







Nested-Loop Join
Simple Nested-Loop Join(SNLJ)
Index Nested-Loop Join (INLJ)
Block Nested-Loop (BNL)
Simple Nested-Loop Join(SNLJ)
Simple Nested-Loop Join(简单嵌套循环连接)是一种基本的连接算法,用于实现两个表之间的连接操作。这种算法的基本思想是:对于表 A 中的每一行,都遍历表 B 中的所有行,检查是否满足连接条件。如果满足,则将这两行组合成一行输出。
算法步骤
- 初始化:从外层表(通常是较小的表或有索引的表)中读取第一行。
- 内层循环:对于外层表中的当前行,遍历内层表(通常是较大的表)中的所有行。
- 连接条件检查:对于内层表中的每一行,检查是否满足连接条件。
- 输出结果:如果满足连接条件,则将这两行组合成一行输出。
- 继续处理:移动到外层表的下一行,重复步骤 2 到 4,直到外层表的所有行都处理完毕。
for each row in t1 matching range{
for each row in t2 matching reference key {
for each row in t3{
if row satisfies join conditions.
send to client
}
}
}
当t1表5行数据,t2表5行数据时,需要扫描25行数据:
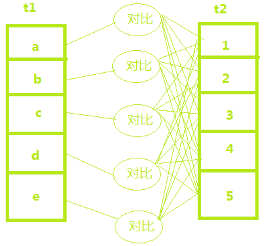
示例
假设我们有两个表 A 和 B,表 A 有 3 行,表 B 有 4 行,连接条件是 A.id = B.id。
CREATE TABLE A (
id INT,
name VARCHAR(50)
);
CREATE TABLE B (
id INT,
value INT
);
INSERT INTO A (id, name)
VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Charlie');
INSERT INTO B (id, value)
VALUES (1, 10), (2, 20), (3, 30), (4, 40);
执行以下查询:
SELECT A.id, A.name, B.value
FROM A
JOIN B ON A.id = B.id;
执行过程
- 从表
A中读取第一行(1, 'Alice')。 - 遍历表
B中的所有行:- 检查
(1, 10),满足连接条件A.id = B.id,输出(1, 'Alice', 10)。 - 检查
(2, 20),不满足连接条件。 - 检查
(3, 30),不满足连接条件。 - 检查
(4, 40),不满足连接条件。
- 检查
- 从表
A中读取第二行(2, 'Bob')。 - 遍历表
B中的所有行:- 检查
(1, 10),不满足连接条件。 - 检查
(2, 20),满足连接条件A.id = B.id,输出(2, 'Bob', 20)。 - 检查
(3, 30),不满足连接条件。 - 检查
(4, 40),不满足连接条件。
- 检查
- 从表
A中读取第三行(3, 'Charlie')。 - 遍历表
B中的所有行:- 检查
(1, 10),不满足连接条件。 - 检查
(2, 20),不满足连接条件。 - 检查
(3, 30),满足连接条件A.id = B.id,输出(3, 'Charlie', 30)。 - 检查
(4, 40),不满足连接条件。
- 检查
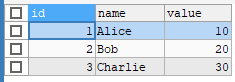
最终结果集为:
性能考虑
Simple Nested-Loop Join 的时间复杂度为 O(m * n),其中 m 和 n 分别是两个表的行数。因此,当表的规模较大时,这种算法的性能可能会较差。为了提高性能,可以考虑使用索引、优化查询计划或使用其他更高效的连接算法(如 Block Nested-Loop Join 或 Hash Join)。
Index Nested-Loop Join (INLJ)
Index Nested-Loop Join (INLJ) 是一种常用的连接算法,用于执行两个表之间的连接操作。这种算法特别适用于其中一个表有索引的情况。
For each row r in R do
lookupr In S index
if found s ==r
Then output the tuple
当t1表有5行数据,t2表有5行数据时,一共需要扫描5+5=10行数据:
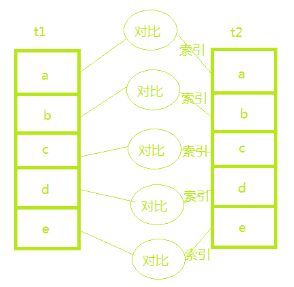
基本原理
- 外层循环:选择一个表作为外层表(通常是较小的表或有索引的表)。
- 内层循环:对于外层表中的每一行,使用索引在内层表中查找匹配的行。
优点
- 高效性:如果外层表较小且内层表有合适的索引,INLJ 可以非常高效地执行连接操作。
- 减少 I/O 操作:通过使用索引,可以减少对磁盘的 I/O 操作,提高查询性能。
缺点
- 依赖索引:如果内层表没有合适的索引,INLJ 的性能会显著下降。
- 内存消耗:如果外层表较大,可能会导致内存消耗增加。
示例
假设有两个表 orders 和 customers,其中 orders 表有一个外键 customer_id,指向 customers 表的主键 id。
CREATE TABLE customers (
id INT PRIMARY KEY,
name VARCHAR(100)
);
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_id INT,
amount DECIMAL(10, 2),
FOREIGN KEY (customer_id) REFERENCES customers(id)
);
找到所有订单及其对应的客户信息:
SELECT orders.id, customers.name, orders.amount
FROM orders JOIN customers
ON orders.customer_id = customers.id;
在这个查询中,MySQL 可能会选择使用 INLJ 算法:
- 外层循环:遍历
orders表中的每一行。 - 内层循环:对于
orders表中的每一行,使用customer_id索引在customers表中查找匹配的行。
执行计划
可以通过 EXPLAIN 关键字查看 MySQL 的执行计划,确认是否使用了 INLJ 算法:
EXPLAIN SELECT orders.id, customers.name, orders.amount
FROM orders
JOIN customers ON orders.customer_id = customers.id;
在执行计划中,如果看到 type 列为 ref,并且 key 列显示了使用的索引,那么就说明使用了 INLJ 算法。
总结
Index Nested-Loop Join 是一种高效的连接算法,特别适用于一个表有索引的情况。通过合理使用索引,可以显著提高查询性能。
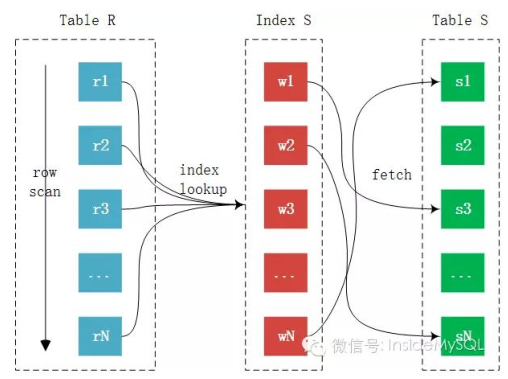
Block Nested-Loop (BNL)
Block Nested-Loop (BNL) 是一种用于执行连接操作的算法。在数据库查询中,当需要从多个表中检索数据时,通常会使用连接(JOIN)操作。Block Nested-Loop 算法是一种优化的嵌套循环连接算法,它通过减少磁盘 I/O 操作来提高性能。
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1,t2 in join buffer
if buffer is full {
for each row in t3{
for each t1,t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
empty join buffer
}
}
}
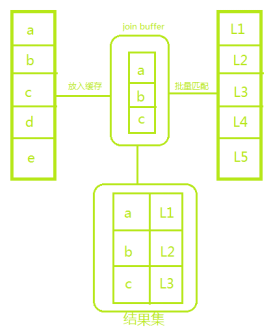
基本原理
- 外层循环:选择一个表作为外层表(通常是较小的表或有索引的表)。
- 内层循环:对于外层表中的每一行,遍历内层表(通常是较大的表)中的所有行,检查是否满足连接条件。
- 块处理:为了减少磁盘 I/O 操作,BNL 算法会将外层表的一部分行读入内存缓冲区(称为“块”),然后对这些行进行内层循环的处理。这样可以减少对外层表的多次读取操作。
优点
- 减少 I/O 操作:通过块处理,减少了对外层表的多次读取操作,从而提高了性能。
- 适用于小表和大表的连接:特别适用于一个表较小而另一个表较大的情况。
缺点
- 内存消耗:需要足够的内存来缓存外层表的块。
- 性能瓶颈:如果内层表非常大,内层循环的开销可能会很大。
如何设置和优化 BNL
调整系统变量:
join_buffer_size:控制每个连接操作的缓冲区大小。增加这个值可以提高 BNL 的性能,但也会增加内存使用。sort_buffer_size:如果连接操作涉及排序,调整这个值也可以提高性能。
SET GLOBAL join_buffer_size = 1024 * 1024 * 8; -- 设置为8MB
创建索引:
- 在连接条件中使用的列上创建索引,可以显著提高连接操作的性能。
CREATE INDEX idx_column1 ON table1(column1);
CREATE INDEX idx_column2 ON table2(column2);
-
优化查询:
- 尽量减少连接的表的数量。
- 使用更具体的 WHERE 条件来减少需要处理的数据量。
分析查询计划:
- 使用
EXPLAIN关键字来查看查询的执行计划,了解 MySQL 是否选择了 BNL 算法。
EXPLAIN SELECT * FROM table1 JOIN table2
ON table1.column1 = table2.column2;
示例
-- 创建索引
CREATE INDEX idx_customer_id ON orders(customer_id);
CREATE INDEX idx_customer_id ON customers(id);
-- 查询
SELECT orders.*, customers.name
FROM orders
JOIN customers ON orders.customer_id = customers.id;
-- 查看执行计划
EXPLAIN SELECT orders.*, customers.name
FROM orders
JOIN customers ON orders.customer_id = customers.id;
优化建议
- 索引:确保连接条件中的列上有适当的索引,以加快内层循环的查找速度。
- 表大小:尽量选择较小的表作为外层表。
- 内存配置:确保有足够的内存来缓存外层表的块。
使用Join Buffer有以下要点:
1. set optimizer_switch='block_nested_loop=on';
2. join_buffer_size变量决定 buffer 大小。
3. 只有在type类型为all, index, range的时候才可以使用BNL。
4. 在join之前就会分配join buffer, 在query执行完毕即释放。
总结:
BNLJ 是在没有可用索引时的备选算法。它将驱动表的一部分行(称为 “块”)读入内存(join buffer),然后逐行扫描被驱动表,将每一行与内存中的所有驱动表行进行比较。
具体步骤:
1,将驱动表的部分行加载到 join buffer。
2,扫描被驱动表的每一行,与 join buffer 中的所有行进行匹配。
3,重复上述过程,直到处理完驱动表的所有块。
适用于:被驱动表的连接列上没有可用索引。join buffer 足够大,能容纳驱动表的大部分数据。
总结:
优先使用 INLJ:通过在被驱动表的连接列上创建索引,将 BNLJ 转换为 INLJ。对于无法避免的 BNLJ,增大join_buffer_size参数,减少磁盘 I/O。
避免大表无索引连接:大表之间的连接若无索引,BNLJ 的性能会显著下降。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











