






记一次博文被转载的经历,遇事需淡定
Lan
2020-05-28 09:30
171 人阅读
0 条评论
今天,突然想在百度上搜一下自己的QQ,然后发现自己前几天发的一篇博文被人转载了,本来还挺开心的,但是进去一看,这位转载的站长,没有留出处,而且居然比我先发布。
转载截图:

博客原文:https://www.lanol.cn/post/238.html
然后呢,我还联系了作者QQ,
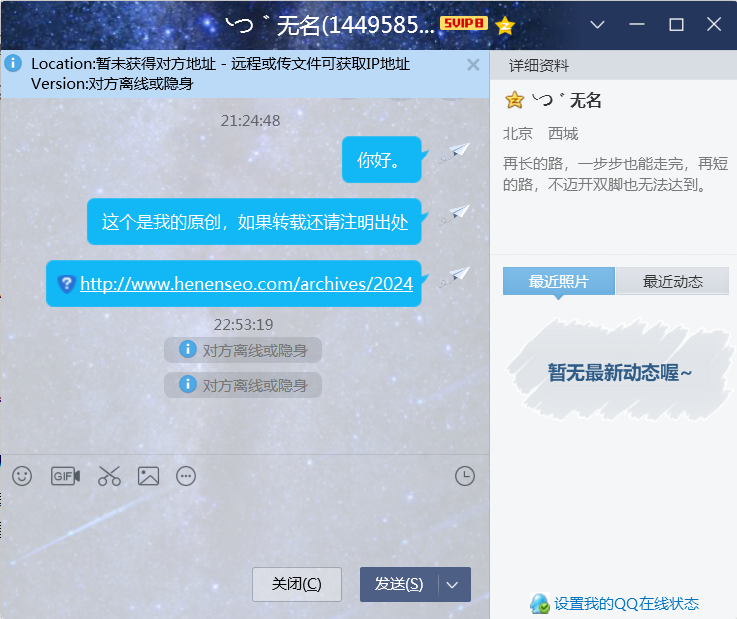
然后,当时转载的站长在忙所以没有及时回复(一个小时之后回复我了),第一次被转载文章,也不知道该如何处理,也是比较比较激动的。然后我就在Mjj论坛发帖寻求帮助,还是Mjj人才多。瞬间就不气了。
