







 本文详细介绍Elasticsearch伪集群和真实集群的搭建步骤,包括配置文件修改、节点启动及跨域问题解决。同时,深入解析写请求流程,解释数据如何在主分片和副本分片间同步,以及读请求处理机制。
本文详细介绍Elasticsearch伪集群和真实集群的搭建步骤,包括配置文件修改、节点启动及跨域问题解决。同时,深入解析写请求流程,解释数据如何在主分片和副本分片间同步,以及读请求处理机制。
elasticsearch集群搭建
伪集群的搭建
伪集群就是在一台机器中搭建一个se集群,这种集群的方式其实比多台机器更加复杂。而且下面是通过一个elasticsearch文件启动多个elasticsearch节点,所以需要动态配置。
- 配置文件
修改我们的配置文件,首先还是修改elasticsearch.yml文件
注释掉我们的node.name,在启动的时候动态配置
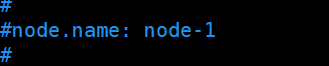
注释掉端口号,同样是启动时动态配置
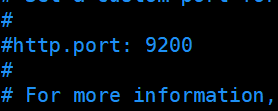
配置节点的名字
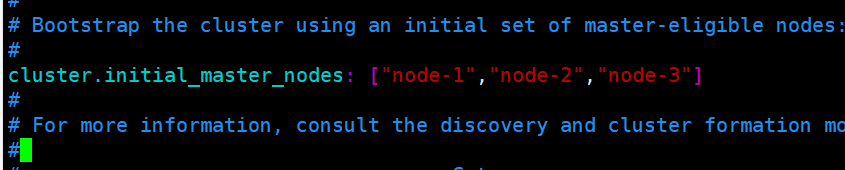
配置各个节点的ip和端口

该参数就是为了防止”脑裂”的产生,定义的是为了形成一个集群,有主节点资格并互相连接的节点的最小数目

解决跨域问题配置

下面是这些配置的总结
cluster.name: luban
node.name: node-1
#允许成为一个主节点
node.master: true
#允许成为一个数据节点
node.data: true
network.host: 0.0.0.0
http.port: 9200
#参数设置一系列符合主节点条件的节点的主机名或 IP 地址来引导启动集群。
cluster.initial_master_nodes: ["node-1"]
# 设置新节点被启动时能够发现的主节点列表(主要用于不同网段机器连接)
discovery.zen.ping.unicast.hosts: ["192.168.204.209","192.168.204.203","192.168.204.108"]
# 该参数就是为了防止”脑裂”的产生。定义的是为了形成一个集群,有主节点资格并互相连接的节点的最小数目。
discovery.zen.minimum_master_nodes: 2
# 解决跨域问题配置
http.cors.enabled: true
http.cors.allow-origin: "*"
- 创建data和log目录
因为是用一个elasticsearch启动多个实例,所以它们的data和log目录必须是不同的,所以我们需要分别创建它们的data和log目录。
