







大家好,我是程序锅。
github上的代码封装程度高,不利于小白学习入门。
常规的大模型RAG框架有langchain等,但是langchain等框架源码理解困难,debug源码上手难度大。
因此,我写了一个人人都能看懂、人人都能修改的大模型RAG框架代码。
整体项目结构如下图所示:手把手教你大模型RAG框架架构

整个小项目分为10个章节,和github高度封装的RAG代码不同,我们将从0到1搭建大模型RAG问答系统,所有代码均整理放置在Github:ai-app,有需要的朋友自取。

上一篇文章,我介绍了通过一个小项目实现了大模型RAG。
本篇文章将介绍6.更换embedding模型.
带大家修改里面的Embedding部分,替换成自己本地部署的Embedding模型,并且尝试多模态和单模态两种方式。
一、Embedding原理介绍
一句话说明白Embedding的原理:用向量来表示对象,并衡量对象之间相关性。
1.什么叫做表示对象呢?
我们知道,计算机在处理任何形式的数据时,处理的都是数字,更极端点处理的都是二进制数字。不论是显示图片、文本,还是播放语音、视频,在计算机看来都是数据流。
因此,计算机在处理文本时,只有将文本转换成数字形式才能进行计算,而词嵌入表示就是为了解决这个问题。
这里举一个最简单的例子one-hot编码的概念。
比如,“程序锅讲大模型”这七个字,分别对应“0-6”。由于计算机只能识别"0"和"1",可将每个字表示为"0"和"1"组成的向量,如下图所示。
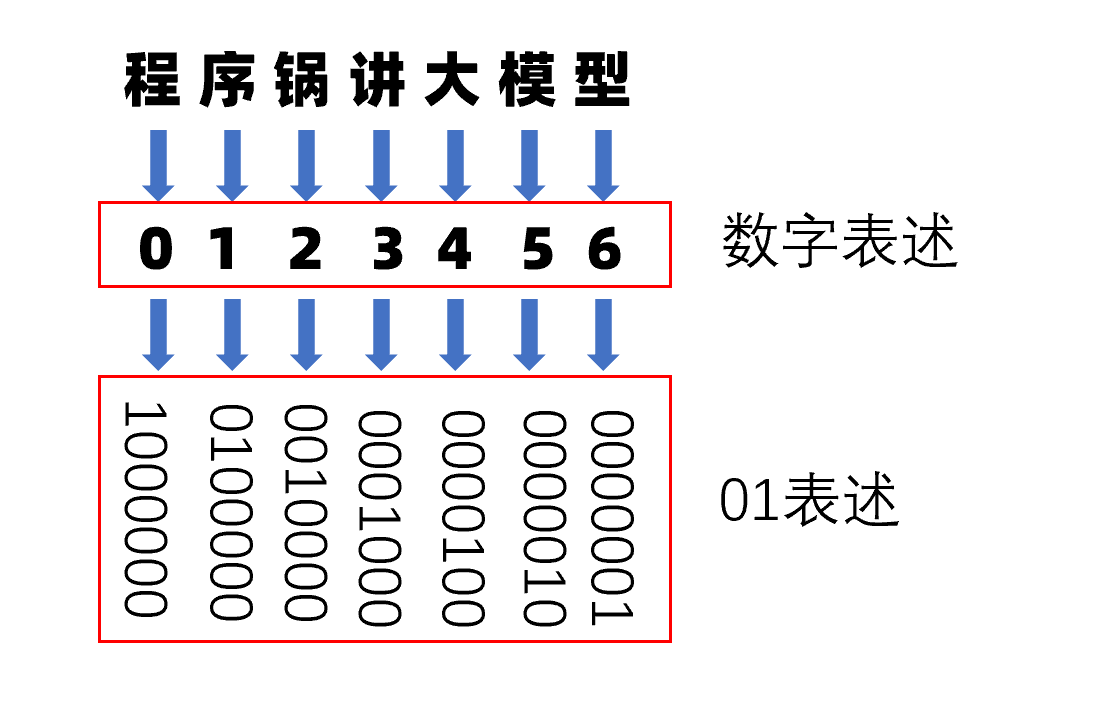
对象表示是没问题了,但是发现一个问题:用one-hot编码向量之间是没关系的。
是否能够很好衡量向量之间的关系,这是衡量一个Embedding模型好坏的关键。
所以,下面我将介绍如何衡量向量之间的关系。
2.衡量向量之间的关系
embedding模型的性质是能使距离相近的向量对应的物体有相近的含义,比如 Embedding(七龙珠)和Embedding(魔人布欧)之间的距离就会很接近,但 Embedding(七龙珠)和Embedding(乱世佳人)的距离就会远一些。
网上常用的向量模型有:word2vec、Bert等。大模型厂商也会用API提供embedding模型,比如ChatGPT、智谱等等。
通过前面的小项目调用智谱GLM4的接口,我们初步了解大模型embedding能干啥。
下面我们将采用paddleNLp的embedding模型,亲自本地化部署并集成到项目中,涉及多模态和单模态两个版本。
paddleNlp Embedding介绍
飞桨(PaddlePaddle)是集深度学习核心框架、工具组件和服务平台为一体的技术先进、功能完备的开源深度学习平台;使用这个平台,你可以轻松构建模型,清洗数据等。
PaddleNLP依赖于PaddlePaddle,它是百度提供的开源工具,提供开箱即用的产业级NLP预置任务能力,无需训练,一键预测。
PaddleNLP Embedding是PaddleNLP中的一个模块。
PaddleNLP Embedding分为多模态和单模态两个版本,其中多模态适用于图片和文本作为输入,而单模态只适用于文本作为输入。
整体逻辑关系如下所示:

- 多模态Embedding
多模态学习可以聚合多源数据的信息,使得模型学习到的表示更加完备。以视频分类为例,同时使用字幕标题等文本信息、音频信息和视觉信息的多模态模型要显著好于只使用任意一种信息的单模态模型,这已经被多篇文章实验验证过。
PaddleNLP Embedding中可以使用的多模态模型如下表所示。
| 模型 | 视觉 | 文本 | 语言 |
|---|---|---|---|
PaddlePaddle/ernie_vil-2.0-base-zh (默认) |
ViT | ERNIE | 中文 |
OFA-Sys/chinese-clip-vit-base-patch16 |
ViT-B/16 | RoBERTa-wwm-Base | 中文 |
OFA-Sys/chinese-clip-vit-large-patch14 |
ViT-L/14 | RoBERTa-wwm-Base | 中文 |
OFA-Sys/chinese-clip-vit-large-patch14-336px |
ViT-L/14 | RoBERTa-wwm-Base | 中文 |
- 单模态Embedding
PaddleNLP Embedding可以使用的单模态模型如下表所示:
| 模型 | 层数 | 维度 | 语言 |
|---|---|---|---|
rocketqa-zh-dureader-query-encoder |
12 | 768 | 中文 |
rocketqa-zh-dureader-para-encoder |
12 | 768 | 中文 |
rocketqa-zh-base-query-encoder |
12 | 768 | 中文 |
rocketqa-zh-base-para-encoder |
12 | 768 | 中文 |
moka-ai/m3e-base |
12 | 768 | 中文 |
rocketqa-zh-medium-query-encoder |
6 | 768 | 中文 |
rocketqa-zh-medium-para-encoder |
6 | 768 | 中文 |
rocketqa-zh-mini-query-encoder |
6 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









