






拉钩网有很强的防爬虫机制我们需要做些处理https://www.lagou.com
我选择怕取得是:https://www.lagou.com/jobs/list_python
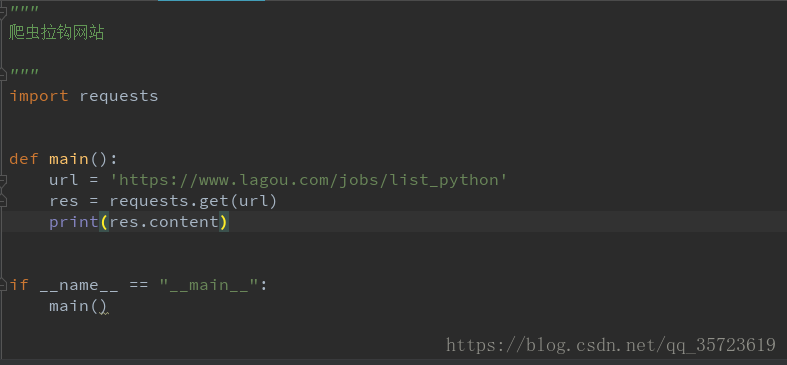
结果出错不是我想要的结果:
网页结构
爬虫结果:
不是想要的这说明有反爬虫机制
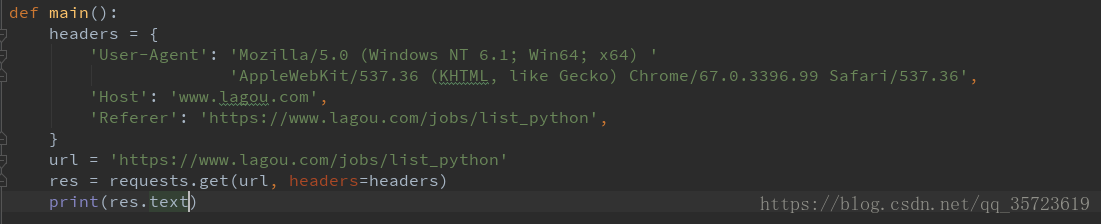
需要把请求头加上,模拟浏览器访问:

我们将hears加入请求
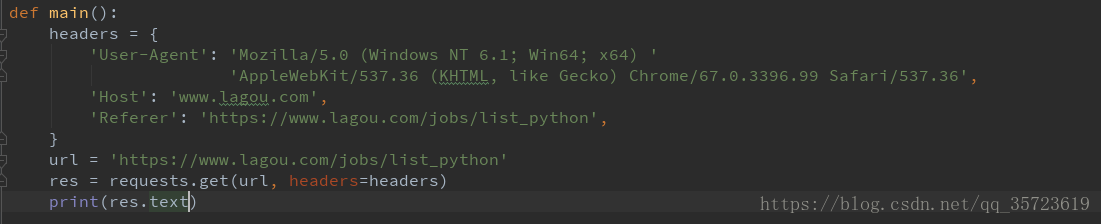
运行结果:
我想要爬取职位列表,这时发现职位列表是ajax请求
可以直接找到请求的ajax的地址改变请求的url:https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false
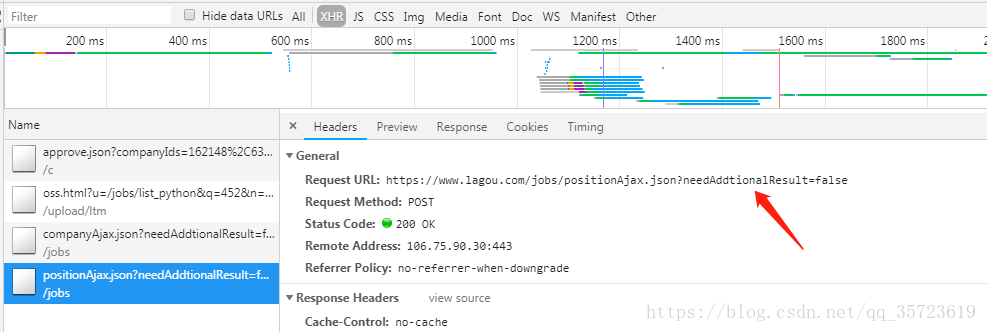
我直接改变url执行:


运行结果:

好像成功了,但是不然 网页上有python开发工程师
网页上有python开发工程师

但是在我爬虫结果中没有,说明不是我想要的结果,这是因为拉钩做的反爬虫机制,我用get请求,拉钩有的是post请求,
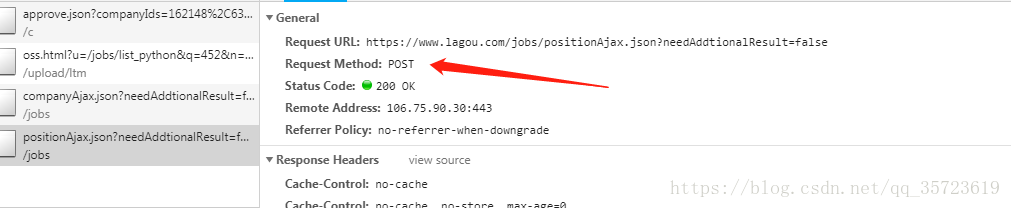
改用post请求我们需要加入:
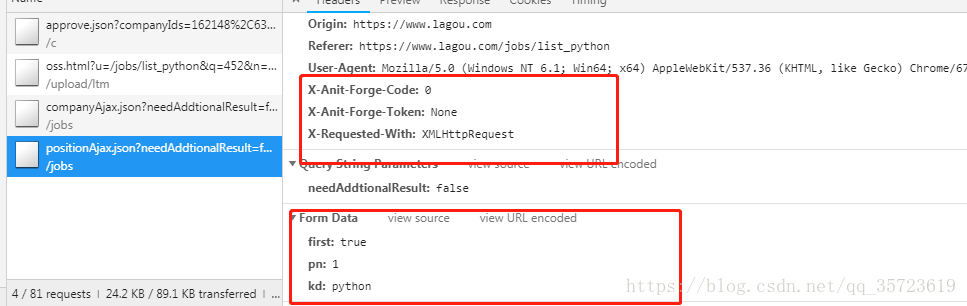
修改代码为:
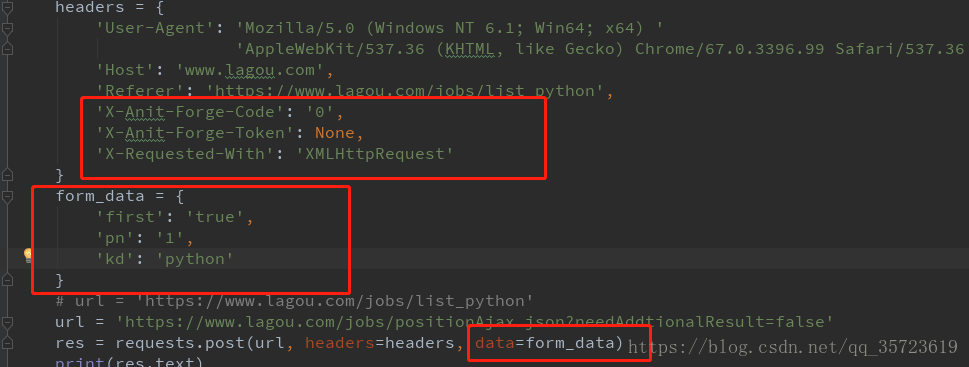
运行结果为:

发现是想要的结果。想要做很好的爬虫需要了解请求hears的内容模拟浏览器。
爬虫之二:https://blog.youkuaiyun.com/qq_35723619/article/details/83176329

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









