






1.参考
(1)论文:https://arxiv.org/pdf/2406.17680
(2)代码:https://github.com/KargoBot_Research/UAD
2.摘要
提出 UAD,一种基于视觉端到端的自动驾驶算法。在nuScenes中实现最佳的开环评估性能,同时在CARLA仿真平台中展现出稳健的闭环驾驶性能。发现目前的方法仍然模仿典型驾驶栈中的模块化架构,通过精心设计的监督感知和预测子任务,为定向规划提供环境信息。之前的方法有两大缺点,第一是需要大量的精细的3D标注,第二是每个子模块在训练与推理都需要大量计算开销。提出的UAD,是一种非监督的方法。首先,我们设计了一种新的角度感知预文本来消除标注需求。通过预测角度方向的空间对象性和时间动态来模拟驾驶场景,而无需手动标注。其次,提出了一种自监督训练策略,该策略学习不同增强视图下预测轨迹的一致性,以提高转向场景中的规划鲁棒性。
UAD在nuScenes中的平均碰撞率比UniAD提高了38.7%,在CARLA的Town05Long基准测试中的驾驶分数比VAD提高了41.32分。此外,所提出的方法只消耗了UniAD 44.3%的训练资源
推理速度提高了3.4倍。创新设计不仅首次展示了与监督对手相比无可争议的性能优势,而且在数据、训练和推理方面也具有前所未有的效率。
3.介绍
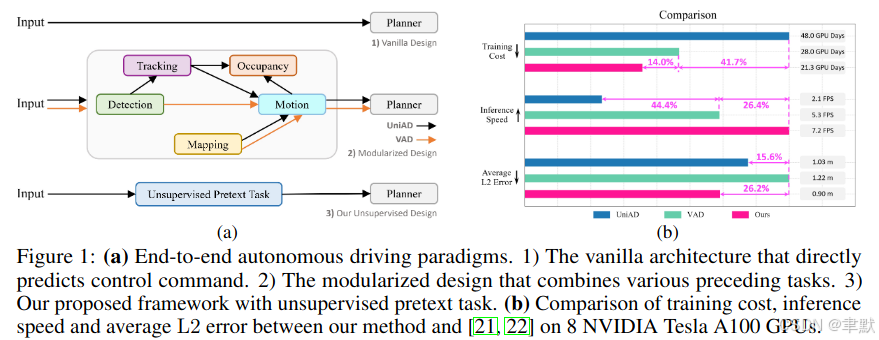
通过Tranformer结构,将每个任务无缝连接。但是需要消耗较多的GPU,而且推理速度很慢。而且需要高质量标注。人工标注的财务开销严重阻碍了这种具有监督子任务的模块化方法利用大量数据的可扩展性。
