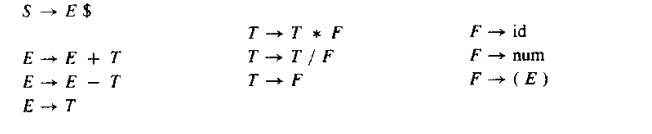
3.2 预测分析 predictive parsing
parser是判断一个sentence 是否符合 Grammar,预测分析(predictive parsing)又叫递归下降分析(recursive-descent parsing)
A recursive-descent parser for this language has one function for each non-terminal and one clause for each production.

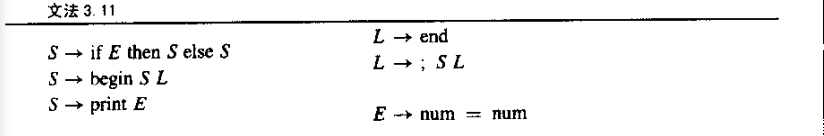
Predictive parser

however,如果是Grammar3.10,switch(token) case what?
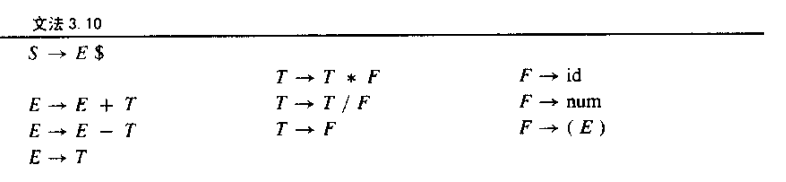

There is a conflict here,不知道 select那个production,如果每个prouction的第一个nonterminal signal能够足够的信息,就可以select 正确的prodction 这时候就要需要FIRST集,提供足够多的信息。
Just as lexical analyzers can be constructed from regular expressions, there are parser-generator tools that build predictive parsers。

此处仅涉及LL(1)grammar
3.2.1 first 和 follow集 FIRST and FOLLOW set


也就是从non-terminal signal开始,derive 出terminal symbols set
伪代码:

Follow set 也是为了derive FIRST_S(产生式右边(the right side of production) 的first set), 因为在修改Grammar的时候容易产生 X-> ε, 所以要知道FIRST(ε)那只要知道X的FOLLOW集合即可
上面提到了 X-> ε,其实有FIRST set之后也有两个conflict
If two different productions X 1 and X 2 have the same lefthand-side symbol (X) and their right-hand sides have overlapping FIRST sets, then the grammar cannot be parsed using predictive parsing. If some terminal symbol I is in FIRST( 1) and also in FIRST( 2), then the X function in a recursive-descent parser will not know what to do if the input token is I.
1. FIRST set has overlapping 就无法know what to do
2. 存在empty string ,我们用nullable记住 可以produce 空字符串(empty string)的non-terminal
依此算出nullable, First 和 Follow set接下来就是construct the Predictive parsing table(预测分析表)
ps:
Given a string of terminal and nonterminal symbols, FIRST( ) is the set of all terminal symbols that can begin any string derived from
FIRST set 的 definition定义了 given treminal or nonterminal symbols,derive的所有可能的
Non-terminal 的set
3.2.2 构造一个预测分析集 constructing a predictive parser
预测分析器(predictive parser)就是基于下一个token (based on the next token) chose 相应的production对应的clause(子句),也就是switch(token)case what: do what;
这之前提到的FORST set要提供我们chose right production 的 infromation, 我们把information encode成 a two-dimensional table of productions

类似于华保健讲的FIRST_S,当production X --> γ ,FIRST(γ)构成列,也就是non-terminal的first 遇到的 terminal symbol,比如First(b) = {c},但是,如果γ是 nullable的话,就接受所有的terminal symbol,
有个问题:Y --> ε为什么接受每个terminal(不是接受每个terminal signal),
因为华保健老师的课上讲过,下面绿框框,FISTR(p)U= FOLLOW(N)

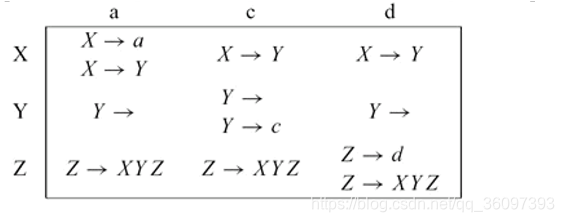
这个表有 多重入口(duplicate entries),也无法正确选择 which production,
我们必须消除duplicate entries 当然还有二义性,这样就符合LL(1) grammar,也可以用 recursive-descent (predictive) parser 进行 parse
ps 这才是LL(1)文法的definition
如何消除多重入口(duplicate entries),就有
3.2.3 消除左递归 Eliminating left Recursion
3.2.4 左因子 left factoring
无论是消除左递归(elimating left recursion)还是 提取左因子(left factoring),貌似都会引入 X ->ε
3.2.3 消除左递归 Eliminating left Recursion

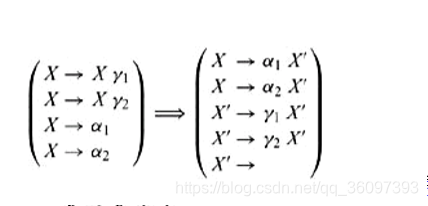
3.2.4 左因子 left factoring

3.2.5 出错恢复 ERROR RECOVERY
This can proceed by deleting, replacing, or inserting tokens.
可以通过删除,替代 和 插入

















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