首先,我的博文能被盗取,说明我厉害呀。其次,转载文章中的代码中的网址并没有修改,然后,转载的还是我第一次写出来,程序员嘛,你懂得,就是不断创造Bug,修补Bug。所以转载的代码及软件,都是不可用的。
以下截取了部分Mjj的评论,谢谢了
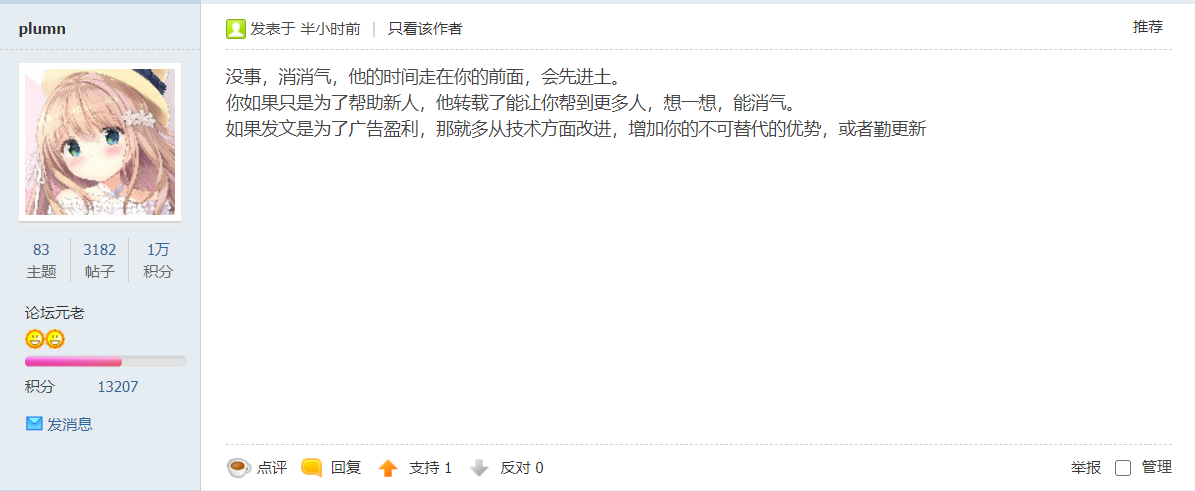
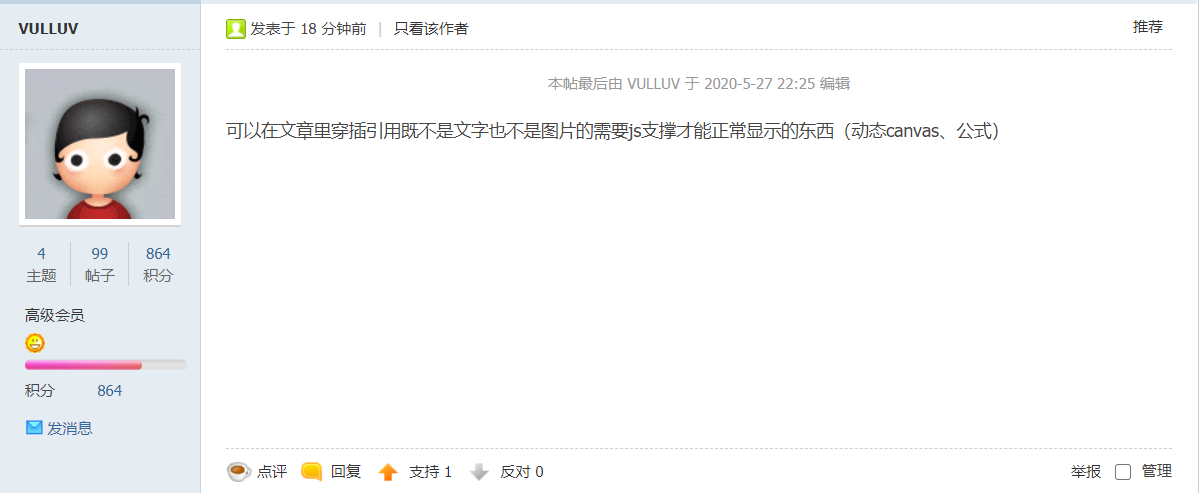
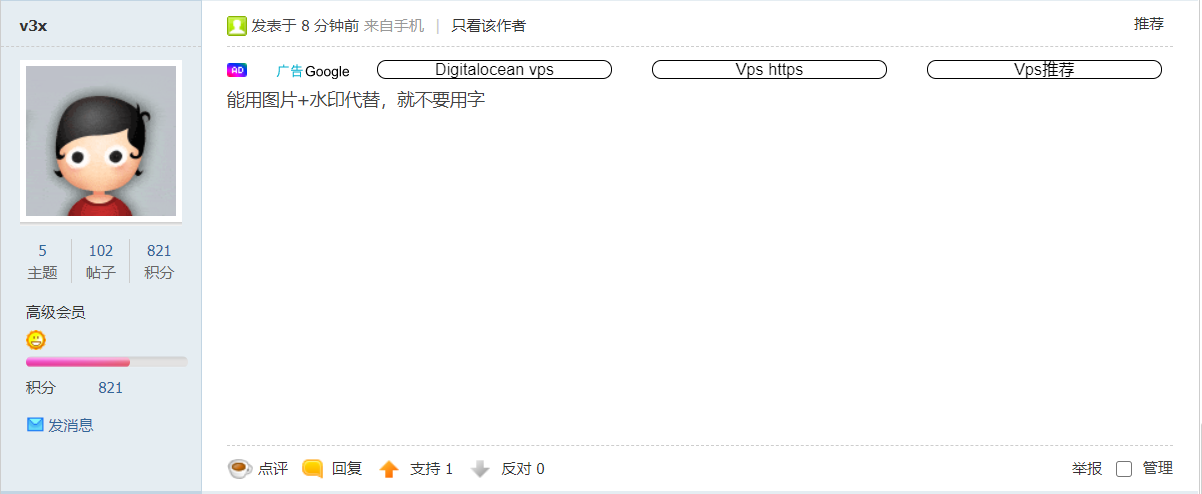
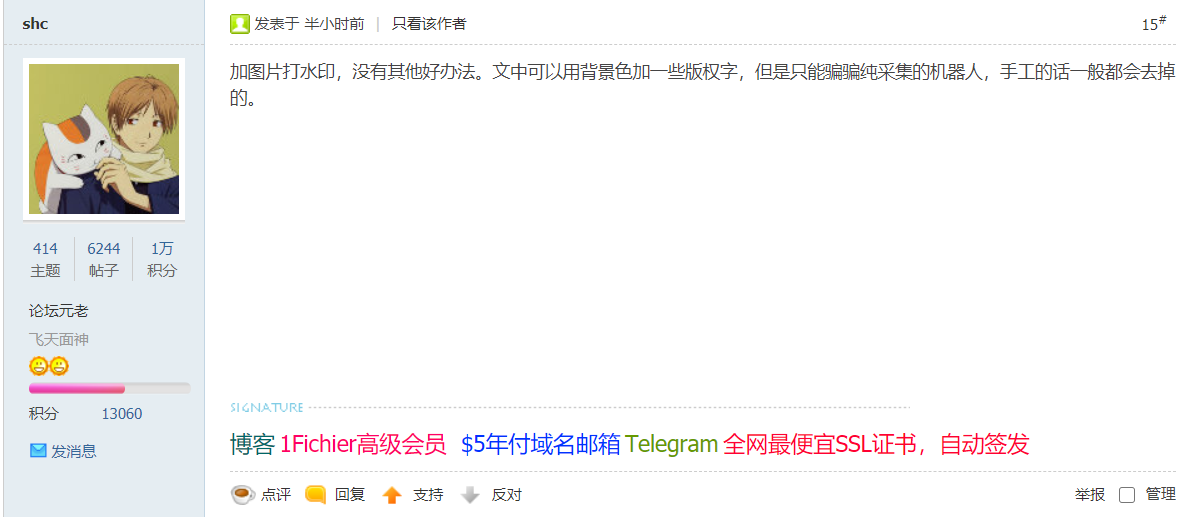
