







Transformer
Attention Is All You Need
Transformer完全基于注意力机制,它在处理序列转换任务时没有使用任何卷积层或循环神经网络(RNN)层 ,用多头自注意力替换 了编码器-解码器架构中最常用的循环层。
缩放点积注意力(Scaled Dot-Product Attention)
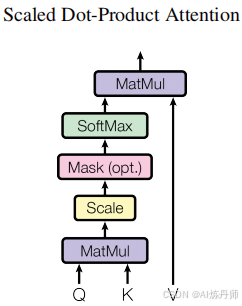
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
计算注意力值:
- 计算Query与每一个Key的相似度得分(点乘)。注意力分数可以理解为Query、Key的相似度得分。
- 将相似度得分转换为归一化概率分布,即每个value对应的权重系数。
- 对Value进行加权求和
多头注意力(Multi-Head Attention)
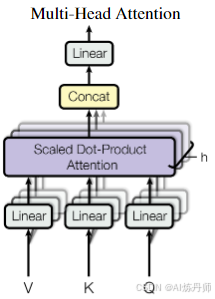
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) 其中投影是参数矩阵 W i Q ∈ R d m o d e l × d k , W i K ∈ R d m o d e l ×
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









