






DRAM基础
- DRAM中的存储概念:rank/bank/page;
- 每个rank最多包括16个bank;
- 每个bank中只能有一个page处于“open”状态;
- 让一个page处于“open”需要DRAM的控制器发送“ACT激活”command,并设定好rank/bank和row,然后controller等待Trcd时间才可以CAS;
- 读写数据需要发送“CAS”command并指定好rank/bank/column,然后controller等待Tcas_latency时间
- 让一个page“close”需要控制器发送“PRECHARGE”command,并指定rank/bank,然后控制器等待Trp时间
- 如果需要的page没有“open”,而是同一rank bank中其他page“open”,这是会发生“page conflict”,此时需要控制器先发送“PRECHARGE”命令将不需要的“open”page送回,再“ACT激活”command去open需要的page;
- 当然,使用前必须初始化;
- 此外,一些细节内容需要结合实际+真正工作中使用到才能了解;
DDR技术
https://blog.youkuaiyun.com/cy413026/article/details/82024291
DDR的I/O频率=核心频率*预取位数
核心频率很难做上去,一般在100MHz-200MHz间,预取位数为2(DDR1), 4(DDR2), 8(DDR3), 16(DDR4)
所谓通过预取来匹配计算端频率与DDR核心频率就是将一次性取的并行信号通过串并转换变成串行信号。
单个DDR芯片内部结构
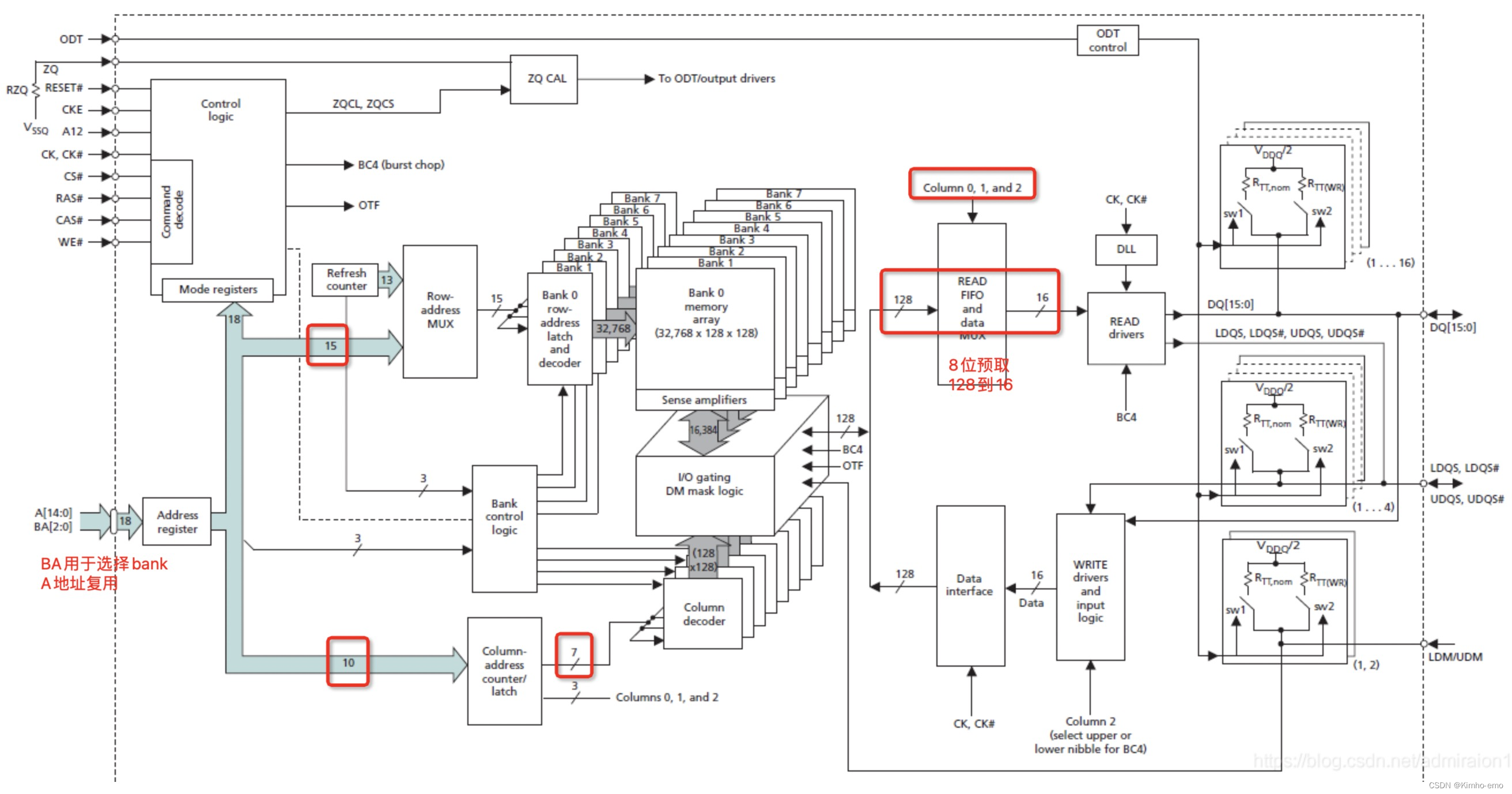
下图是一个DDR3芯片的内部结构,micron的MT41K256M16TW-107为例,MT41K为型号,256M16表示大小为256M*16 = 4Gb
- 存储容量为2^(3+15+7+3)个16bit,第一个3为bank位宽,15为行地址位宽,7为列地址位宽,第二个3做8位预取的平衡,总容量为512MB
- bank数目为8;
- 128到16的8位预取;
- 经过行列选择后的每个块存储单元为128bit;
- 地址复用,先行再列;
- 单颗16bit位宽IO
多个DDR组成一个rank,多个rank组成一个DIMM
- 这块内存条是4GB 2Rx8,其中4GB是整个内存条的储存空间。2Rx8表示该内存条是2 Rank 每颗ddr位宽8bit。
- 每一个黑块就是一个DDR芯片;
- rank就是DIMM中所有共享地址总线进行索引的DDR的集合,也就是直接把每颗DDR的位宽提升了
- 多个DIMM条就相当于组成了多通道了

DDR内存技术的进化
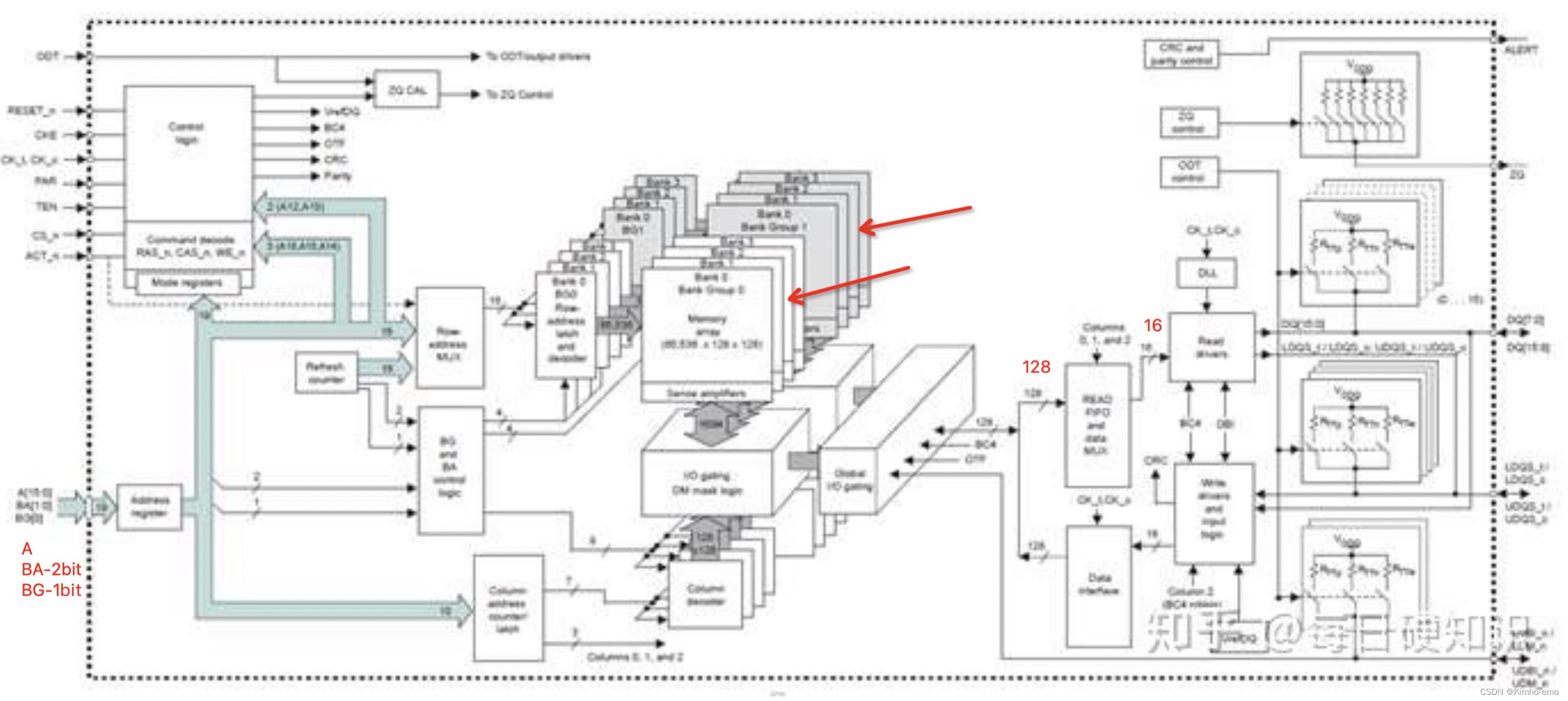
DDR4在单个DDR3内部的bank又做了一个分组,形成bank group,bank group间是独立的,
