







字典的变种
collections.OrderedDict1
这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致的。OrderedDict 的popitem方法默认删除并返回的是字典里的最后一个元素,但是如果像 my_odict.popitem(last=False) 这样调用它,那么它删除并返回第一个被添加进去的元素。
collections.ChainMap2
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文。在 collections 文档介绍 ChainMap对象的那一部分里有一些具体的使用示例,其中包含了下面这个 Python 变量查询规则的代码片段:
import builtins
from collections import ChainMap
pylookup = ChainMap(locals(), globals(), vars(builtins))
collections.Counter3
这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。所以这个类型可以用来给可散列表对象计数,或者是当成多重集来用——多重集合就是集合里的元素可以出现不止一次。Counter 实现了 + 和 - 运算符用来合并记录,还有像most_common([n]) 这类很有用的方法。most_common([n]) 会按照次序返回映射里最常见的 n 个键和它们的计数,具体可参考文档。
利用 Counter 来计算单词中各个字母出现的次数:
from collections import Counter
ct = collections.Counter('abracadabra')
print(ct) # Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
ct.update('aaaaazzz')
print(ct) # Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
print(ct.most_common(2)) # [('a', 10), ('z', 3)]
colllections.UserDict
这个类其实就是把标准 dict 用纯 Python 又实现了一遍。跟 OrderedDict、ChainMap 和 Counter 这些开箱即用的类型不同,UserDict 是让用户继承写子类的。下面就来试试。
子类化UserDict
就创造自定义映射类型来说,以 UserDict 为基类,总比以普通的dict 为基类要来得方便。
UserDict 并不是 dict 的子类,但是UserDict 有一个叫作 data 的属性,是 dict 的实例,这个属性实际上是 UserDict 最终存储数据的地方。这样做的好处是,比起之前实现的StrKeyDict0 类,UserDict 的子类就能在实现 __setitem__ 的时候避免不必要的递归,也可以让 __contains__ 里的代码更简洁。
与之前的StrKeyDict0类相比,无论是添加、更新还是查询操作,StrKeyDict 都会把非字符串的键转换为字符串。
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item
因为 UserDict 继承的是 MutableMapping,所以 StrKeyDict 里剩下的那些映射类型的方法都是从 UserDict、MutableMapping 和Mapping 这些超类继承而来的。特别是最后的 Mapping 类,它虽然是一个抽象基类(ABC),但它却提供了好几个实用的方法。
MutableMapping.update
这个方法不但可以为我们所直接利用,它还用在 __init__ 里,让构造方法可以利用传入的各种参数(其他映射类型、元素是 (key,value) 对的可迭代对象和键值参数)来新建实例。因为这个方法在背后是用 self[key] = value 来添加新值的,所以它其实是在使用我们的 __setitem__ 方法。
Mapping.get
在 之前的StrKeyDict0类中,我们不得不改写get方法,好让它的表现跟__getitem__一致。而在StrKeyDict类中就没这个必要了,因为它继承了Mapping.get方法,而 Python 的源码显示,这个方法的实现方式跟StrKeyDict0.get是一模一样的。4
不可变映射类型
标准库里所有的映射类型都是可变的,但有时候你会有这样的需求,比如不能让用户错误地修改某个映射。
从 Python 3.3 开始,types 模块中引入了一个封装类名叫MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
用 MappingProxyType 来获取字典的只读实例
