







 kallisto Pseudoalignments基于k-mers和T-DBG构建索引进行比对。首先,通过k-mers建立contig,每个node对应一个k-compatibility class。在比对阶段,将read切割成k-mer,找到比对上的node的k-compatibility class交集,确定read的归属。通过避免冗余的k-equivalence class提高比对效率。
kallisto Pseudoalignments基于k-mers和T-DBG构建索引进行比对。首先,通过k-mers建立contig,每个node对应一个k-compatibility class。在比对阶段,将read切割成k-mer,找到比对上的node的k-compatibility class交集,确定read的归属。通过避免冗余的k-equivalence class提高比对效率。
原文链接
参考博客链接
kallisto Pseudoalignments是基于k-mers + T-DBG(transcriptome de Bruijn graph)
关于什么是de Bruijn graph 请点这里
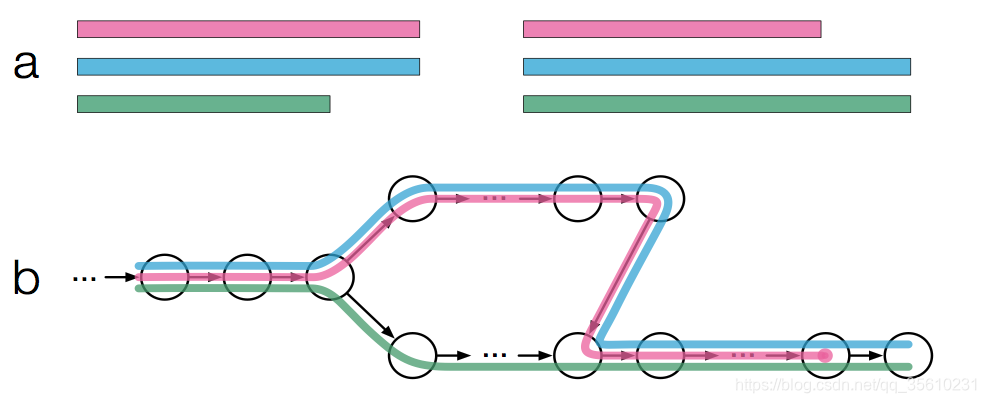 如上图有三条overlapping的 transcripts,红、蓝、绿各代表一条。
如上图有三条overlapping的 transcripts,红、蓝、绿各代表一条。
第一步:建立索引
k-mers默认是31,k-mers越小会越敏感。图上的每一个node都代表一个k-mer。
k-compatibility class:transcripts包含node的k-mers ,那么称transcripts为该node的一个k-comptibility class。如图上最左边的node有三个k-compatibility class,因为三条transcripts都包含该node代表的k-mer。三个最上面的node只有两个k-compatibility class,因为只有蓝和红两条transcripts包含node 代表的k-mer。
contig:连续的有相同k-compatibility class的node组成。如上图中最左边的三个node构成一个contig,最上面的node也构成一个contig。
index会建立一个hash table<KmerEntry,KmerHash> K
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2810
2810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