创建三个节点的data和logs文件夹
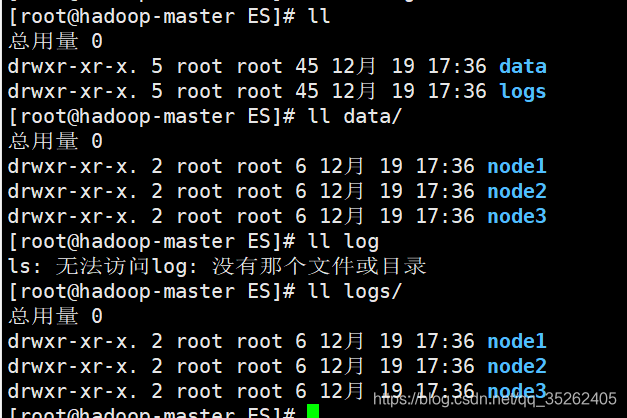
需要注意的是还需要将这些文件夹的权限赋予启动的用户(非root用户)
- 启动节点
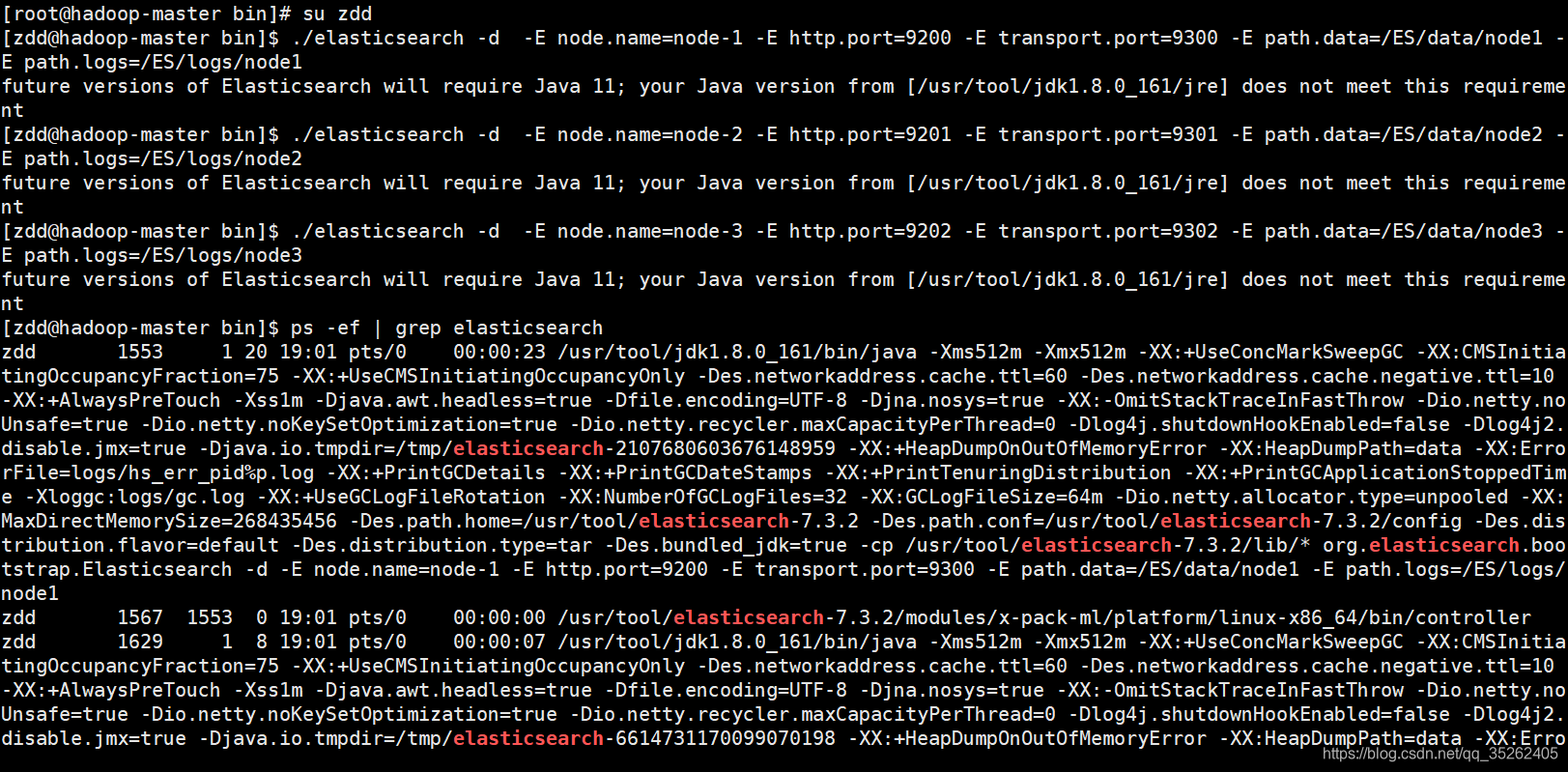
接着需要启动各个节点,而且启动的时候需要动态配置我们刚刚注释掉的配置,启动的命令如下
./elasticsearch -d -E node.name=node-1 -E http.port=9200 -E transport.port=9300 -E path.data=/ES/data/node1 -E path.logs=/ES/logs/node1
./elasticsearch -d -E node.name=node-2 -E http.port=9201 -E transport.port=9301 -E path.data=/ES/data/node2 -E path.logs=/ES/logs/node2
./elasticsearch -d -E node.name=node-3 -E http.port=9202 -E transport.port=9302 -E path.data=/ES/data/node3 -E path.logs=/ES/logs/node3
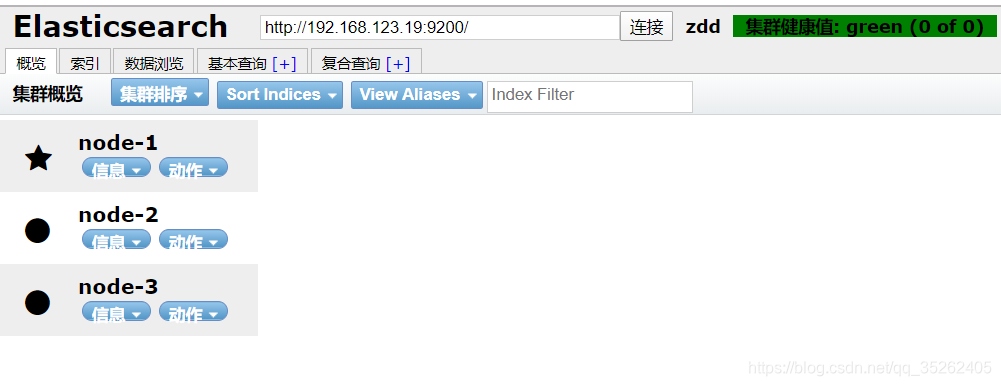
最后我们通过elasticsearch-head查看它们的状态,发现它们已经都启动起来了,而且是以集群模式的方式启动的。
真正的集群搭建
还是三个节点的集群,不过这三个节点都处于不同的机器上,所以需要分别配置文件,不过因为这三个节点处于不同的机器上,所以配置都大体相同。
下面是三个节点的配置,基本只是node.name有所不同
- 192.168.204.209 elasticsearch.yml
cluster.name: zdd
node.name: node-1
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
#参数设置一系列符合主节点条件的节点的主机名或 IP 地址来引导启动集群。
cluster.initial_master_nodes: ["node-1"]
# 设置新节点被启动时能够发现的主节点列表(主要用于不同网段机器连接)
discovery.zen.ping.unicast.hosts: ["192.168.204.209","192.168.204.203","192.168.204.108"]