from types import MappingProxyType
d = {1: 'A'}
d_proxy = MappingProxyType(d)
print(d_proxy) # mappingproxy({1: 'A'})
print(d_proxy[1]) # 'A'
d_proxy[2] = 'x'
"""
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
"""
d[2] = 'B'
print(d_proxy) # mappingproxy({1: 'A', 2: 'B'})
print(d_proxy[2]) # 'B'
集合论
“集”这个概念在 Python 中算是比较年轻的,同时它的使用率也比较低。set 和它的不可变的姊妹类型 frozenset 直到 Python 2.3 才首次以模块的形式出现,然后在 Python 2.6 中它们升级成为内置类型。
集合的本质是许多唯一对象的聚集。因此,集合可以用于去重:
l = ['spam', 'spam', 'eggs', 'spam']
print(set(l)) # {'eggs', 'spam'}
print(list(set(l))) # ['eggs', 'spam']
集合中的元素必须是可散列的,set 类型本身是不可散列的,但是frozenset 可以。因此可以创建一个包含不同 frozenset 的 set。
除了保证唯一性,集合还实现了很多基础的中缀运算符。给定两个集合a 和 b,a | b 返回的是它们的合集,a & b 得到的是交集,而 a - b得到的是差集。合理地利用这些操作,不仅能够让代码的行数变少,还能减少 Python 程序的运行时间。
我们有一个电子邮件地址的集合(haystack),还要维护一个较小的电子邮件地址集合(needles),然后求出 needles 中有多少地址同时也出现在了 heystack 里。借助集合操作,我们只需要一行代码就可以了:
found = len(needles & haystack)
needles 的元素在 haystack 里出现的次数,这次的代码可以用在任何可迭代对象上
found = len(set(needles) & set(haystack))
# 另一种写法:
found = len(set(needles).intersection(haystack))
集合字面量
除空集之外,集合的字面量——{1}、{1, 2},等等——看起来跟它的数学形式一模一样。如果是空集,那么必须写成 set() 的形式。
提示: 如果要创建一个空集,你必须用不带任何参数的构造方法 set()。如果只是写成 {} 的形式,跟以前一样,你创建的其实是个空字典。
s = {1}
print(type(s)) # <class 'set'>
print(s) # {1}
print(s.pop()) # 1
print(s) # set()
像 {1, 2, 3} 这种字面量句法相比于构造方法(set([1, 2, 3]))要更快且更易读。后者的速度要慢一些,因为 Python 必须先从 set 这个名字来查询构造方法,然后新建一个列表,最后再把这个列表传入到构造方法里。但是如果是像 {1, 2, 3} 这样的字面量,Python 会利用一个专门的叫作 BUILD_SET 的字节码来创建集合。
用 dis.dis(反汇编函数)来看看两个方法的字节码的不同:
from dis import dis
print(dis('{1}'))
print(dis('set([1])'))
# --------------结果-----------------------
1 0 LOAD_CONST 0 (1)
2 BUILD_SET 1 # * 一行顶下面三行
4 RETURN_VALUE
None
1 0 LOAD_NAME 0 (set)
2 LOAD_CONST 0 (1) # *
4 BUILD_LIST 1 # *
6 CALL_FUNCTION 1 # *
8 RETURN_VALUE
None
由于 Python 里没有针对 frozenset 的特殊字面量句法,我们只能采用构造方法。Python3 里 frozenset 的标准字符串表示形式看起来就像构造方法调用一样。
print(frozenset(range(10)))
print(frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9}))
集合推导
Python 2.7带来了集合推导(setcomps)和之前讲到过的字典推导。
新建一个Latin-1字符集合,该集合里的每个字符的Unicode 名字里都有“SIGN”这个单词:
from unicodedata import name
print({chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i), '')})
"""
{'¬', '<', '¶', '±', '+', '%', '°', '®', '©', '>',
