







数据处理
-
测试集验证集划
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(pdData.iloc[:,:2], pdData.iloc[:,2:], test_size=0.3, random_state=0)- 标准化和归一化的区别
归一化其实就是标准化的一种方式,只不过归一化是将数据映射到了[0,1]这个区间中。
标准化则是将数据按照比例缩放,使之放到一个特定区间中。标准化后的数据的均值=0,标准差=1,因而标准化的数据可正可负。先求出全部数据的均值和方差,再进行计算,当原始数据并不符合高斯分布的话,标准化后的数据效果并不好。
-
标准化数据
- 为什么测试集要用训练集的mean和std进行标准化?
- 测试数据也直接用这个scaler训练,这样测试数据用的就是训练数据的分布,如train = [(30,正),(20,正),(10,负)], train_mean=10,tran_std=8.2,标准化后scaled_train = [(1.21,正),(0,正),(-1.21,'负')],可假设小于0为负例进行训练测试集预测test = [5,6,7],如果测试集用了测试集自身的mean和std,则scaled_test = [-1.21,0,1.21],那么只有预测5为负例,显然不符合结果。当用训练集的std和mean,此时scaled_test = [-1.837,-1.715,-1.592],则3个样本都为负例,复合预期
# 标准化的特征,一般以行为样本,列为特征
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(X_train)
norm_X_train = scaler.transform(X_train)
norm_X_train = np.insert(norm_X_train,0,values=1,axis=1) # 给测试数据插入一列
-
归一化数据
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
mm_data = mm.fit_transform(data) # 归一化数据