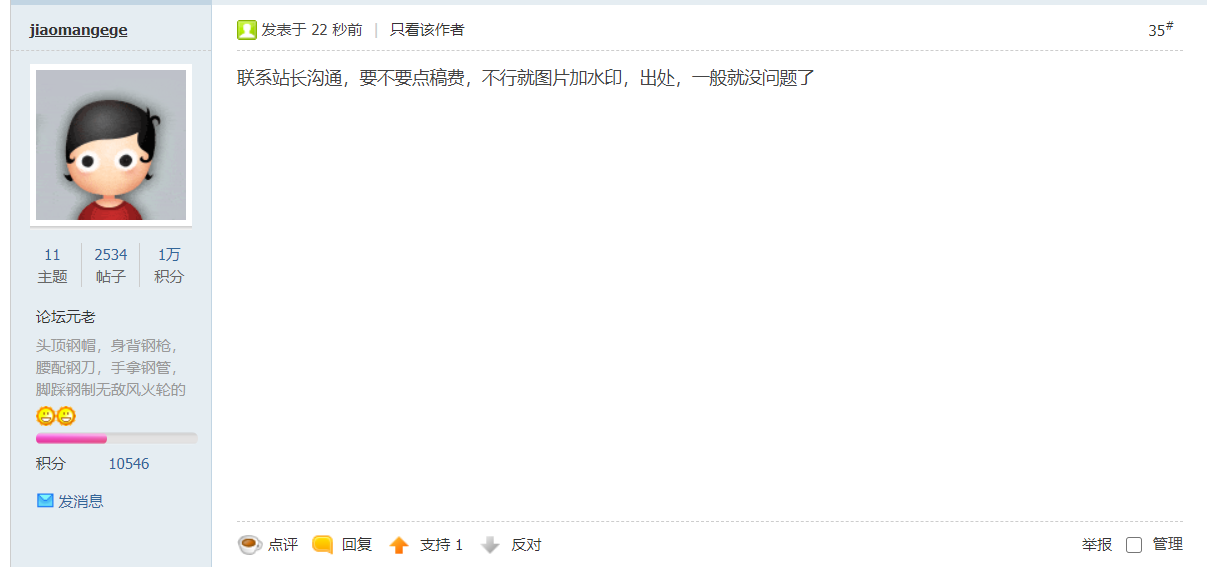
然后在晚上10点多的时候。我收到了转载站长的回复(是我之前鲁莽了)
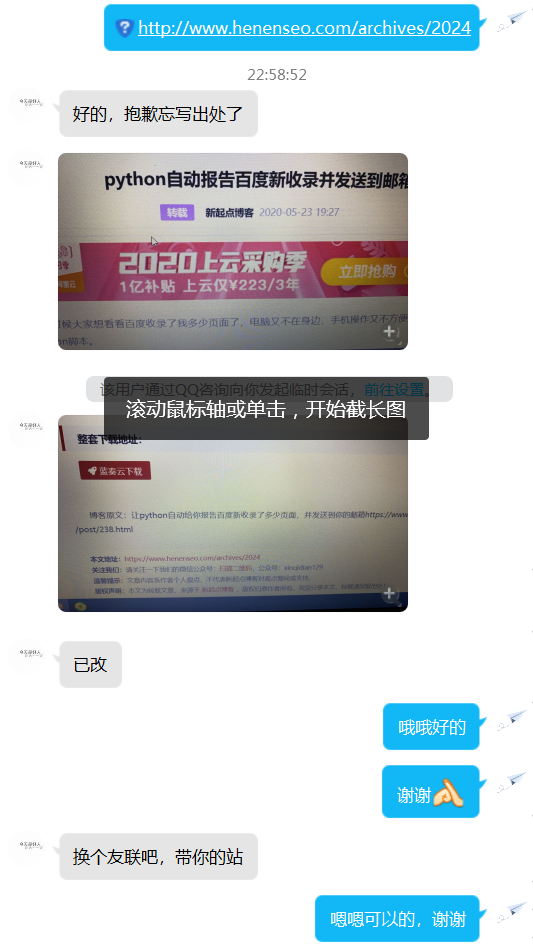
这位站长还非常友好的给我加了个友链,所以遇事需要冷静,不能像我刚开始那样,不可能谁都一直有时间守在电脑旁,其次自己需要做好防护措施,具体怎么做可以看上面Mjj大佬们的评论
赞赏


















 1621
1621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