在DDR在发展的过程中,一直都以增加数据预取值为主要的性能提升手段。但到了DDR4时代,数据预取的增加变得更为困难,所以推出了Bank Group的设计。每个Bank Group可以独立读写数据,这样一来内部的数据吞吐量大幅度提升,可以同时读取大量的数据,内存的等效频率在这种设置下也得到巨大的提升。对应DDR4的接口上添加了一个BG(bank group),
DDR4架构上采用了8n预取的Bank Group分组,包括使用两个或者四个可选择的Bank Group分组,这将使得DDR4内存的每个Bank Group分组都有独立的激活、读取、写入和刷新操作,从而改进内存的整体效率和带宽。
如果内存内部设计了两个独立的Bank Group,相当于每次操作16bit的数据,变相地将内存预取值提高到了16n,如果是四个独立的Bank Group,则变相的预取值提高到了32n。
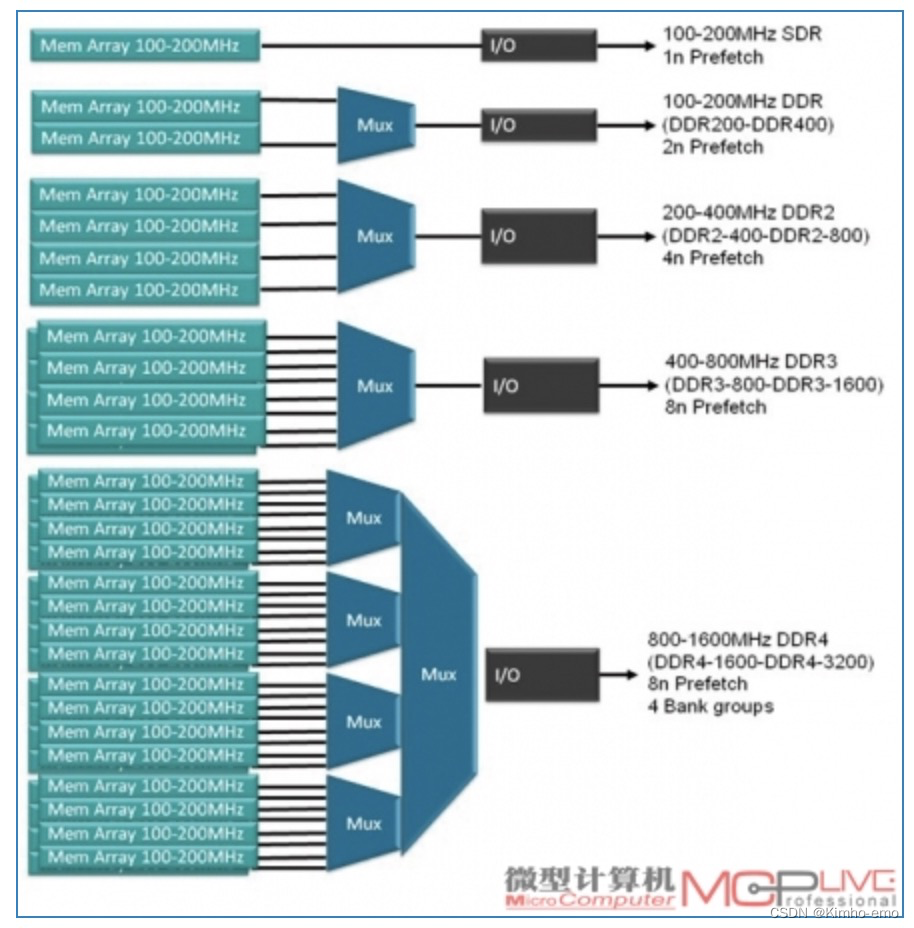
下图可以看出DDR4的变化,分组,好处的个人理解是:
- 根据之前的结构分析,每个块存储单元是128bit的
- bank group的独立意味着可以源源不断的产生128bit数据,而没有group概念的时候,一定会
GDDR
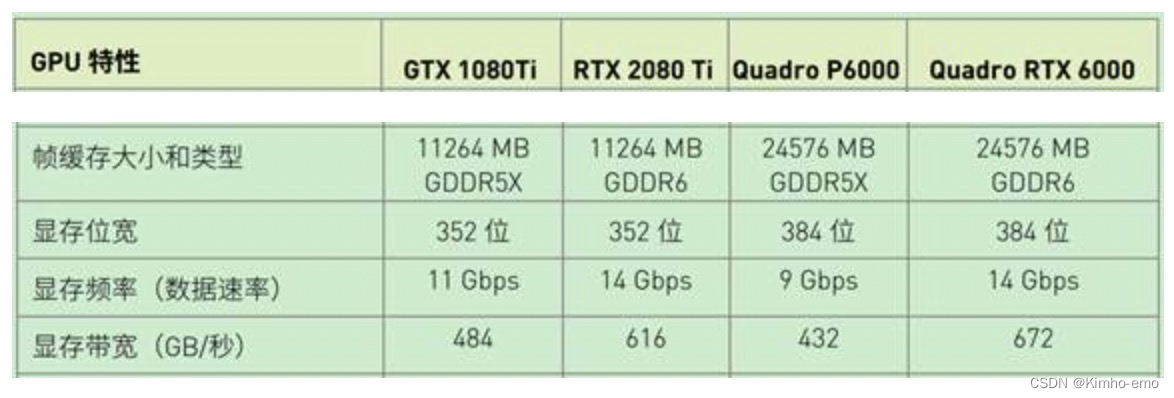
用于显卡的DDR颗粒,可理解为gpu的内存。特点是位宽频率更高,发热更小。
GPU与GDDR间显存数据位宽更大,而CPU与DDR间的数据位宽也就64bit或128bit。
优点是带宽比较高,功耗比较低。
缺点是,适合并发,不适合随机访问;时序复杂,工艺要求高;不适合配合CPU的Cache line的读取。