值得注意的是,本文方法完全消除了感知和预测的标注要求。对于具有复杂监督模块化的当前方法来说,这种数据效率是无法实现的。通过将2D感兴趣区域(ROI)从现成的开放集检测器投影到BEV空间来获得对学习空间对象性的监督。在使用公开可用的openset 2D检测器并使用其他领域的手动注释进行预训练时(例如COCO[27]),我们避免了在我们的范式和目标领域(例如nuScenes和CARLA)中需要任何额外的3D标签,从而创建了一个实用的无监督设置。
贡献:
(1)提出了一个无监督的育文本任务,以放弃端到端自动驾驶中3D手动标注的要求,这可能使将训练数据扩展到数十亿级而不会出现任何标签过载变得更加可行。
(2)引入了一种新的自监督方向感知学习策略,以最大限度地提高不同增强视图下预测轨迹的一致性,从而增强转向场景中的规划鲁棒性。
(3)与其他基于视觉的E2EAD方法相比,我们的方法在开环和闭环评估方面都显示出优越性,计算量和标注量要低得多。
4.相关工作
(1)端到端自动驾驶:1988 ALVNN提出时就能驾驶一辆车行驶400米。NEAT, P3 ,MP3, ST-P3利用高精地图和BEV分割方法提高驾驶鲁棒性。UniAD和VAD利用Transformer和占用预测在开环评估上有较好性能。本文使用非监督方法无需3D标注,取得超出监督方法的性能。
(2)世界模型:MILE将环境视为一种高级嵌入,并倾向于通过历史观测来预测其未来状态。Drive WM提出了一个框架,将世界模型与现有的E2E方法相结合,以提高规划的稳健性。在这项工作中,我们提出了一种针对我们无监督预文本的自回归机制,以捕捉每个扇区内的角度时间动态。
5.方法
(1)Angular Perception Pretext旨在以无监督的方式将E2EAD从昂贵的模块化任务中解放出来;(2)方向感知规划,学习增强轨迹的自我监督一致性。
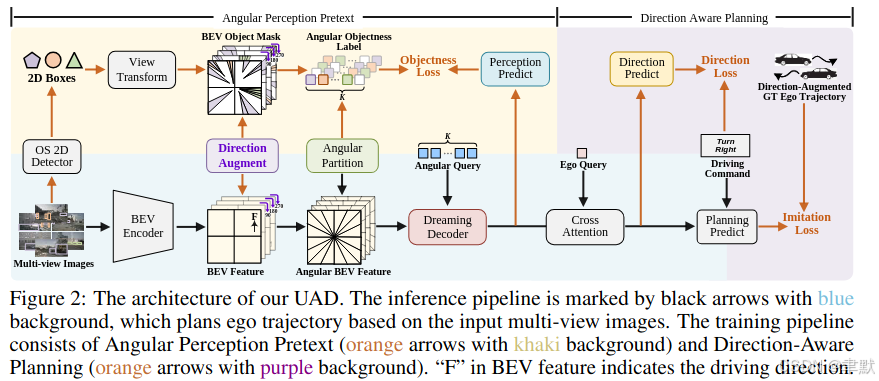
5.1 角度感知预文本