'#', '¤', '$', '£', '=', '¥', '§', '×', '¢', 'µ', '÷'}
"""
集合的操作
下图列出了可变和不可变集合所拥有的方法的概况,其中不少是运算符重载的特殊方法。
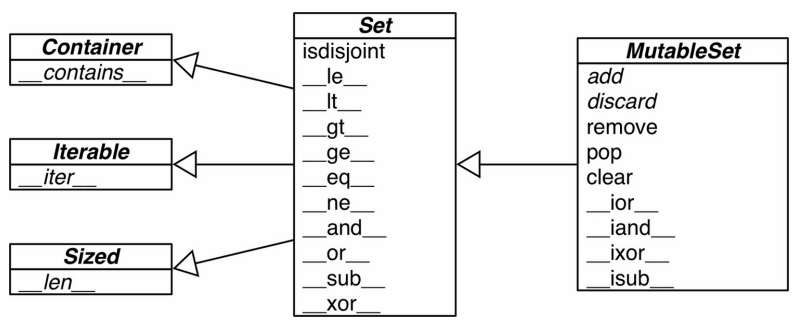
collections.abc中,MutableSet和它的超类的UML类图(箭头从子类指向超类,抽象类和抽象方法的名称以斜体显示,其中省略了反向运算符方法)
下表则包含了数学里集合的各种操作在Python中所对应的运算符和方法。其中有些运算符和方法会对集合做就地修改(像 &=、difference_update,等等),这类操作在纯粹的数学世界里是没有意义的,另外 frozenset 也不会实现这些操作。
集合的数学运算:这些方法或者会生成新集合,或者会在条件允许的情况下就地修改集合:
| 数学符号 | Python运算符 | 方法 | 描述 |
| S∩Z | s&z | s.__and__(z) | s和z的交集 |
| z&s | |||
| s.__rand__(z) | 反向&操作 | ||
| s.intersection(it, ...) | 把可迭代的it和其他所有参数转化为集合,然后求它们与s的交集 | ||
| s&=z | |||
| s.__iand__(z) | 把s更新为s和z的交集 | ||
| s.intersection_update(it, ...) | 把可迭代的 it 和其他所有参数转化为集合,然后求得它们与s的交集,然后把s更新成这个交集 | ||
| S∪Z | s|z | s.__or__(z) | s和z的并集 |
| z|s | |||
| s.__ror__(z) | | 的反向操作 | ||
| s.union(it, ...) | 把可迭代的it和其他所有参数转化为集合,然后求它们和s的并集 | ||
| s |= z | |||
| s.__ior__(z) | 把s更新为s和z的交集 | ||
| s.update(it, ...) | 把可迭代的it和其他所有参数转化为集合,然后求它们和s的并集,并把s更新成这个并集 | ||
| S \ Z | s - z | s.__sub__(z) | s和z的差集,或者叫作相对补集 |
| z - s | |||
| s.__rsub__(z) | - 的反向操作 | ||
| s.difference(it, ...) | 把可迭代的it和其他所有参数转化为集合,然后求它们和s的差集 | ||
| s -= z | |||
| s.__isub__(z) | 把s更新为它与z的差集 | ||
| s.difference_update(it, ...) | 把可迭代的it和其他所有参数转化为集合,求它们和s的差集,然后把s更新成这个差集 | ||
| s.symmetric_difference(it) | 求s和set(it)的对称差集 | ||
| S∩Z | s ^ z | s.__xor__(z) | 求s和z的对称差集 |
| z ^ s | |||
| s.__rxor__(z) | ^ 的反向操作 | ||
| s.symmetric_difference_update(it,...) | 把可迭代的it和其他所有参数转化为集合,然后求它们和 s的对称差集,最后把s更新成该结果 | ||
| s ^= z | |||
| s.__ixor__(z) | 把s更新成它与z的对称差集 |
除了跟数学上的集合计算有关的方法和运算符,集合类型还有一些为了实用性而添加的方法:
| set | frozenset | ||
|---|---|---|---|
| s.add(e) | • | 把元素 e 添加到 s 中 | |
| s.clear() | • | 移除掉 s 中的所有元素 | |
| s.copy() | • | • | 对 s 浅复制 |
| s.discard(e) | • | 如果 s 里有 e 这个元素的话,把它移除 | |
s.__iter__() | • | • | 返回 s 的迭代器 |
s.__len__() | • | • | len(s) |
| s.pop() | • | 从 s 中移除一个元素并返回它的值,若 s 为空,则抛出 KeyError 异常 | |
| s.remove(e) | • | 从 s 中移除 e 元素,若 e 元素不存在,则抛出KeyError 异常 |
dict和set的背后
这一节将会回答以下几个问题:
- Python 里的
dict和set的效率有多高? - 为什么它们是无序的?
- 为什么并不是所有的 Python 对象都可以当作
dict的键或set里的元素? - 为什么
dict的键和set元素的顺序是跟据它们被添加的次序而定的,以及为什么在映射对象的生命周期中,这个顺序并不是一成不变的? - 为什么不应该在迭代循环
dict或是set的同时往里添加元素?