参考:https://www.sohu.com/a/272922967_463982
| GDDR | 位宽/bit | 预取/bit | 等效频率/GHz | 电压/V | 读写通道 | 单颗容量 | 最大带宽/GB/s | 标准制定 |
|---|---|---|---|---|---|---|---|---|
| GDDR | 16/32 | 2 | 0.9 | 2.5 | 共用 | 16/32MB | 3.6 | - |
| GDDR2 | 32 | 4 | 1 | 2.5 | 共用 | 32MB | 4 | - |
| GDDR3 | 32 | 4 | 2.5 | 1.8 | 读写独立 | 128MB | 10 | NV |
| GDDR4 | 32 | 8 | 4 | 1.5 | 读写独立 | 128MB | 16 | ATI |
| GDDR5 | 32 | 8 | 8 | 1.5 | QDR | 1GB | 32 | - |
| GDDR5X | 32/64 | 16 | 16 | 1.35 | QDR(独立读写) | 2GB | 56/128 | NV+美光 |
| GDDR6 | 32/64 | 16 | 16 | 1.35 | QDR | 4GB | 56/128 | - |
这里我的理解是:从GDDR3代开始,就采用了QDR技术,包括DDR技术和独立的读写通道,相当于4倍速率,NV的显卡都是基于32/64的倍数进行组合。但是单颗芯片能提供的最大带宽需要进一步确认。
等效频率=显存时钟*2或4,取决于DDR还是QDR