origin_data = mm.inverse_transform(mm_data) # 将归一化的数据转为原始数据data注意:这里的pdData中行为样本,列为特征。在pca过程中一般可以将行为特征,列为样本
生成分类图
# 生成线性可分的数据点
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=100, centers=2,
random_state=0, cluster_std=0.8) # cluster_std 控制分类的距离
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn');
# 生成线性不可分的数据点
from sklearn.datasets.samples_generator import make_circles
X, y = make_circles(100, factor=.1, noise=.1)
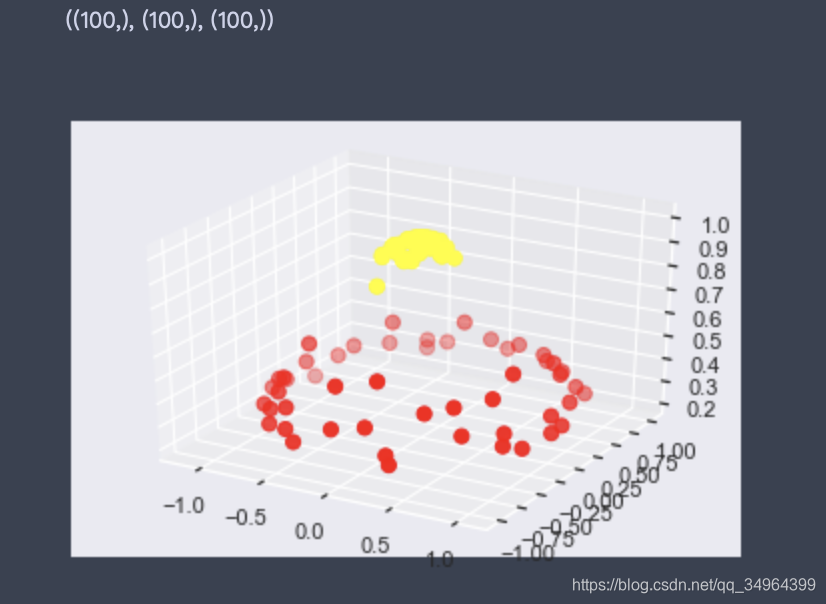
# 画3D散点图
from mpl_toolkits import mplot3d
ax = plt.subplot(projection='3d')
r = np.exp(-(X**2).sum(1))
ax.scatter3D( X[:,0], X[:,1], r,c=y, s=50, cmap='autumn' )
X[:,0].shape, X[:,1].shape, r.shape
画SVM边界
引入
1. ax.contour 画2D等高线
# 等高线
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
# 画3D图
delta = 0.25
x = np.arange(-3.0, 3.0, delta)
y = np.arange(-3.0, 3.0, delta)
X, Y = np.meshgrid(x, y)
Z1 = np.exp(-X**2 - Y**2)
X[:2]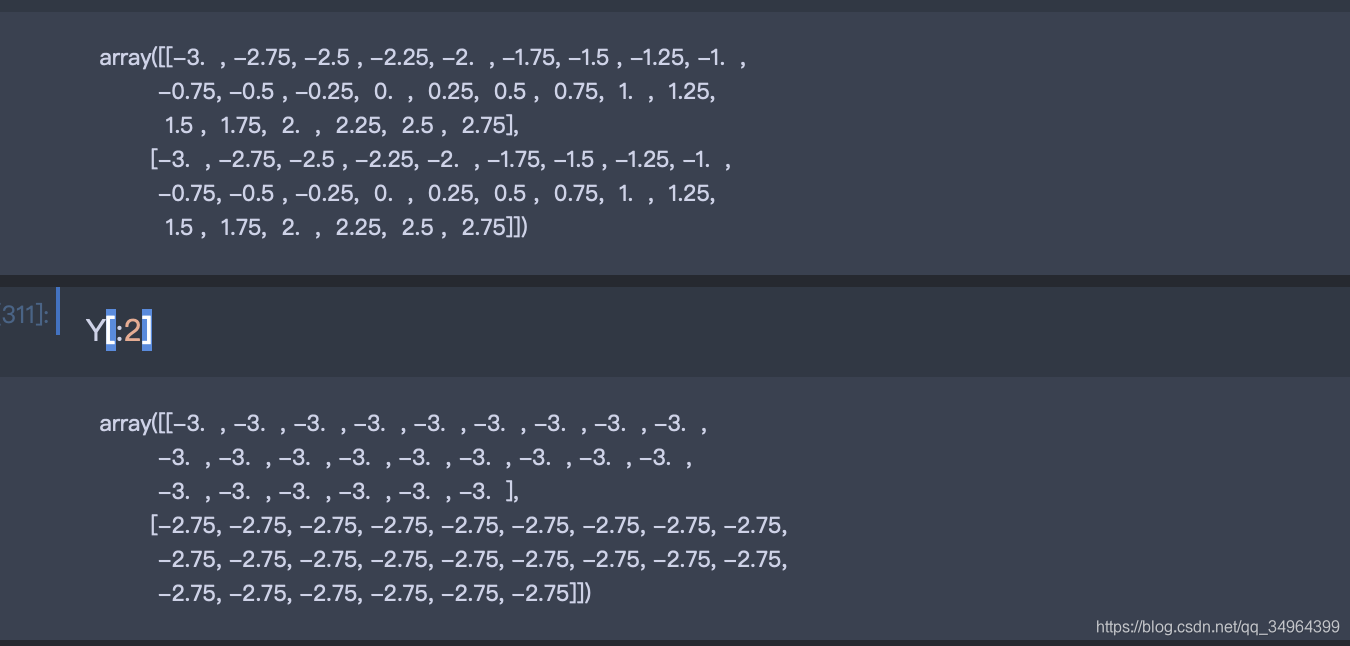
