




 本文深入探讨Python编程中的高级主题,包括特殊方法的运用,如__len__和__init__,以及如何通过列表推导和生成器表达式高效处理序列。文章还介绍了如何模拟数值类型,创建二维向量,并讨论了列表、元组和字典等序列类型的特性。此外,还涉及了笛卡儿积的计算以及内存管理,如使用生成器表达式节省内存。内容涵盖了从Python数据模型到序列数组的多个方面。
本文深入探讨Python编程中的高级主题,包括特殊方法的运用,如__len__和__init__,以及如何通过列表推导和生成器表达式高效处理序列。文章还介绍了如何模拟数值类型,创建二维向量,并讨论了列表、元组和字典等序列类型的特性。此外,还涉及了笛卡儿积的计算以及内存管理,如使用生成器表达式节省内存。内容涵盖了从Python数据模型到序列数组的多个方面。
我选择了三本比较经典的python书籍,以下简称B1、B2、B3,我会根据其内容的相关性,进行并联式的主题阅读:
由于B2和B3的内容比较零散,不像B1这样系统完整,所以我会以B1为主干,B2和B3为枝干进行阅读,当然我们的内容并不局限于这三本书,我也会将其他的优秀书籍或资料作为参考和补充,力求覆盖python应用的中、高层次,让所有想python技术进阶的人,阅有所得,学有所获。
第一章 python数据模型
我不去想身后会不会袭来寒风冷雨,既然目标是地平线,留给世界的只能是背影。—— 汪国真
开胃小菜:一副扑克牌
import collections
from random import choice
Card = collections.namedtuple('扑克牌', ['点数', '花色'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = '黑桃 方块 梅花 红心'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
suit_values = {'黑桃':3, '红心':2, '梅花':1, '方块':0}
def spades_high(card):
rank_value = FrenchDeck.ranks.index(card[0])
return rank_value * len(suit_values) + suit_values[card[1]]
命名元组1collections.namedtuple()实例化一张扑克牌:
beer_card = Card('7', '方块')
print(beer_card) # 扑克牌(点数='7', 花色='方块')
一副扑克牌实例deck:
deck = FrenchDeck()
print(len(deck)) # 52
print(beer_card[0]) # 扑克牌(点数='2', 花色='黑桃')
print(choice(beer_card)) # 随机抽取
# 可迭代
for card in deck:
print(card)
# 可反向迭代
for card in reversed(deck):
print(card)
# 可用in运算符
print(Card('Q', '红心') in deck) # True
# 按点数及花色进行从小到大排序
for card in sorted(desk,key=spades_high):
print(card)
特殊方法(前后双下划线方法、魔术方法)
特殊方法2的存在是为了被 Python 解释器调用的,你自己并不需要调用它们。也就是说没有 my_object.__len__() 这种写法,而应该使用 len(my_object)。在执行 len(my_object) 的时候,如果my_object 是一个自定义类的对象,那么 Python 会自己去调用其中由你实现的 __len__ 方法。
如果是 Python 内置的类型,比如列表(list)、字符串(str)、字节序列(bytearray)等,那么 CPython 会抄个近路,__len__ 实际上会直接返回 PyVarObject 里的 ob_size 属性。PyVarObject 是表示内存中长度可变的内置对象的 C 语言结构体。直接读取这个值比调用一个方法要快很多。
通常你的代码无需直接使用特殊方法。除非有大量的元编程存在,直接调用特殊方法的频率应该远远低于你去实现它们的次数。唯一的例外可能是 __init__ 方法,你的代码里可能经常会用到它,目的是在你自己的子类的 __init__ 方法中调用超类的构造器。
利用特殊方法模拟数值类型
模拟二维向量:
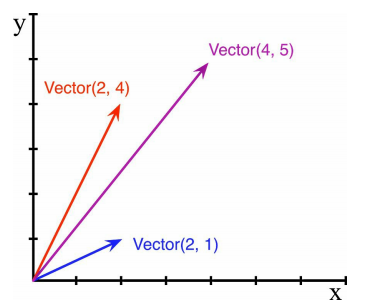
from math import hypot
class Vector:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __repr__(self):
return 'Vector(%r, %r)' % (self.x, self.y)
def __abs__(self):
return hypot(self.x, self.y)
def __bool__(self): # 返回向量的模
return bool(self.x or self.y)
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar): # 向量的标量乘法
return Vector(self.x * scalar, self.y * scalar)
v1 = Vector(2, 3)
v2 = Vector(2, 0)
v3 = v1 + v2 # 向量加法
print(v3, abs(v3), v3 * 3)
为什么len不是普通方法
在 前面提到过,如果 x 是一个内置类型的实例,那么 len(x) 的速度会非常快。背后的原因是 CPython 会直接从一个 C 结构体里读取对象的长度,完全不会调用任何方法。获取一个集合中元素的数量是一个很常见的操作,在str、list、memoryview 等类型上,这个操作必须高效。
第二章 序列构成的数组
乞丐并不会妒忌百万富翁,但是他肯定会妒忌收入更高的乞丐。—— 伯特兰・罗素
内置序列类型概览
按存放的类型
- 容器序列:list、tuple 和 collections.deque
- 扁平序列:str、bytes、bytearray、memoryview 和 array.array
容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是引用。换句话说,扁平序列其实是一段连续的内存空间。由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。
按能否被修改
- 可变序列:list、bytearray、array.array、collections.deque和memoryview。
- 不可变序列:tuple、str 和 bytes
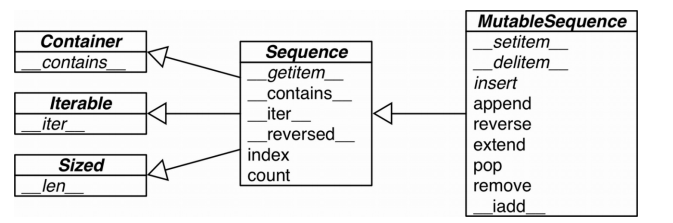
上图显示了可变序列(MutableSequence)和不可变序列(Sequence)的差异,同时也能看出前者从后者那里继承了一些方法。虽然内置的序列类型并不是直接从 Sequence 和MutableSequence 这两个抽象基类(Abstract Base Class,ABC)继承而来的,但是了解这些基类可以帮助我们总结出那些完整的序列类型包含了哪些功能。
列表推导和生成器表达式
列表(list)是一个可变序列,并且能同时存放不同类型的元素。它是python中最重要也最基础的序列类型。
列表推导是构建列表(list)的快捷方式,而生成器表达式则可以用来创建其他任何类型的序列。
列表推导与可读性
把一个字符串变成 Unicode 码位的代码,你觉得方式一和方式二中,哪个更容易读懂?
