







论文综述:基于语言模型的知识图谱嵌入编辑
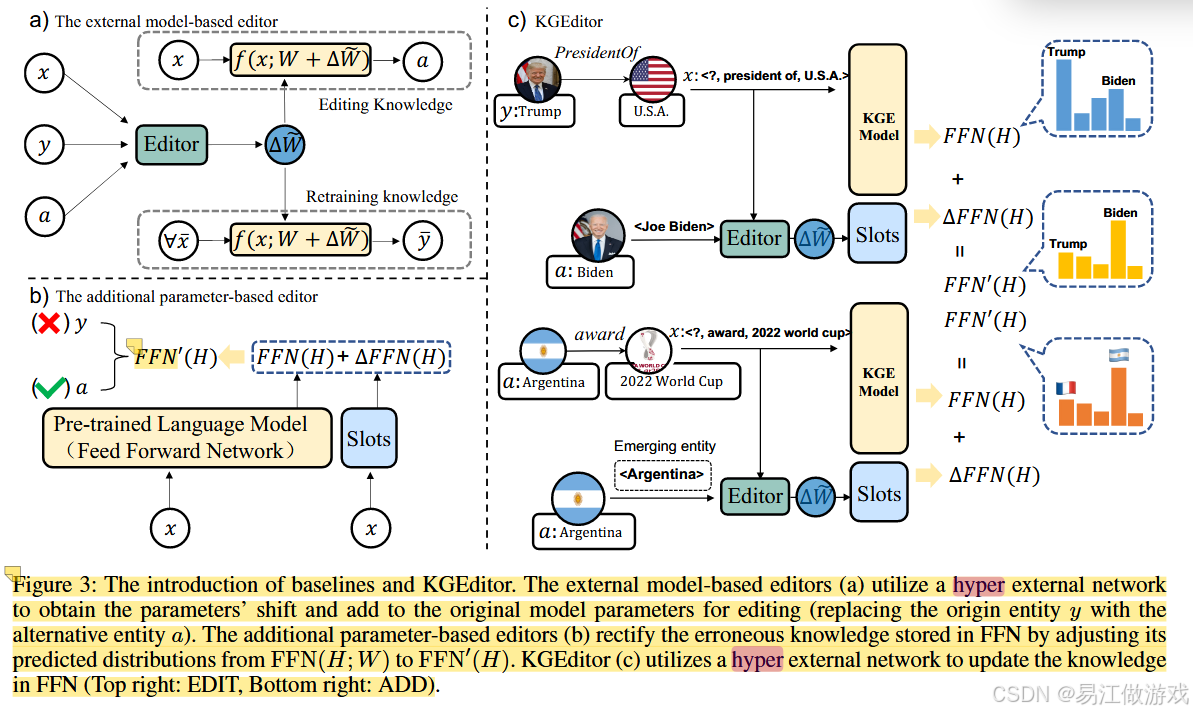
问:怎么最低成本的编辑三元组,同时更新三元组对应的网络里面的嵌入?
解:用一个额外的LSTM超网络更新目标网络的部分超参。
作者与机构
本文由浙江大学、浙江大学-蚂蚁集团联合实验室、东海实验室和腾讯平台与内容部的研究人员共同撰写。主要作者包括Siyuan Cheng、Ningyu Zhang、Bozhong Tian等。
摘要
近年来,通过语言模型框架化知识图谱(KG)嵌入取得了显著的实证成功。然而,基于语言模型的KG嵌入通常作为静态工件部署,这使得在部署后修改变得困难。为了解决这一问题,本文提出了一项新的任务——编辑基于语言模型的KG嵌入。该任务旨在实现对KG嵌入的快速、数据高效的更新,而不会影响其他方面的性能。为此,我们构建了四个新数据集:E-FB15k237、A-FB15k237、E-WN18RR和A-WN18RR,并评估了几种知识编辑基线,展示了先前模型处理这一挑战性任务的有限能力。我们进一步提出了一个简单但强大的基线模型——KGEditor,该模型利用超网络中的额外参数层来编辑或添加事实。实验结果表明,KGEditor在有限的训练资源下能够高效地更新特定事实而不影响整体性能。
引言
知识图谱(KG)表示大规模、多关系的图结构,包含丰富的符号事实。这些结构为各种知识密集型任
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