dict和set效率实验
为了对比容器的大小对 dict、set 或 list 的 in 运算符效率的影响,创建了一个有1000 万个双精度浮点数的数组,名叫 haystack。另外还有一个包含了 1000 个浮点数的 needles数组,其中500个数字是从haystack 里挑出来的,另外500个肯定不在 haystack 里。
作为dict测试的基准,用dict.fromkeys()来建立了一个含有1000 个浮点数的名叫haystack 的字典,并用timeit模块测试这段代码运行所需要的时间。
在 haystack 里查找 needles 的元素,并计算找到的元素的个数:
import array
import random
haystack = array.array('d', (random.random() for i in range(10 ** 7)))
needles = array.array('d', (random.random() for i in range(500)))
needles.extend(haystack[0:500])
found = 0
for n in needles:
if n in haystack:
found += 1
print(found)
然后这段基准测试重复了4次,每次都把haystack的大小变成了上一次的10倍,直到里面有1000万个元素。下表是测试的结果。
用in运算符在5个不同大小的haystack字典里搜索1000个元素所需要的时间。代码运行在一个Core i7笔记本上,Python版本是3.4.0:
| haystack的长度 | 增长系数 | dict花费时间 | 增长系数 |
|---|---|---|---|
| 1000 | 1× | 0.000202s | 1.00× |
| 10 000 | 10× | 0.000140s | 0.69× |
| 100 000 | 100× | 0.000228s | 1.13× |
| 1 000 000 | 1000× | 0.000290s | 1.44× |
| 10 000 000 | 10 000× | 0.000337s | 1.67× |
也就是说,从1000个字典键里搜索1000个浮点数所需:的时间是0.000202 秒,把同样的搜索在含有 10 000 000 个元素的字典里进行一遍,只需要 0.000337 秒。换句话说,在一个有 1000 万个键的字典里查找 1000 个数,花在每个数上的时间不过是 0.337 微秒——没错,相当于平均每个数差不多三分之一微秒。
作为对比,把 haystack 换成了 set 和 list 类型,重复了同样的增长大小的实验。对于 set,除了上面的那个循环的运行时间,下面一行代码,这段代码也计算了 needles 中出现在haystack中的元素的个数。
利用交集来计算needles中出现在haystack中的元素的个数:
found = len(needles & haystack)
最快的时间来自“集合交集花费时间”这一列,这一列的结果是上面代码中利用集合 & 操作的代码的效果。不出所料的是,最糟糕的表现来自“列表花费时间”这一列。由于列表的背后没有散列表来支持 in 运算符,每次搜索都需要扫描一次完整的列表,导致所需的时间跟据 haystack 的大小呈线性增长。
在5个不同大小的haystack里搜索1000个元素所需的时间,haystack分别以字典、集合和列表的形式出现。测试环境是一个有Core i7处理器的笔记本,Python版本是3.4.0(测试所测量的代码是最上方的循环和集合&操作)
| haystack的长度 | 增长系数 | dict花费时间 | 增长系数 | 集合花费时间 | 增长系数 | 集合交集花费时间 | 增长系数 | 列表花费时间 | 增长系数 |
|---|---|---|---|---|---|---|---|---|---|
| 1000 | 1× | 0.000202s | 1.00× | 0.000143s | 1.00× | 0.000087s | 1.00× | 0.010556s | 1.00× |
| 10 000 | 10× | 0.000140s | 0.69× | 0.000147s | 1.03× | 0.000092s | 1.06× | 0.086586s | 8.20× |
| 100 000 | 100× | 0.000228s | 1.13× | 0.000241s | 1.69× | 0.000163s | 1.87× | 0.871560s | 82.57× |
| 1 000 000 | 1000× | 0.000290s | 1.44× | 0.000332s | 2.32× | 0.000250s | 2.87× | 9.189616s | 870.56× |
| 10 000 000 | 10 000× | 0.000337s | 1.67× | 0.000387s | 2.71× | 0.000314s | 3.61× | 97.948056s | 9278.90× |
如果在你的程序里有任何的磁盘输入/输出,那么不管查询有多少个元素的字典或集合,所耗费的时间都能忽略不计(前提是字典或者集合不超过内存大小)。可以仔细看看上表有关的代码。
python进阶书目串烧(一)—— 特殊方法、序列数组、列表推导、生成器表达
python进阶书目串烧(二)—— 元组拆包、具名元组、元组对比列表、切片
python进阶书目串烧(三)—— 序列、排序、列表对比数组
python进阶书目串烧(四)—— 内存视图、NumPy、列表对比双向队列
python进阶书目串烧(五)—— 泛映射类型、字典推导、映射的弹性键查询
python进阶书目串烧(六)—— 字典变种、不可变映射类型、集合推导
python进阶书目串烧(七)—— 字典原理、字典与集合特征对比
B2中涉及到
collections.OrderedDict使用的位置:1.7 字典排序、9.14 捕获类的属性定义顺序 ↩︎B2中涉及到
collections.ChainMap使用的位置:1.20 合并多个字典或映射 ↩︎B2中涉及到
collections.Counter使用的位置:1.12 序列中出现次数最多的元素、6.4 增量式解析大型 XML 文件 ↩︎在写完
StrKeyDict这个类之后,看到Antonie Pitrou写的“PEP 455 — Adding a key-transforming dictionary to collections”。文章附带的补丁里包含了一个叫作TransformDict的新类型。这个补丁通过issue 18986被吸收进了Python 3.5。为了试试这个类,我把它提取出来放进了一个单独的模块。比起StrKeyDict,TransformDict的通用性更强,也更复杂,因为它把键存成字符串的同时,还要按照它原来的样子存一份。 ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