# 该参数就是为了防止”脑裂”的产生。定义的是为了形成一个集群,有主节点资格并互相连接的节点的最小数目。
discovery.zen.minimum_master_nodes: 2
# 解决跨域问题配置
http.cors.enabled: true
http.cors.allow-origin: "*"
- 192.168.204.203 elasticsearch.yml
cluster.name: zdd
node.name: node-3
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
discovery.zen.ping.unicast.hosts: ["192.168.204.209","192.168.204.203","192.168.204.108"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
- 192.168.204.108 elasticsearch.yml
cluster.name: zdd
node.name: node-2
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
discovery.zen.ping.unicast.hosts: ["192.168.204.209","192.168.204.203","192.168.204.108"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
启动后的效果也基本和上面伪集群的方式启动一致,就不再这里描述了。所以这种集群其实更容易搭建,唯一需要注意的就是各个机器之间必须保持相互通信。
读写请求流程
写请求
下面是官网描述请求流程的图
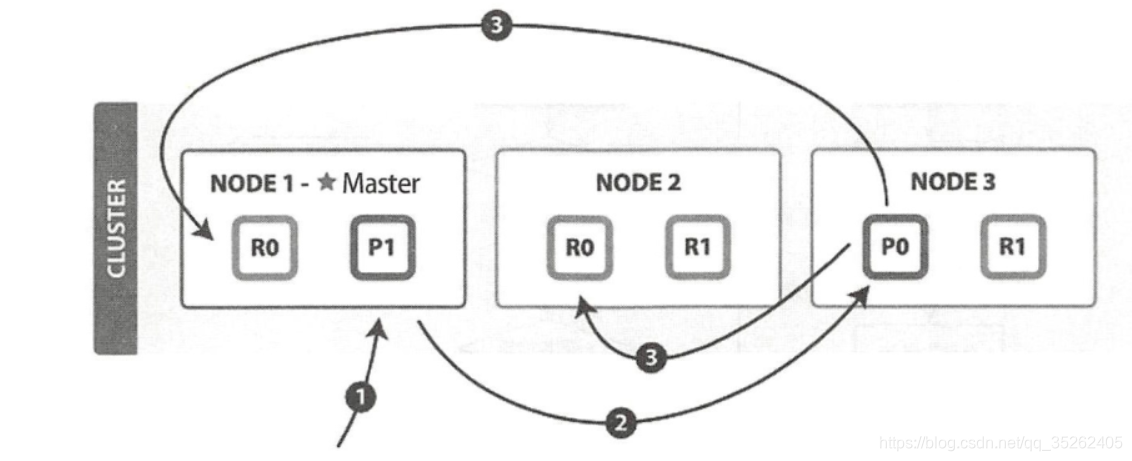
写请求的流程如下:
- 客户端向 NODE1发送写请求;
- 检查Active的Shard数;
- NODE1使用文档 ID 来确定文档属于分片 0,通过集群状态中的内容路由表信息获知分片 0 的主分片位于NODE3,因此请求被转发到 NODE3 上;
- NODE3 上的主分片执行写操作,如果写入成功,则它将请求并行转发到NODE1和NODE2的副分片上,等待返回结果。当所有的副分片都报告成功,NODE3 将向协调节点报告成功,协调节点再向客户端报告成功。
- 失败的副分片会重试,如果实在没有能够写入成功,那么主节点会将这个分片隔离移除,这个过程就是广播给其他节点告诉它们这个情况,这个过程需要时间,这也是为什么可能出现数据不同步的问题。
在客户端收到成功响应时 ,意味着写操作已经在主分片和所有副分片都执行完成。