HBM技术
一款由三星电子、超微半导体和SK海力士发起的一种基于3D堆栈工艺的高性能DRAM,适用于对高存储器带宽有需求的应用场合。例如图形处理器、网络交换及转发设备(如路由器、交换器)等就是HBM的典型应用场景。
原文链接:https://www.xianjichina.com/news/details_279979.html
核心就是:高带宽、片上3D堆叠
https://www.tomshardware.com/news/rambus-shares-hbm3-details-1075-tbps-of-bandwidth-16-channels-16-hi-stacks

| HBM | 位宽/bit | channel | IO速率/Gbps | IO频率/GHz | 电压/V | max die per stack | 容量/stack | 最大带宽/GB/s | BL | 提出时间 | product |
|---|---|---|---|---|---|---|---|---|---|---|---|
| HBM1 | 1024(128*8) | 8 | 1.0 | 0.5 | 1.3 | 16(16-Hi) | 1GB | 128 | BL2 | ~2015 | GPU |
| HBM2 | 1024(128*8) | 8 | 2.0-2.4 | 1 | 1.2 | 8(8-Hi) | 8GB | 307 | BL4 | ~2016 | GPU/AI |
| HBM2e | 1024 | 8 | 3.2-3.6 | 1.8 | 1.2 | 12(12-Hi) | 16GB | 460 | BL4 | ~2020 | GPU/AI |
| HBM3 | 1024(64*16) | 16 | 4.8-6.4-7.2 | 2.6 | 1.1 | 4(4H-i) | 16-32GB | 819 | BL8 | ~2022 | GPU/AI/HPC/CPU |
| HBM3+ | 1024 | 16 | 8.4 | 4.2 | 1.1 | - | 16-32GB | 1075.2 | BL8 | - |
HBM结构
参考:https://www.amd.com/system/files/documents/high-bandwidth-memory-hbm.pdf
首先,完整的HBM芯片集成后的结构:
- 3D堆叠:HBM die通过TSV(硅通孔)实现信号的共享与分配,TSV这个信道的好处就是超高带宽,之前研究生论文的时候简单研究过;
- 2.5D结构:类似于多个chiplet通过silicon interposer(硅中阶层)进行将多个die进行片内互联,当然要相同的互联协议去保证;
- 每个HBM DRAM die有两个channel,共有2*4=8个channel,可独立访问,每个channel位宽128bit,每个HBM stack位宽1024bit
- 每个HBM channel中包含16个bank
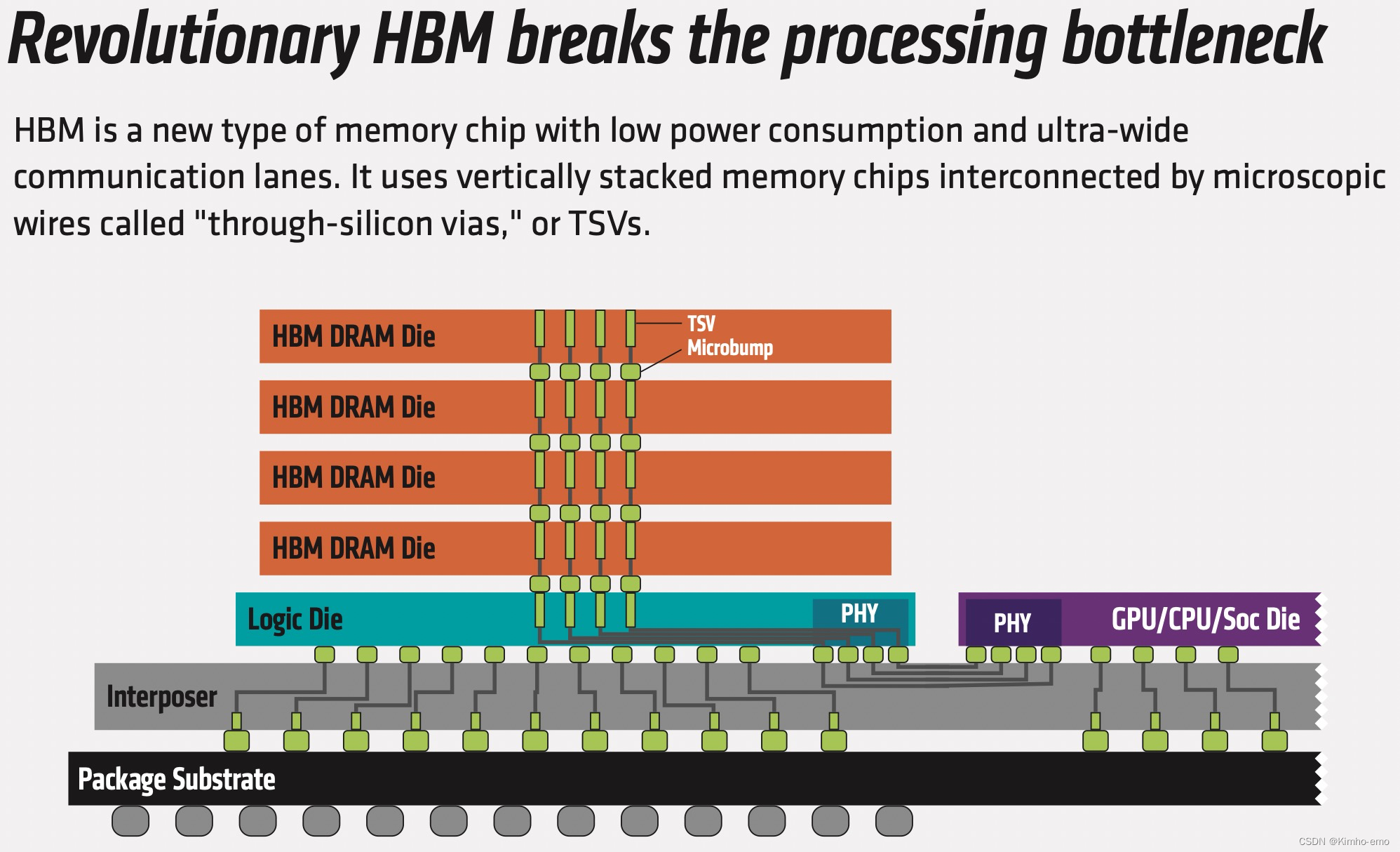
其次是HBM的堆叠结构,如何分配内存??