(1)空间表征学习:我们的模型试图通过预测BEV空间内每个扇区区域的对象性来获取驾驶场景的空间知识。具体来说,以多视图图像{Ii∈RHi×Wi×3}为输入,BEV编码器[25]首先将视觉信息提取到BEV特征Fb∈RHb×Wb×C中。然后,Fb被划分为以自我车为中心的K个具有均匀角度θ的扇区。每个扇区都包含BEV空间中的几个特征点。将一个扇区的特征表示为f∈RN×C,其中N是所有扇区中特征点的最大数量,我们推导出角BEV特征Fa∈RK×N×C。零填充应用于少于N个点的扇区。在没有深度信息的情况下,BEV空间中与2D图像中的ROI对应的区域是一个扇区。
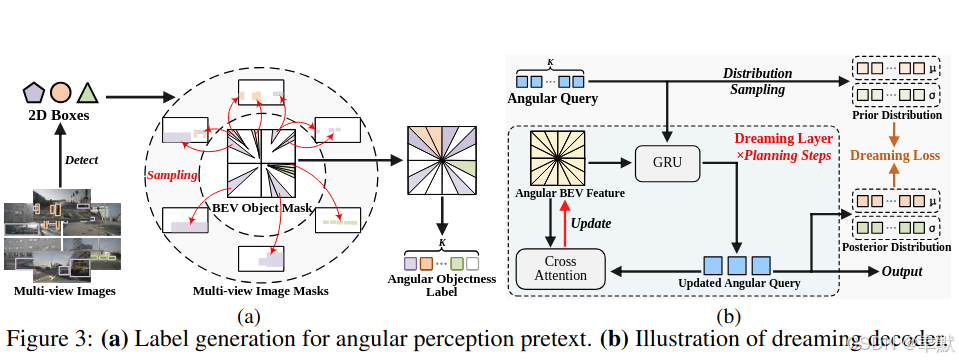
待补充。
6.实验
数据集:NuScences
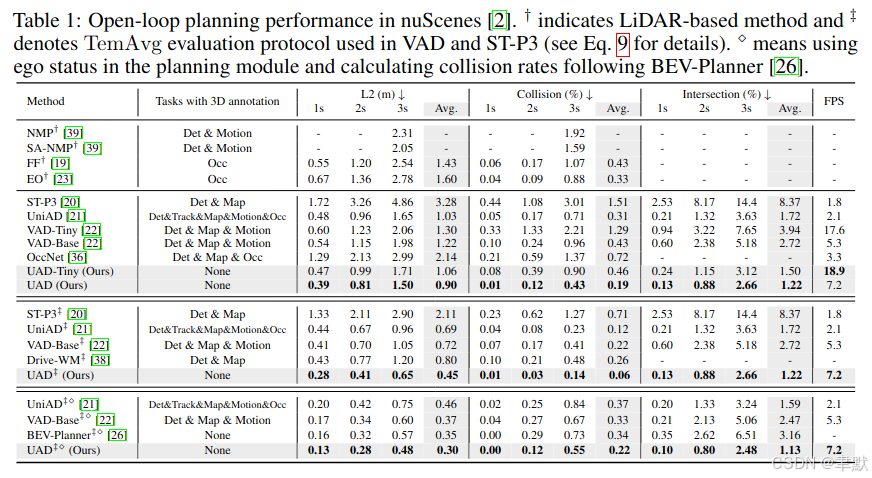
消融实验:
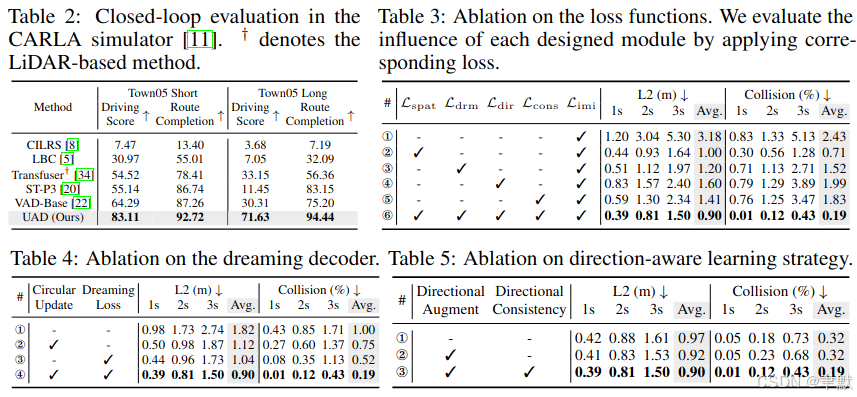
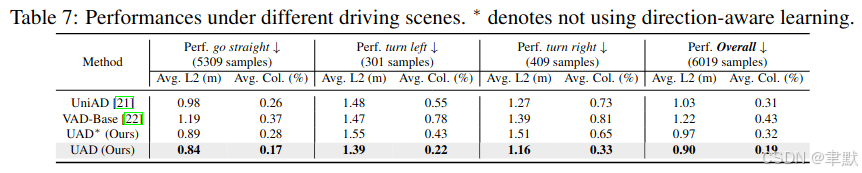
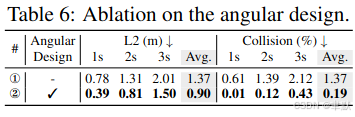
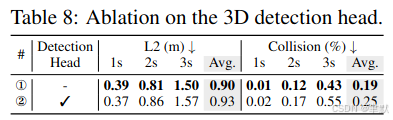
可视化:
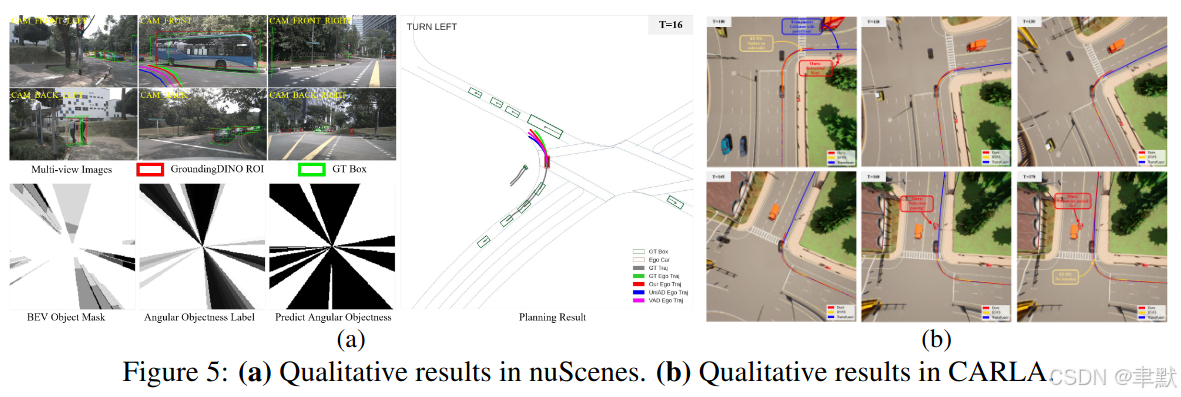
7.结论
我们的工作旨在将E2EAD从昂贵的模块化和3D手动标注中解放出来。为了实现这一目标,我们提出了无监督的预文本任务,通过预测角度方向的物体性和未来的动态来感知环境。为了提高转向场景的鲁棒性,我们引入了方向感知训练策略进行规划。实验证明了我们方法的有效性和效率。



















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