为什么要检查Active的Shard数?
ES中有一个参数,叫做waitforactiveshards,这个参数是Index的一个setting,也可以在请求中带上这个参数。这个参数的含义是,在每次写入前,该shard至少具有的active副本数。假设我们有一个Index,其每个Shard有3个Replica,加上Primary则总共有4个副本。如果配置waitforactiveshards为3,那么允许最多有一个Replica挂掉,如果有两个Replica挂掉,则Active的副本数不足3,此时不允许写入。
这个参数默认是1,即只要Primary在就可以写入,起不到什么作用。如果配置大于1,可以起到一种保护的作用,保证写入的数据具有更高的可靠性。但是这个参数只在写入前检查,并不保证数据一定在至少这些个副本上写入成功,所以并不是严格保证了最少写入了多少个副本。
在以前的版本中,是写一致性机制,现被替换为waitforactiveshards
- one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行。
- all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作。
- quorum:要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作。
写一致性的默认策略是 quorum,即多数的分片(其中分片副本可以是主分片或副分片)在写入操作时处于可用状态。
put /index/type/id?consistency=quorum
quroum = int( (primary + number_of_replicas) / 2 ) + 1
| 参数 | 简介 |
|---|---|
| version | 设置文档版本号,主要用于实现乐观锁 |
| version_type | 详见版本类型 |
| op_type | 可设置为 create,代表仅在文档不存在时才写入,如果文档己存在,则写请求将失败 |
| routing | ES默认使用文档ID进行路由,指定 routing 可使用 routing 值进行路由 |
| wait_for_active_shards | 用于控制写一致性,当指定数量的分片副本可用时才执行写入,否则重试直至超时 。默认为 l , 主分片可用,即执行写入 |
| refresh | 写入完毕后执行 refresh,使其对搜索可见 |
| timeout | 请求超时时间,默认为 l 分钟 |
| pipeline | 指定事先创建好的 pipeline 名称 |
