







 超级会员免费看
超级会员免费看
 本文深入解析HRNet(高分辨率网络),对比现有方法,详细介绍了其并行高分辨率子网和重复多尺度融合策略。实验表明,这种方法在保持高分辨率的同时,能提高姿态估计的准确性。此外,还探讨了代码实现的关键部分,如ResNet模块和HighResolutionModule。
本文深入解析HRNet(高分辨率网络),对比现有方法,详细介绍了其并行高分辨率子网和重复多尺度融合策略。实验表明,这种方法在保持高分辨率的同时,能提高姿态估计的准确性。此外,还探讨了代码实现的关键部分,如ResNet模块和HighResolutionModule。
HRNet阅读笔记及代码理解
摘要:
大多数现有方法从由高到低分辨率网络产生的低分辨率表示中恢复高分辨率表示。相反,本文在整个过程中保持高分辨率的表示。我们将高分辨率子网开始作为第一阶段,逐步添加高到低分辨率子网以形成更多阶段,并行连接多个子网,每个子网具有不同的分辨率。我们进行重复的多尺度融合,使得高到低分辨率表示可以重复从其他分辨率的表示获取信息,从而导致丰富的高分辨率表示。因此,预测的关键点热图可能更准确,空间更精确。
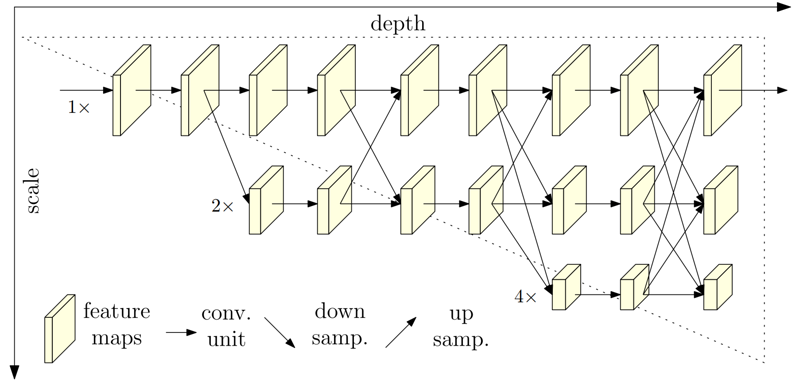
1. 简介
1.1 现有方法
- (a) 对称结构,先下采样,再上采样,同时使用跳层连接恢复下采样丢失的信息;
- (b) 级联金字塔;
- (c) 先下采样,转置卷积上采样,不使用跳层连接进行数据融合;
- (d) 扩张卷积,减少下采样次数,不使用跳层连接进行数据融合;
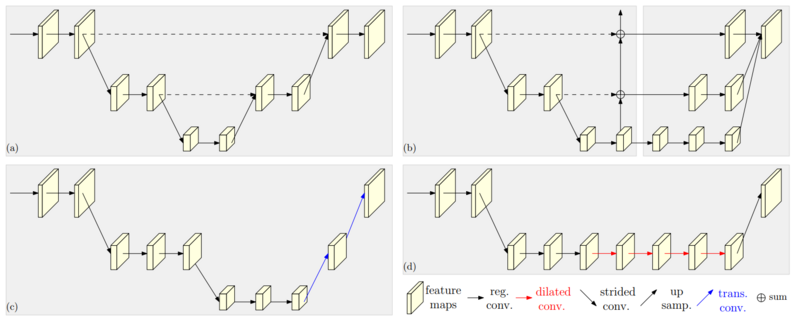
1.2 HRNet
简要描述:
HighResolution Net(HRNet),它能够在整个过程中保持高分辨率表示。以高分辨率子网开始作为第一阶段,逐个添加高到低分辨率子网以形成更多阶段,并且 并行连接多分辨率子网。在整个过程中反复交换并行多分辨率子网络中的信息来进行 重复的多尺度融合。优点:
- (a)并行连接高低分辨率子网,而不是像大多数现有解决方案那样串联连接。因此,我们的方法能够保持高分辨率而不是通过从低到高的过程恢复分辨率,因此预测的热图可能在空间上更精确
- (b)大多数现有的融合方案汇总了低级别和高级别的表示。相反,我们在相同深度和相似水平的低分辨率表示的帮助下执行重复的多尺度融合以提升高分辨率表示,反之亦然,导致高分辨率表示对于姿势估计也是丰富的。因此,我们预测的热图可能更准确。个人感觉增加多尺度信息之间的融合是正确的,例如原图像和模糊图像进行联合双边滤波可以得到介于两者之间的模糊程度的图像,而RGF滤波就是重复将联合双边滤波的结果作为那张模糊的引导图,这样得到的结果会越来越趋近于原图。此处同样的道理,不同分辨率的图像采样到相同的尺度反复的融合,加之网络的学习能力,会使得多次融合后的结果更加趋近于正确的表示。
