







 本文介绍了pandas中处理文本数据的方法,包括string类型的转换、拆分、拼接、替换、提取、正则表达式检查以及空格处理等。重点讲述了正则表达式在替换和提取中的应用,以及如何进行高级分组替换。此外,还提到了字符串的大小写转换、首字母大写和数值判断功能。
本文介绍了pandas中处理文本数据的方法,包括string类型的转换、拆分、拼接、替换、提取、正则表达式检查以及空格处理等。重点讲述了正则表达式在替换和提取中的应用,以及如何进行高级分组替换。此外,还提到了字符串的大小写转换、首字母大写和数值判断功能。
pandas之文本数据
1. string类型
1-1. string类型的转换
- 1.object类型用astype('string')
- 2.非object类型用astype('str').astype('string')
1-2. string类型的拆分
XX列.str.split(pat,n=-1,expand=False)---》object
##
pat:分割字符
n:最多按照分割字符切割几次【-1表示全切割】
expand:是否把分割后的列表拆分成多列
## return 分割字符列表
## 使用str[索引]获取分割后某个分割结果,如果为单元素的分割,则会把单元素转为列表再访问


1-3. string类的拼接
XX列.str.cat(others=None,sep=None,na_rep=None,join='left')---》str/Series/Index
##
others=None 表示单列拼接,表示该列所有字符的拼接,类型为str
others=List/Series/DataFrame表示各行的横向拼接原序列和others,返回类型为Series/Index
sep:表示拼接的连接符
na_rep:表示<NA>的替换符
join:在others!=None 启用,'left'表示左外连接,原序列与待拼接序列索引不一致时,以原序列的索引为主,如果na_rep=None,原序列与待拼接序列索引不一致的位置<NA>
单列合并

双列合并
多列合并

1-4. string类的替换(正则表达式)
XX列.str.replace(pat,repl)---》Series/Index
##
pat:表示要替换的str满足的正则表达式
repl:用repl替换满足正则表达式的部分
注意替换只替换满足正则表达式的部分
简单替换
高级分组替换
利用?P可以命名分组


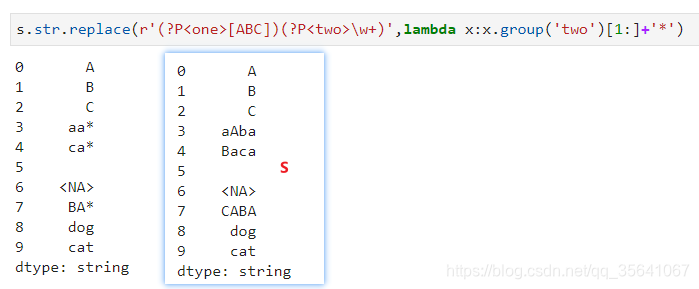
注意str.replace不能替换或者替换的值为
若要替换为pd.NA,可以采用曲线救国的方式,先转为object类型,利用原来版本的replace方法之后再转会string类型
# regex=True表示启用正则表达式
pd.Series(['A','B'],dtype='string').astype('O').replace(r'[A]',pd.NA,regex=True).astype('string')

1-5. string类型的提取
XX列.str.extract(pat,flag=0,expand=True)---》DataFrame/Series/Index
##
pat:表示要提取的str满足的正则表达式
expand:当提取为单列,expand=False返回Series对象
其他情况,如提取为多列,expand=False不起作用,一律返回DataFrame对象
## 多列可能指正则表达式的多组,每组对应一列
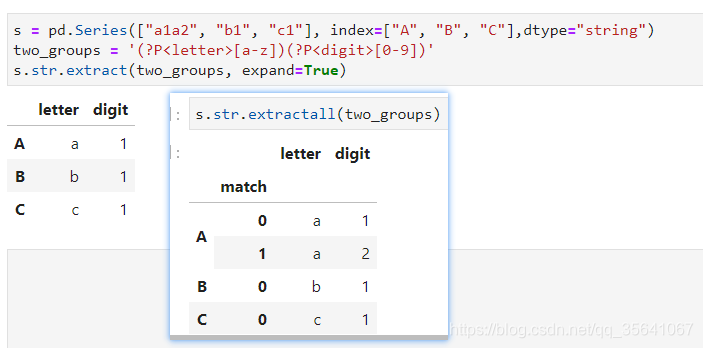
提取单列
# 使用子组名作为列名
pd.Series(['10-87','10-88','10-89'],dtype="string").str.extract(r'(?P<name_1>[\d]{2})-(?P<name_2>[\d]{2})')

利用?进行部分提取
# 使用子组名作为列名
pd.Series(['10-87', '10-88', '-89'],dtype="string").str.extract(r'(?P<A>[\d]{2})?-(?P<B>[\d]{1})(?P<C>[\d]{1})')
多匹配提取
使用extractall会为多次匹配正则表达式的建立多层索引,返回多次匹配的结果,而extract只返回首次
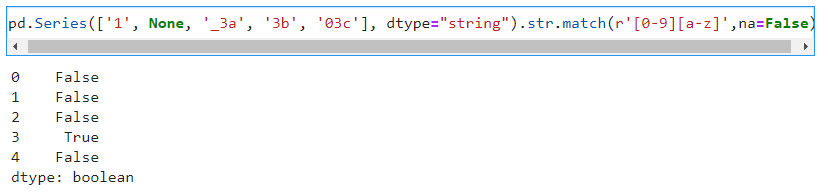
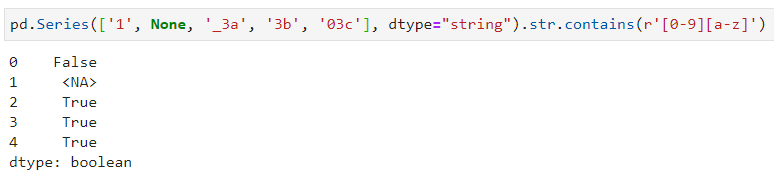
1-6. 检查字符串是否包含某个正则表达式
str.contains()表示检查字符串是否包含正则表达式
str.match()表示检查字符串是否是从整个字符串开头就包含该正则表达式
两个函数都有可选参数na,表示匹配到空值的bool表示,若是没设置该参数继续显示
1-7. 去除空格,大小写转换,首字母大写,判断是否只包含数值
去除空格 str.strip()
转换为小写 str.lower()
转换为大写 str.upper()
交换大小写 str.swapcase()
首字母大写 str.capitalize()
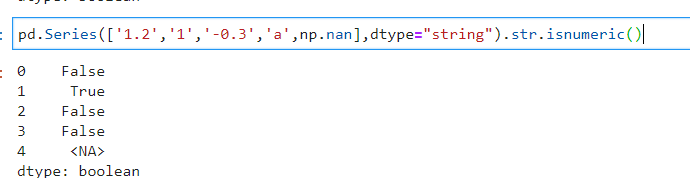
判断是否只包含数值 str.isnumeric() ----该方法不能用于判断该列是否为数值型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