写入Primary完成后,为何要等待所有Replica响应(或连接失败)后返回
在更早的ES版本,Primary和Replica之间是允许异步复制的,即写入Primary成功即可返回。但是这种模式下,如果Primary挂掉,就有丢数据的风险,而且从Replica读数据也很难保证能读到最新的数据。所以后来ES就取消异步模式了,改成Primary等Replica返回后再返回给客户端。
因为Primary要等所有Replica返回才能返回给客户端,那么延迟就会受到最慢的Replica的影响,这确实是目前ES架构的一个弊端。之前曾误认为这里是等wait_for_active_shards个副本写入成功即可返回,但是后来读源码发现是等所有Replica返回的。
如果Replica写入失败,ES会执行一些重试逻辑等,但最终并不强求一定要在多少个节点写入成功。在返回的结果中,会包含数据在多少个shard中写入成功了,多少个失败了。
读请求
首先我们需要了解一下我们存储的数据是如何存放的,还有就是es是如何把它们转换成一个容易搜索的数据的。
这里就牵扯到es底层通过lucene将需要存储的数据做了处理,这里就不详细分析处理的过程,只要知道它会把数据分成以段为最小单位的数据存储在内存和磁盘中,当然这是需要时间的。
所以我们搜索es中的数据是有延迟的,但是如果我们搜索id那就是实时性的。下面就是es对于写入的数据是如何处理的。
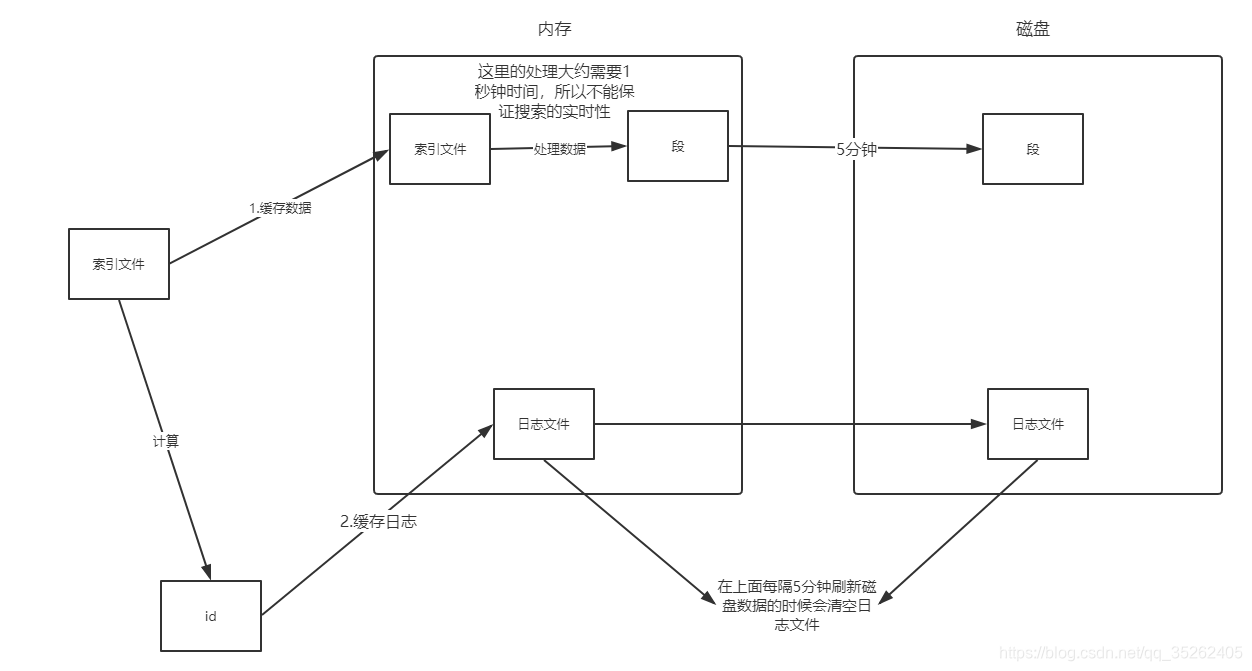
需要注意的是es是先将数据写入内存才缓存的日志的,而且因为数据处理的时候需要一定的时间,而且我们搜索正是需要使用这些处理后的数据,所以它是由延迟的。
至于为什么我们通过id查询就可以实时查询到数据是因为根据id搜索会首先通过日志文件查找,而日志文件基本就是实时存储的,我们只要在数据刷新到磁盘的间隔内的日志都会存储在内存中,而且如果在日志中找不到才会查询内存或磁盘中处理后的数据。
为什么需要存储日志数据?
为了保证数据的可靠性,因为内存中的数据刷入磁盘需要时间,而且也并不是实时都在刷新,在还没将数据刷入磁盘之前如果es挂掉了,我们再此启动内存中的数据就丢失了。
但是如果我们保存了日志文件,就可以通过日志将丢失的数据恢复过来,而且也不需要担心日志为了将过大,在将数据刷入磁盘后就会把日志文件(内存和磁盘)都清除掉,意思就是日志文件只会保存我们已经存在内存还未刷入磁盘的数据的日志文件。
为什么需要先存数据再存日志?
保证日志没有错误日志,因为日志是为了保证数据的可靠性而存在的,所以它必须保证和我们真实的内存数据一致。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