2. 方法描述
2.1 并行高分辨率子网
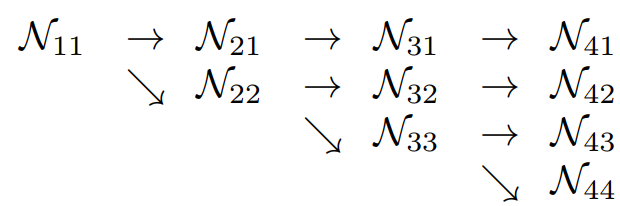
2.2 重复多尺度融合
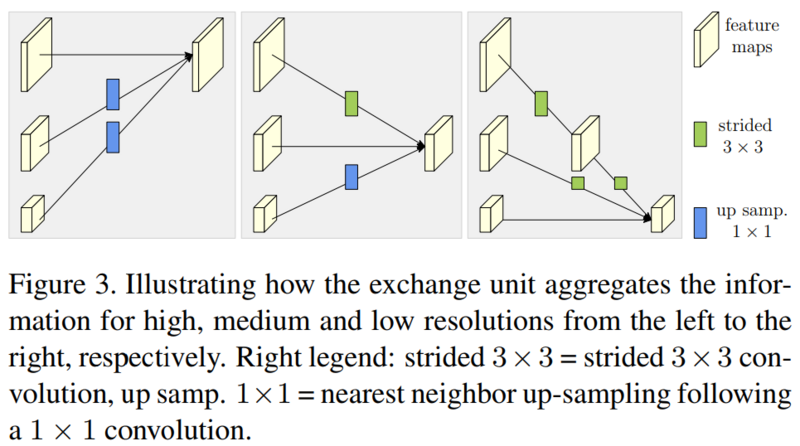
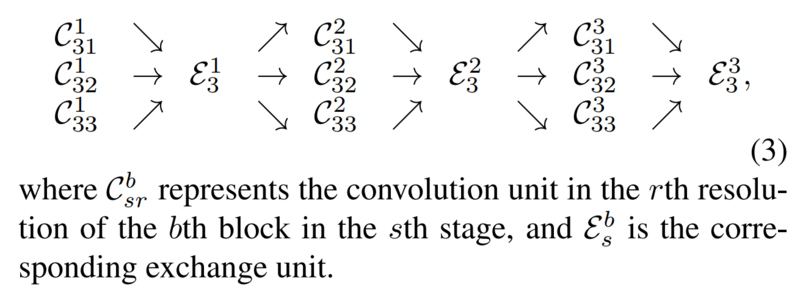
3. 实验部分
3.1 消融研究
3.1.1 重复多尺度融合
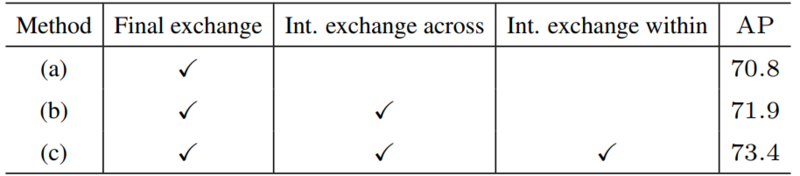
- (a) W / o中间交换单元(1个融合):除最后一个交换单元外,多分辨率子网之间没有交换;
- (b) 仅W /跨阶段交换单元(3个融合):每个阶段内并行子网之间没有交换;
- (c) W /跨阶段和阶段内交换单元(共8个融合):这是我们提出的方法;
3.1.2 分辨率保持
所有四个高到低分辨率子网都在开头添加,深度相同,融合方案与我们的相同。该变体实现了72.5的AP,低于我们的小型网HRNet-W32的73.4 AP。我们认为原因是从低分辨率子网上的早期阶段提取的低级功能不太有用。此外,没有低分辨率并行子网的类似参数和计算复杂度的简单高分辨率网络表现出低得多的性能。
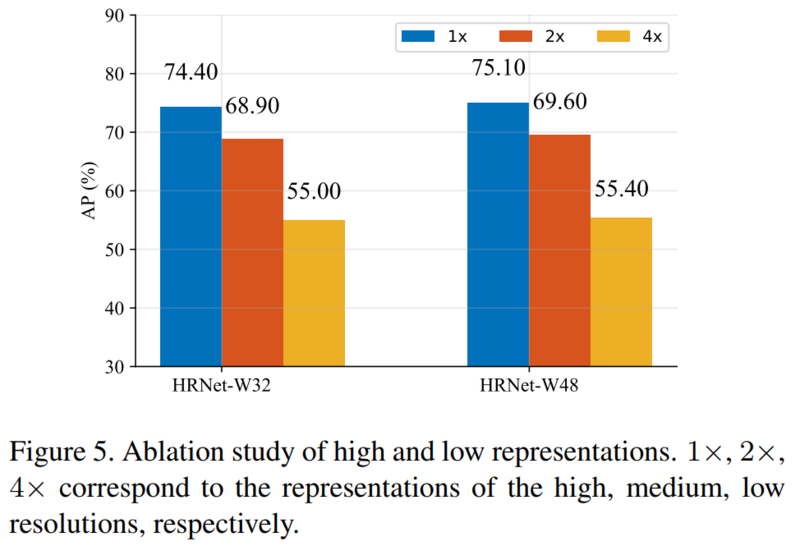
3.1.3 分辨率表示质量
检查从每个分辨率的特征图估计的热图的质量。
4. 代码学习(源码地址)
4.1 ResNet模块
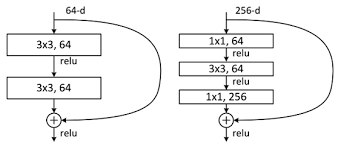
虽然很熟悉了,但是还是介绍一下resnet网络的基本模块。如下的左图对应于resnet-18/34使用的基本块,右图是50/101/152所使用的,由于他们都比较深,所以有图相比于左图使用了1x1卷积来降维。
- (a)
conv3x3: 没啥好解释的,将原有的pytorch函数固定卷积和尺寸为3重新封装了一次;(b)
BasicBlock: 搭建上图左边的模块。(1) 每个卷积块后面连接BN层进行归一化;(2) 残差连接前的3x3卷积之后只接入BN,不使用ReLU,避免加和之后的特征皆为正,保持特征的多样;
(3) 跳层连接:两种情况,当模块输入和残差支路(3x3->3x3)的通道数一致时,直接相加;当两者通道不一致时(一般发生在分辨率降低之后,同分辨率一般通道数一致),需要对模块输入特征使用1x1卷积进行升/降维(步长为2,上面说了分辨率会降低),之后同样接BN,不用ReLU。
(c)
