




现实生活中,人们往往很难知道总体的均值,比如我知道该网络上网的10000个人平均年龄是20岁,但不能了解该网络人群上网年龄总体均值究竟为多少,可能是30岁可能是25岁,所以往往有个笑话,总体均值是上帝才能知道的。
但是我们可以通过统计学来估计它。
写在前面
假设检验:是当总体均值μ已知时(假设我知道是某个值或者某个区间),我通过统计量的分布来检验该假设是否正确,
置信区间:是当总体均值μ未知时,我通过统计量去估计未知的总体均值在大概的区间里。
假设检验的概念(其实就两步)
第一步:提出假设
第二步:检验假设
假设检验具体的步骤
1.考虑找到提出的假设事件适合它的统计量,并写出它的分布(正态,二项,卡方,t,F等),然后去看总体方差和样本方差是否已知。
在我之前写的4大分布的博文里有介绍


2.然后默认假设成立,对假设事件的分布计算P(p-value)值进行检验
这个概率
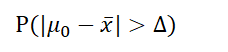
即:总体均值与样本均值之差大于某
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2492
2492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









