



 本文探讨了目标检测中常用的传统anchor机制的问题,并提出了一种新的机制——Guided Anchor RPN(GA-RPN),该机制能够自动生成适合物体的候选框,解决了传统机制中需要预先设定大量不同尺寸和长宽比的anchors所带来的效率低下问题。
本文探讨了目标检测中常用的传统anchor机制的问题,并提出了一种新的机制——Guided Anchor RPN(GA-RPN),该机制能够自动生成适合物体的候选框,解决了传统机制中需要预先设定大量不同尺寸和长宽比的anchors所带来的效率低下问题。
该论文首先指出了之前常用的在feature map上平铺anchors这一方法的一些缺点:
(1)必须为不同的问题事先定义长宽比(aspect ratio)不同的anchor以及他们的尺寸,实际上很难做到设计得恰到好处
(2)为了保证建议区域的准确性,需要使用大量的anchors,这其中不少anchors最终是无用的,还消耗了大量的计算资源,效率太低(方法在特征图上做滑窗,生成几千个Anchor。可是一张图片的物体也就几个而已,这导致负样本过多)。
论文中给出如下的一个·假设公式,I表示输入的图片,(x,y,w,h)用以表示框住object的框的位置,大小。该公式直观上可理解为:(1)给定某张图片,object只可能在其中某几个部分出现 (2)某个object的长宽跟该object的位置有关
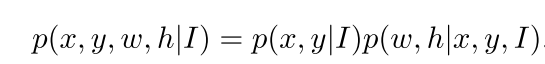
以此作为指导思想,论文中提出了如下结构:
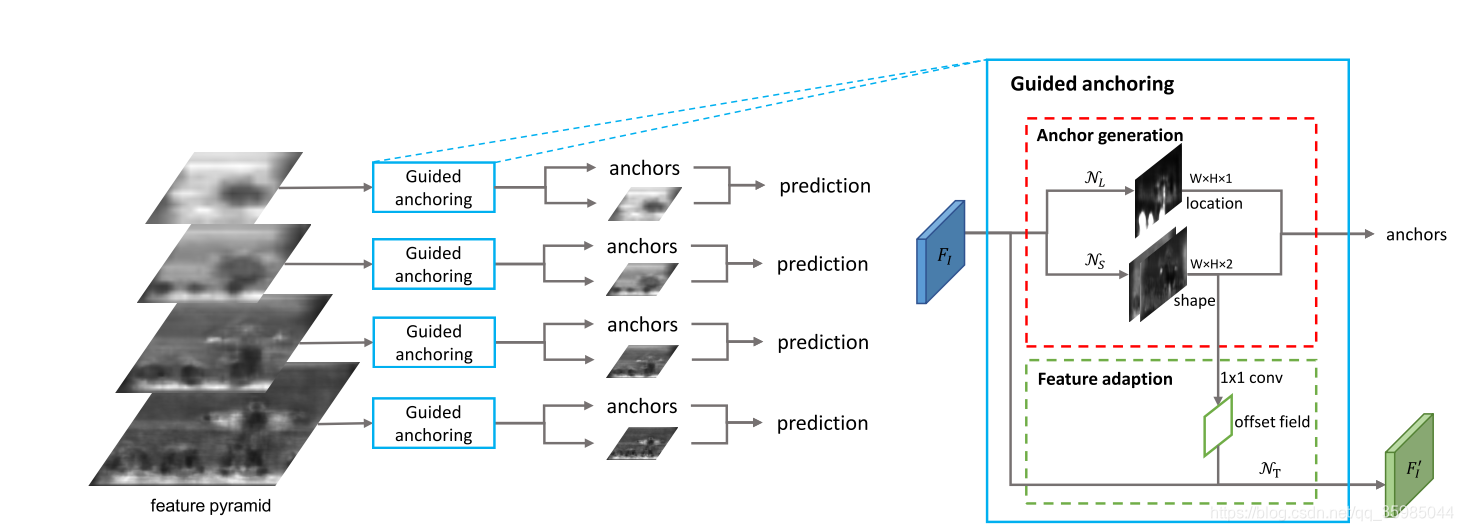
图中的红色虚线包裹部分的两个分支分别用于生成object的坐标和大小。其中loacation prediction分支生成一个和输入的festure map F_I 大小一样的prediction map,图中每个点的值代表了对应特征图上的点存在目标的概率。然后设定一个阈值,存在object的概率度大于此阈值,则被认为可能有object,则利用该点的坐标信息和shape prediction分支预测的object的长宽信息来生成anchor(shape prediction的prediction map有两个通道,分别表示对长和宽的prediction。
具体的预测方案:
(1)坐标预测
每个p(i, j | FI)对应图像I的坐标((i + 0.5)s, (j + 0.5)s),其中s是feature map的步长,即feature map相比于原图下采样了多少倍,这样的话其实也可以理解为原图上相邻anchor之间的距离。论文为了得到这个概率预测图,先对feature map使用1x1卷积,然后对每个元素使用sigmoid函数从而转换为概率值。虽然可以用更深的网络得到更深的准确率,但是论文中提到这样做已经比较好地平衡了计算量和准确率。
(2)大小预测
由于w,h取值范围较大,故文中预测的是dw,dh,其表达式如下所示:
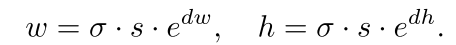
论文中说该变换大约能将预测空间从[0,1000]变到[-1,1],具体用的也是1*1卷积。
由于每个位置的形状不同,大的anchor对应较大感受野,小的anchor对应小的感受野。故该论文并不像传统的方法那样直接对feature map进行卷积来预测,而是要对feature map进行feature adaptation。作者利用变形卷积的思想,根据形状对各个位置单独进行转换:
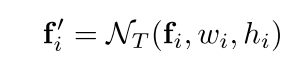
其中,fi是第i个位置的特征,(wi, hi)是对应的anchor形状。N_T通过3*3的deformable卷积实现。首先通过形状预测分支预测offset field,然后对带偏移的原始feature map做变形卷积获得adapted features。之后进一步做分类和bounding box回归。具体地还是另外了解deformable卷积和具体的实现代码才好理解。
同时,论文采用multi-task损失函数,其表达式如下;
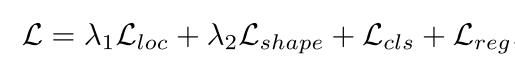
(1) anchor location loss
上式第一部分为anchor的坐标损失。论文希望中心附近的anchor数目多一些,而远离中心的anchor数目应该少一些,为此原论文定义了三种区域:
a.定义中心区域CR=R(x’g, y’g, σ1w’, σ1h’),CR区域内的像素标记为正样本;
b.定义ignore区域IR=R(x’g, y’g, σ2w’, σ2h’)\CR(σ2 > σ1),ignore区域是一个更大的区域除掉CR这个区域后得到的,该区域的像素标记为ignore;
c.其余区域标记为外部区域OR,该区域所有像素标记为负样本。
由于论文模型基于FPN结构,有多层尺寸不同的feature map,所以只有当feature map与目标的尺度范围匹配时才标记为CR,而临近层相同区域标记为IR,就如下图所示:

每个ground truth都含有这三种区域,正如上面所说,其中位于CR的点(上图的绿色区域)我们认为是正样本所在的点,就用它们来生成anchor(最好能生成上图的红色和蓝色方框基本差不多的矩形)。而黄色区域的点我们则直接忽略,不用它来生成anchors。当多个物体重叠时,CR可以控制IR, IR可以控制OR。由于CR通常只占整个特征图的一小部分,所以论文使用focal loss来训练loaction prediction分支。
(2)anchor shape
之前的方法由于anchor是预设的,所以可以很自然地可以直接计算anchor和真值的IoU,从而选取样本。但如今论文里的anchor是不定的,无法通过传统的方法计算。为此,论文提出了变化的anchor:a_wh = {(x0, y0, w, h)|w > 0, h > 0}和ground truth的框gt : (xg, yg, wg, hg)之间的IoU,又称为vIoU:
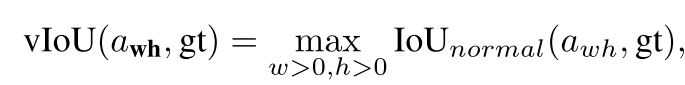
当然,实际过程中计算上式是很麻烦的,因此论文采用采样估计的方法。文中采样一般采9个点。
最后L_shape采用smooth L1 loss的形式,表达式如下:
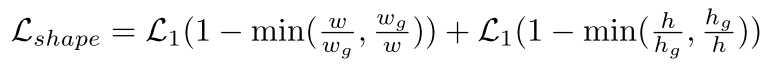
最后还要注意GA-RPN的使用:直接将RPN替换为GA-RPN,对最后的结果提升不明显。由于GA-RPN产生的proposal位置更加准确,所以需要提高IoU阈值,这样使得模型性能更好。

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