# X和Y的网格坐标范围是 (-3, 3),但是图中的坐标不在-3和3之间,因为等高线是从0.15开始
fig, ax = plt.subplots()
CS = ax.contour(X, Y, np.exp(-X**2 - Y**2) )
ax.clabel(CS, inline=1, fontsize=10)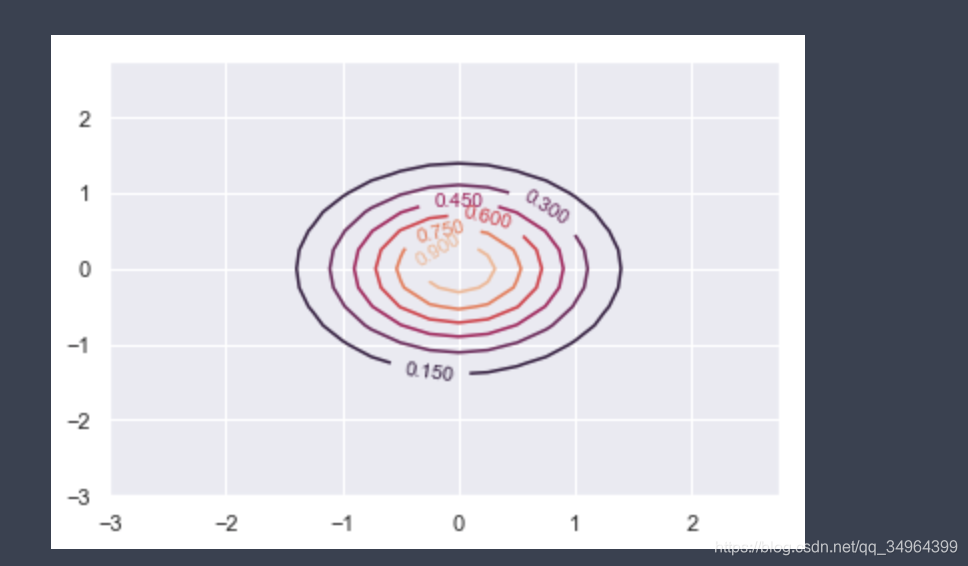
2. ax.plot_surface画3D图 (X1:左边的轴,X2:右边的轴)
fig = plt.figure()
ax = Axes3D(fig)
ax.contour(X, Y, Z1, colors='r') # 加入3D等高线就能看出是通过X,Y,Z的一些点来勾勒出整个图形,然后画出需要的等高线
ax.plot_surface(X, Y, Z1, alpha=0.2)
# X.shape, Y.shape, Z1.shape ((24, 24), (24, 24), (24, 24))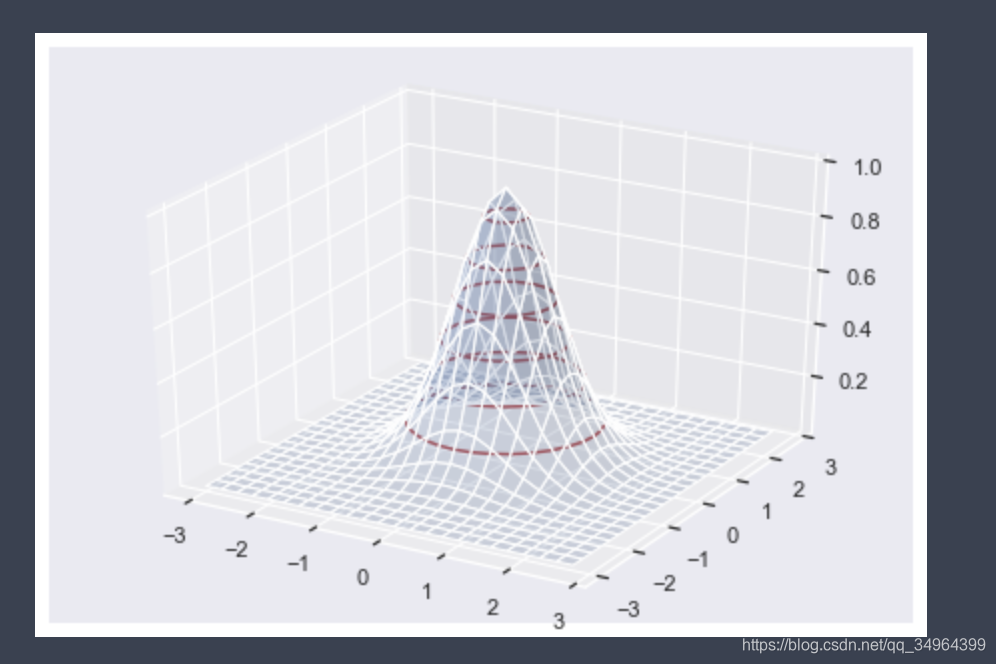
3. ax.contour 画3D指定高度的等高线
fig = plt.figure()
ax = Axes3D(fig)
ax.contour(X, Y, Z1, colors='r', levels=[0.1,0.2,0.5]) # levels 画出对应的0.1,0.2,0.5的 "3维" 等高线, 需要加上colors,不然可能画出2条线
3. ax.contour 画2D指定高度的等高线
根据这一特性可以画出SVM的支持向量所在边界,因为SVM决策边界是获得 值为1和-1的超平面
fig = plt.figure()
plt.contour(X, Y, Z1, colors='r', levels=[0.1,0.2,0.5]) # 画出等高线,根据这一特性可以画出SVM的决策边界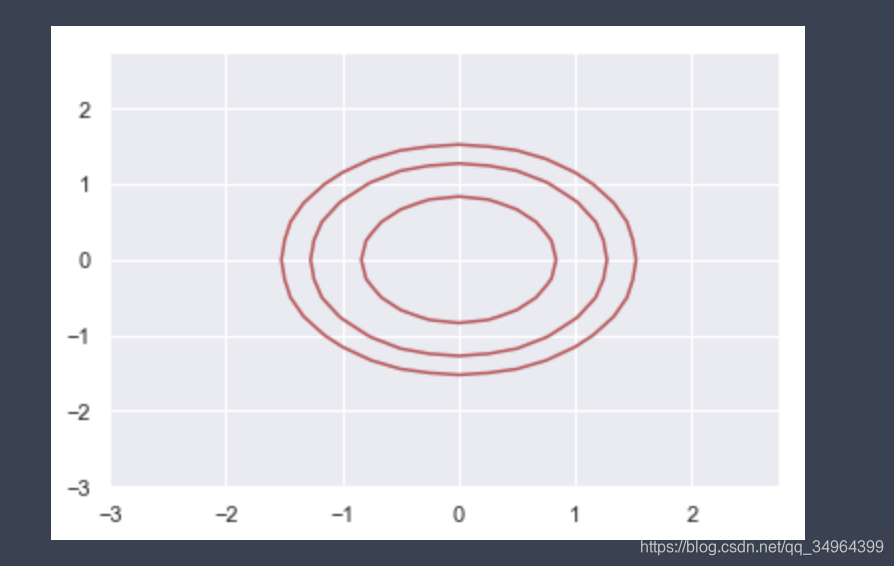
SVM边界
#随机来点数据
from sklearn.datasets.samples_generator import make_blobs