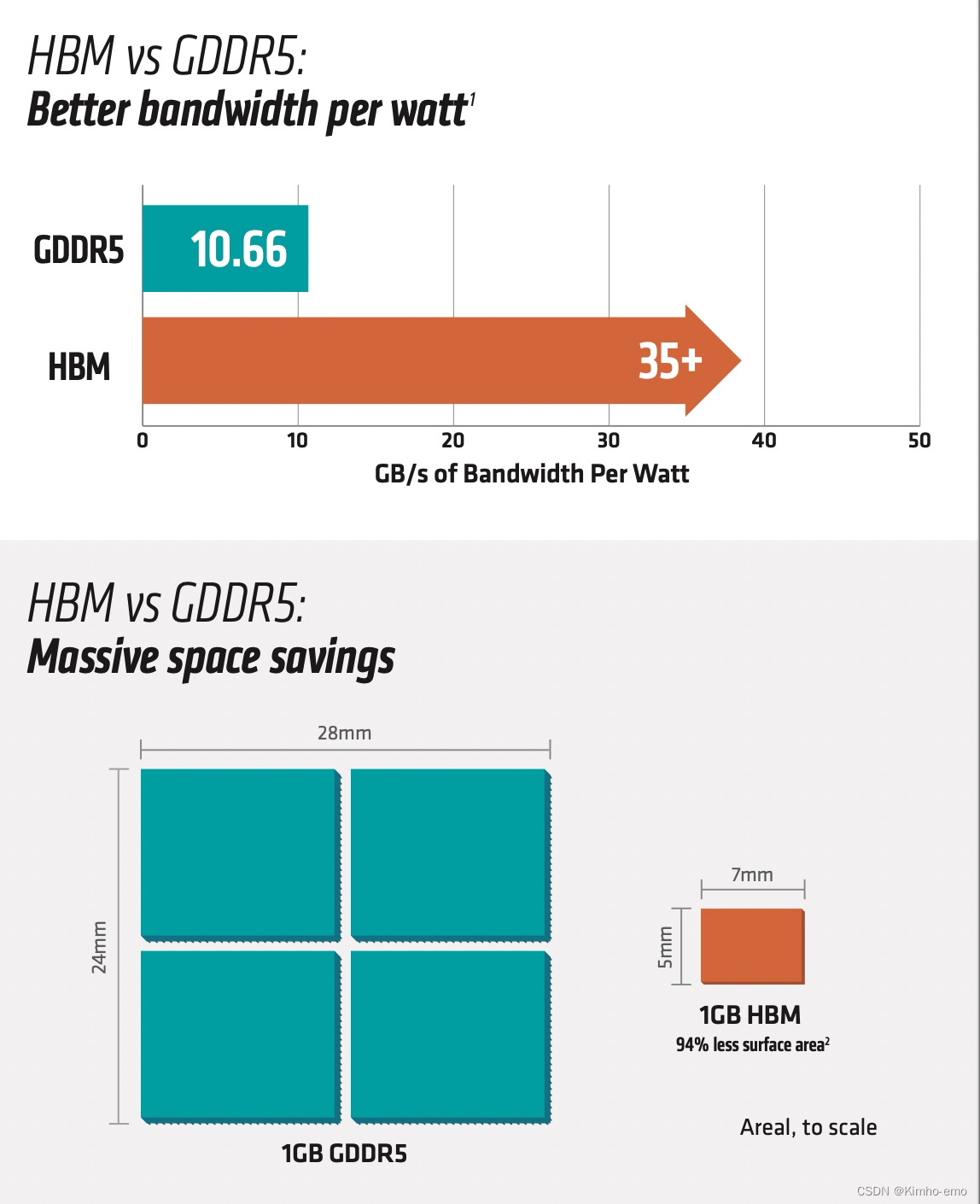
HBM相对于GDDR5,以base die为单位的话,优势显而易见。这里我想说以下几点:
- GDDR5的IO频率已经高达1.75GHz,基本已经是单die的极限了,况且再经过substrate基板的衰减,对信号的电气特性极为苛刻。
- HBM把基板的信道换成interposer,信道带宽可以大幅度提升;
- 通过3D堆叠技术的集成与散热能力的提升,把大容量放到片内成为可能;
- 以IO数目的增加换来了更低的IO速率,为下一代的速度提升提供可能;

能效比大幅度提升的关键在于改善了信道,相信研究过互连小伙伴能感受到物理层的收发器最占功耗。
面积的节省不言而喻。
HBM的pseudo channel mode
- 物理的channel是128bit/channel,每个channel会虚拟的再划分64bit/pseudo channel;
- 相当于每个物理channel被划分为独立的读写通道;
- 之所以称为pseudo,是因为有些command是可以指定为pseudo channel,有些command必须指定到物理的channel,比如一些powerdown;这种特性的设定很符合正常的逻辑;

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