Bottleneck: 搭建上图右边的模块。(1) 使用1x1卷积先降维,再使用3x3卷积进行特征提取,最后再使用1x1卷积把维度升回去;(2) 每个卷积块后面连接BN层进行归一化;
(2) 残差连接前的1x1卷积之后只接入BN,不使用ReLU,避免加和之后的特征皆为正,保持特征的多样性。
(3) 跳层连接:两种情况,当模块输入和残差支路(1x1->3x3->1x1)的通道数一致时,直接相加;当两者通道不一致时(一般发生在分辨率降低之后,同分辨率一般通道数一致),需要对模块输入特征使用1x1卷积进行升/降维(步长为2,上面说了分辨率会降低),之后同样接BN,不用ReLU。
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out4.2 HighResolutionModule (高分辨率模块)
当仅包含一个分支时,生成该分支,没有融合模块,直接返回;当包含不仅一个分支时,先将对应分支的输入特征输入到对应分支,得到对应分支的输出特征;紧接着执行融合模块。
- (a)
_check_branches: 判断num_branches (int)和num_blocks, num_inchannels, num_channels (list)三者的长度是否一致,否则报错;(b)
_make_one_branch: 搭建一个分支,单个分支内部分辨率相等,一个分支由num_blocks[branch_index]个block组成,block可以是两种ResNet模块中的一种;
- (1) 首先判断是否降维或者输入输出的通道(
num_inchannels[branch_index]和 num_channels[branch_index] * block.expansion(通道扩张率))是否一致,不一致使用1z1卷积进行维度升/降,后接BN,不使用ReLU;- (2) 顺序搭建
num_blocks[branch_index]个block,第一个block需要考虑是否降维的情况,所以单独拿出来,后面1 到 num_blocks[branch_index]个block完全一致,使用循环搭建就行。此时注意在执行完第一个block后将num_inchannels[branch_index重新赋值为num_channels[branch_index] * block.expansion。- (c)
_make_branches: 循环调用_make_one_branch函数创建多个分支;(d)
_make_fuse_layers:
- (1) 如果分支数等于1,返回None,说明此事不需要使用融合模块;
(2) 双层循环:
for i in range(num_branches if self.multi_scale_output else 1):的作用是,如果需要产生多分辨率的结果,就双层循环num_branches次,如果只需要产生最高分辨率的表示,就将i确定为0。
- (2.1) 如果
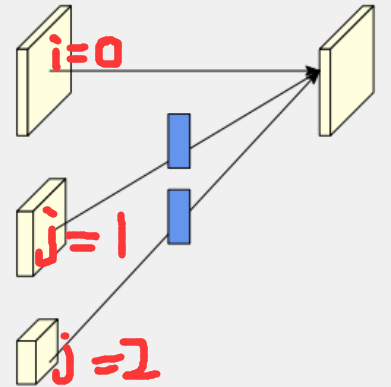
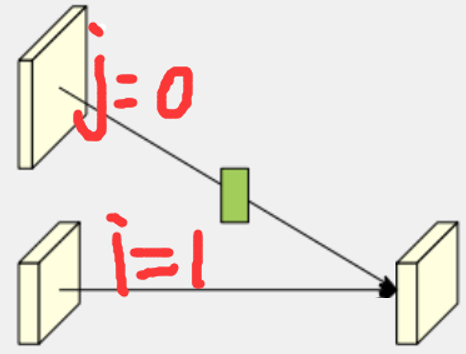
j > i,此时的目标是将所有分支上采样到和i分支相同的分辨率并融合,也就是说j所代表的分支分辨率比i分支低,2**(j-i)表示j分支上采样这么多倍才能和i分支分辨率相同。先使用1x1卷积将j分支的通道数变得和i分支一致,进而跟着BN,然后依据上采样因子将j分支分辨率上采样到和i分支分辨率相同,此处使用最近邻插值;
- (2.2) 如果
j = i,也就是说自身与自身之间不需要融合,nothing to do;(2.3) 如果
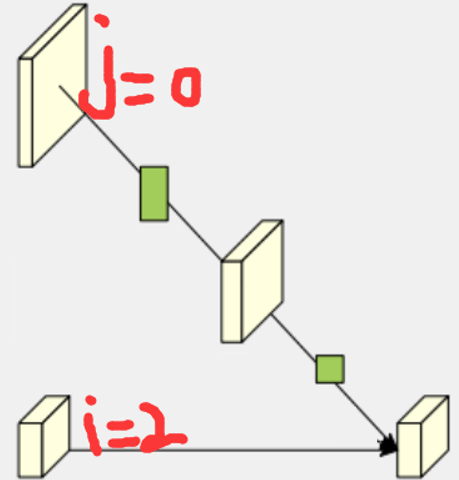
j < i,转换角色,此时最终目标是将所有分支采样到和i分支相同的分辨率并融合,注意,此时j所代表的分支分辨率比i分支高,正好和(2.1)相反。此时再次内嵌了一个循环,这层循环的作用是当i-j > 1时,也就是说两个分支的分辨率差了不止二倍,此时还是两倍两倍往上采样,例如i-j = 2时,j分支的分辨率比i分支大4倍,就需要上采样两次,循环次数就是2;
- (2.3.1) 当
k == i - j - 1时,举个例子,i = 2,j = 1, 此时仅循环一次,并采用当前模块,此时直接将j分支使用3x3的步长为2的卷积下采样(不使用bias),后接BN,不使用ReLU;
- (2.3.2) 当
k != i - j - 1时,举个例子,i = 3,j = 1, 此时循环两次,先采用当前模块,将j分支使用3x3的步长为2的卷积下采样(不使用bias)两倍,后接BN和ReLU,紧跟着再使用(2.3.1)中的模块,这是为了保证最后一次二倍下采样的卷积操作不使用ReLU,猜测也是为了保证融合后特征的多样性;
(e)
forward: 前向传播函数,利用以上函数的功能搭建一个HighResolutionModule;
- (1) 当仅包含一个分支时,生成该分支,没有融合模块,直接返回;
(2) 当包含不仅一个分支时,先将对应分支的输入特征输入到对应分支,得到对应分支的输出特征;紧接着执行融合模块;
- (2.1) 循环将对应分支的输入特征输入到对应分支模型中,得到对应分支的输出特征;
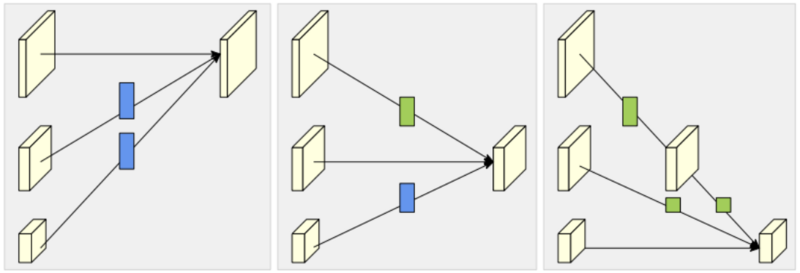
- (2.2) 融合模块:对着这张图看,很容易看懂。每次多尺度之间的加法运算都是从最上面的尺度开始往下加,所以
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0]);加到他自己的时候,不需要经过融合函数的处理,直接加,所以if i == j: y = y + x[j];遇到不是最上面的尺度那个特征图或者它本身相同分辨率的那个特征图时,需要经过融合函数处理再加,所以y = y + self.fuse_layers[i][j](x[j])。最后将ReLU激活后的融合(加法)特征append到x_fuse,x_fuse的长度等于1(单尺度输出)或者num_branches(多尺度输出)。
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
num_channels, fuse_method, multi_scale_output=True):
super(HighResolutionModule, self).__init__()
self._check_branches(
num_branches, blocks, num_blocks, num_inchannels, num_channels)
self.num_inchannels = num_inchannels
self.fuse_method = fuse_method
self.num_branches = num_branches
self.multi_scale_output = multi_scale_output
self.branches = self._make_branches(
num_branches, blocks, num_blocks, num_channels)
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(True)
def _check_branches(self, num_branches, blocks, num_blocks,
num_inchannels, num_channels):
if num_branches != len(num_blocks):
error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
num_branches, len(num_blocks))
logger.error(error_msg)
raise ValueError(error_msg)

















 7220
7220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









