







 本文探讨了消息队列(MQ)在系统解耦、异步处理和削峰填谷中的关键作用,同时深入分析了MQ带来的系统复杂性和潜在问题,如可用性降低、数据一致性挑战等,并提供了相应的解决方案。
本文探讨了消息队列(MQ)在系统解耦、异步处理和削峰填谷中的关键作用,同时深入分析了MQ带来的系统复杂性和潜在问题,如可用性降低、数据一致性挑战等,并提供了相应的解决方案。
为什么使用消息队列?
解耦、异步、削峰
其实这个话题也是面试官经常问询的问题,问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么
期望的一个回答是说,你们公司有个什么业务场景,这个业务场景有个什么技术挑战,如果不用MQ可能会很麻烦,但是你现在用了MQ之后带给了你很多的好处
现在你可以下想想你如何回答上述问题,想不起来? 好吧我这里先介绍几个常见使用场景,提醒下。。。
解耦:现场画个图来说明一下,

A系统发送个数据到BCD三个系统,接口调用发送,那如果E系统也要这个数据呢?那如果C系统现在不需要了呢?现在A系统又要发送第二种数据了呢?A系统负责人濒临崩溃中。。。再来点更加崩溃的事儿,A系统要时时刻刻考虑BCDE四个系统如果挂了咋办?我要不要重发?我要不要把消息存起来?头发都白了啊。。。

这是你需要去考虑一下你负责的系统中是否有类似的场景,就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,如果用MQ给他异步化解耦,也是可以的,你就需要去考虑在你的项目里(做过微服务项目的同学这里是不是考虑下 消息总线 搭配Rabbitmq 做解耦 用于广播配置文件的更改或者服务间的通讯?),是不是可以运用这个MQ去进行系统的解耦。在简历中体现出来这块东西,用MQ作解耦。
异步:现场画个图来说明一下,
没使用mq前效果:

使用mq后的效果:
A系统接收一个请求,需要在自己本地写库,还需要在BCD三个系统写库,自己本地写库要3ms,BCD三个系统分别写库要300ms、450ms、200ms。最终请求总延时是3 + 300 + 450 + 200 = 953ms,接近1s,用户感觉搞个什么东西,慢死了慢死了。
更改为 异步后当消息发送到消息队列 自行让对应系统进行消费即可 所以给用户的体验为20 + 5 = 25ms ,快 好快!
削峰:每天0点到11点,A系统风平浪静,每秒并发请求数量就100个。结果每次一到11点~1点,每秒并发请求数量突然会暴增到1万条。但是系统最大的处理能力就只能是每秒钟处理1000个请求啊。

消息队列有什么优缺点?
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰
缺点呢?怎么解决?
系统可用性降低:系统引入的外部依赖越多,越容易挂掉,本来你就是A系统调用BCD三个系统的接口就好了,人ABCD四个系统好好的,没啥问题,你偏加个MQ进来,万一MQ挂了咋整?MQ挂了,整套系统崩溃了,你不就完了么。
系统复杂性提高:硬生生加个MQ进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?
一致性问题:A系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是BCD三个系统那里,BD两个系统写库成功了,结果C系统写库失败了,咋整?
问题总结:
问题1:MQ挂掉会导致整个系统崩溃? https://www.cnblogs.com/knowledgesea/p/6535766.html
方法:
集群方式:普通模式、镜像模式。
问题2:如何让保证消息消费的幂等性(重复消费问题)? https://blog.youkuaiyun.com/fd2025/article/details/79877302
方法:
增加消息(消息要有唯一ID)消费结果记录。在消费消息时查询是否有消费记录,如果已经消费则不能再次消费。
问题3:怎么保证消息不丢失? https://www.cnblogs.com/flyrock/p/8859203.html
方法:
1.消息持久化:持久化到硬盘
2.ACK确认机制:生产及消费的确认机制
3.设置集群镜像模式:高可用HA
4.消息补偿机制:发送日志、接收日志
问题4:怎么保证消息传递的顺序性(有序性)? https://www.cnblogs.com/doit8791/p/10340482.html
主要思路有两种:
1、单线程消费来保证消息的顺序性;
2、对消息进行编号,消费者处理时根据编号判断顺序。
核心思想就是把生产者的有序消息放入同一个队列,一个消费者消费具有相同属性(消息id-hash对消费者取模的余数)的队列。
既可以实现负载均衡,又可以保证消息的顺序性。
问题5:怎么保证数据的一致性?
方法:
1,强一致性:atomicks
2,弱一致性: https://www.jianshu.com/p/04bad986a4a2
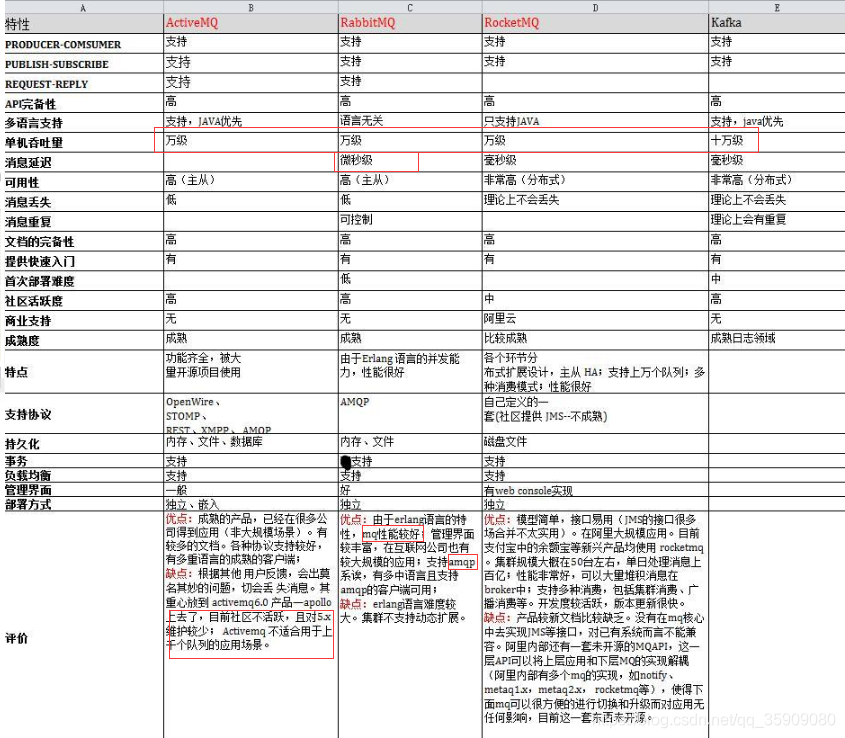
目前流行的消息队列优缺点对比(如何选型)
kafka、activemq、rabbitmq、rocketmq都有什么优点和缺点啊?

















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









