






爬取拉钩网的职位列表请参考:https://blog.youkuaiyun.com/qq_35723619/article/details/83147695
看这篇博客前参考上一个博客
在上篇已经拿到具体的职位列表的信息,这时我们将爬取每个职位的详情
先做翻页爬虫:

需要该造原有的代码,将form_data的变为pn可变我们将使用for循环来做,
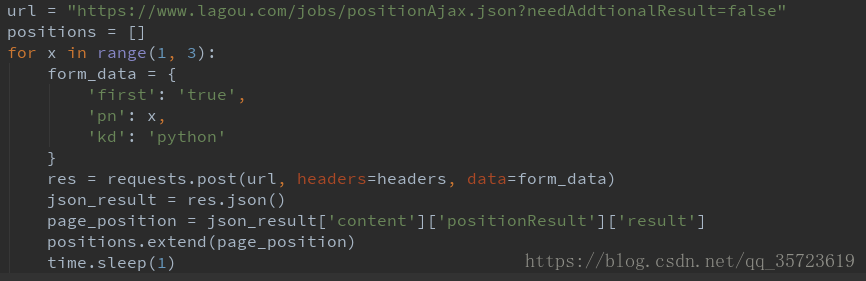
将结果写入文件中:
line = json.dumps(positions, ensure_ascii=False)
with open("E://file/lagou.json", 'wb') as fp:
fp.write(line.encode("UTF-8"))
运行结果:

 要想取到每个职位的详细描述信息,需要知道职位编号positionId
要想取到每个职位的详细描述信息,需要知道职位编号positionId
需要继续该造
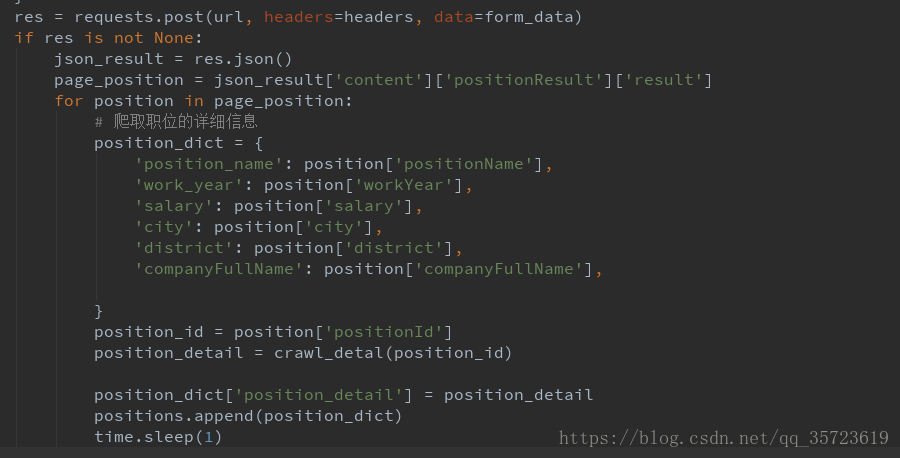
这里需要建立爬取详细信息的函数
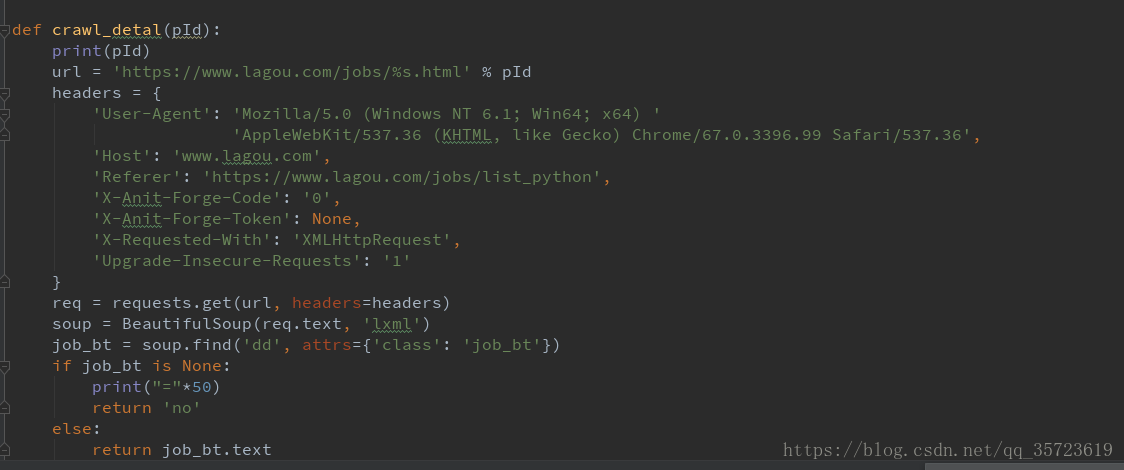
运行结果:
如果爬取时间太快会报错,这是由于拉钩的反爬虫机制所导致的,将time.sleep(t)中的t时间变大就可以了
刚刚从网易云课堂学习爬取,感谢阅读!

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