方式一:for循环实现
symbols = '$¢£¥€¤'
codes1 = []
for symbol in symbols:
codes1.append(ord(symbol))
print(codes1)
方式二:列表推导实现
symbols = '$¢£¥€¤'
codes2 = [ord(symbol) for symbol in symbols]
print(codes2)
我觉得是方式二,看着更简洁易读。列表推导也可能被滥用。通常使用的原则是,只用列表推导来创建新的列表,并且尽量保持简短。如果列表推导的代码超过了两行,你可能就要考虑是不是得用 for 循环重写了。
Python 2.x 中,在列表推导中 for 关键词之后的赋值操作可能会影响列表推导上下文中的同名变量。如你所见,x 原本的值被取代了。但是这种情况在 Python 3 中是不会出现的。
# python2中
x = 'my precious'
dummy = [x for x in 'ABC']
print(x) # C
# python3中
x = 'ABC'
dummy = [ord(x) for x in x]
print(x) # ABC
print(dummy) # [65, 66, 67]
列表推导同filter和map的比较
# 列表推导实现
symbols = '$¢£¥€¤'
beyond_ascii1 = [ord(s) for s in symbols if ord(s) > 127]
print(beyond_ascii1) # [162, 163, 165, 8364, 164]
# map/filter组合实现
beyond_ascii2 = list(filter(lambda c: c > 127, map(ord, symbols)))
print(beyond_ascii2)
原以为 map/filter 组合起来用要比列表推导快一些,Alex Martelli3却说不一定——至少在上面这个例子中不一定。
笛卡儿积
如前所述,笛卡儿积是一个列表,列表里的元素是由输入的可迭代类型的元素对构成的元组,因此笛卡儿积列表的长度等于输入变量的长度的乘积。
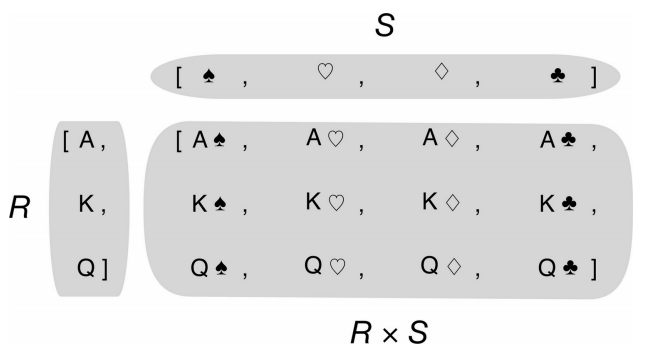
如果你需要一个列表,列表里是 3 种不同尺寸的T恤衫,每个尺寸都有2个颜色,下面代码用列表推导算出了这个列表,列表里有 6 种组合。
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
tshirts1 = [(color, size) for color in colors for size in sizes]
tshirts2 = [(color, size) for size in sizes for color in colors]
print(tshirts1) # 先以颜色,再以尺码
print(tshirts2) # 先以尺码,再以颜色
生成器表达式
虽然也可以用列表推导来初始化元组、数组或其他序列类型,但是生成器表达式是更好的选择。这是因为生成器表达式背后遵守了迭代器协议,可以逐个地产出元素,相比列表推导更节省内存。
生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
用生成器表达式初始化元组和数组
symbols = '$¢£¥€¤'
# 生成器表达式是一个函数调用过程中的唯一参数,那么不需要额外再用括号把它围起来
tuple_code = tuple(ord(symbol) for symbol in symbols)
print(tuple_code)
import array
# array 的构造方法需要两个参数,因此括号是必需的
array_code = array.array('I', (ord(symbol) for symbol in symbols))
print(array_code)
利用生成器表达式实现了一个笛卡儿积
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
# 生成器表达式逐个产出元素,可以避免额外的内存占用
for tshirt in ('%s %s' % (c, s) for c in colors for s in sizes):
print(tshirt)
python进阶书目串烧(一)—— 特殊方法、序列数组、列表推导、生成器表达
python进阶书目串烧(二)—— 元组拆包、具名元组、元组对比列表、切片
python进阶书目串烧(三)—— 序列、排序、列表对比数组
python进阶书目串烧(四)—— 内存视图、NumPy、列表对比双向队列
python进阶书目串烧(五)—— 泛映射类型、字典推导、映射的弹性键查询
python进阶书目串烧(六)—— 字典变种、不可变映射类型、集合推导
python进阶书目串烧(七)—— 字典原理、字典与集合特征对比
命名元组在B2中的位置:1.18 映射名称到序列元素 ↩︎
欲知更多特殊方法应用,可查阅python魔术方法指南或python语言官方参考手册 ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









