







 本文深入探讨了机器学习中的关键概念,包括训练误差与测试误差的定义及其在模型评估中的作用,过拟合问题的解释与示例,正则化作为防止过拟合的策略,以及L0、L1和L2范数的差异。此外,还介绍了交叉验证的不同类型,如简单交叉验证、N折交叉验证和留一交叉验证,以及它们在模型选择中的应用。最后,文章强调了泛化能力作为学习方法的核心,并讨论了如何通过测试误差来衡量模型的泛化性能。
本文深入探讨了机器学习中的关键概念,包括训练误差与测试误差的定义及其在模型评估中的作用,过拟合问题的解释与示例,正则化作为防止过拟合的策略,以及L0、L1和L2范数的差异。此外,还介绍了交叉验证的不同类型,如简单交叉验证、N折交叉验证和留一交叉验证,以及它们在模型选择中的应用。最后,文章强调了泛化能力作为学习方法的核心,并讨论了如何通过测试误差来衡量模型的泛化性能。
1.训练误差与测试误差
机器学习的目的就是使学习得到的模型不仅对训练数据有好的表现能力,同时也要对未知数据具有很好的预测能力,因此给定损失函数的情况下,我们可以得到模型的训练误差(训练集)和测试误差(测试集),根据模型的训练误差和测试误差,我们可以评价学习得到的模型的好坏。
同时需要注意的是,统计学习方法具体采用的损失函数未必是评估时使用的损失函数,两者相同的情况下是比较理想的。
假设我们最终学习到的模型是Y = f(x),训练误差是模型Y = f(x)关于训练数据集的经验损失:
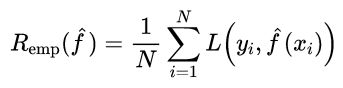
其中N是训练集样本数量。
测试误差是模型Y = f(x)关于测试数据集的经验损失:
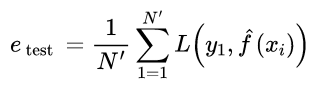
其中N'是测试集样本数量。
2.过拟合问题
上一篇文章中已经简单介绍了过拟合问题,现在详细介绍一下过拟合问题:
当假设空间含有不同复杂度时的模型时,就要面临模型选择的问题。现在假设存在一个“真模型”,能够完美的对数据进行分类,所以当我们选择模型时,希望能够找到一个无限逼近“真模型”的一个模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