from sklearn.svm import SVC
X, y = make_blobs(n_samples=50, centers=2,
random_state=0, cluster_std=0.60)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn')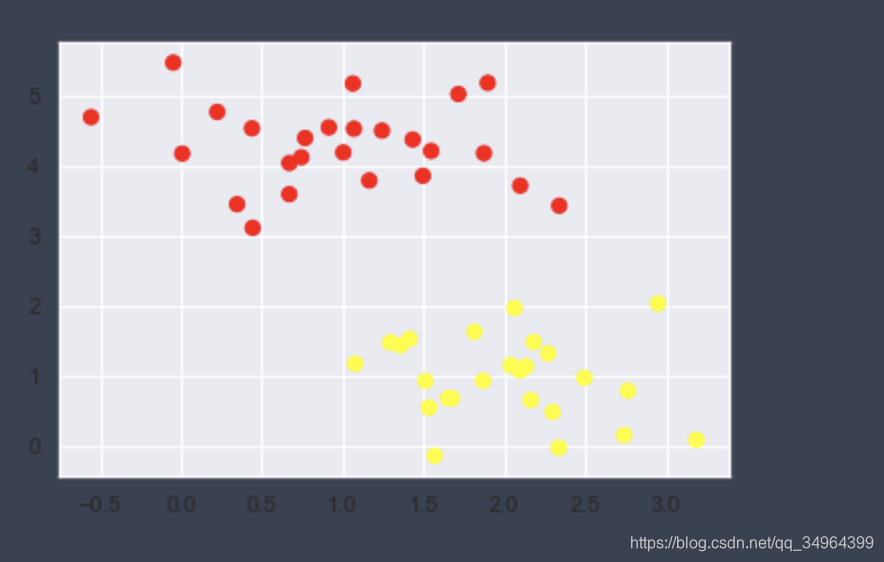
# 训练model
model = SVC(kernel='linear')
model.fit(X, y)model.decision\_function:将数据点代入方程 得到的值,判断是否是支持向量
plt.figure(figsize=(6, 6), dpi=80)
plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap='Spectral')
xlim = plt.xlim()
ylim = plt.ylim()
# 画出网格点
x1 = np.linspace(xlim[0], xlim[1], 30) # 生成30个数字的等差数列
y1 = np.linspace(ylim[0], ylim[1], 30) # 生成30个数字的等差数列
X1, Y1 = np.meshgrid(x1, y1)
# 将网格点变成坐标点
xy = np.vstack( (X1.ravel(), Y1.ravel() ) ).T
# 获得函数值
Z = model.decision_function(xy).reshape(X1.shape)
# 画出支持向量所在直线和超平面
plt.contour(X1, Y1, Z, levels=[-1, 0, 1], colors='b', linestyles=['--','-','--'])
# 圈出支持向量
support_vector = model.support_vectors_
plt.scatter( support_vector[:, 0], support_vector[:, 1], s=100, color='', linewidth=1, edgecolors='b')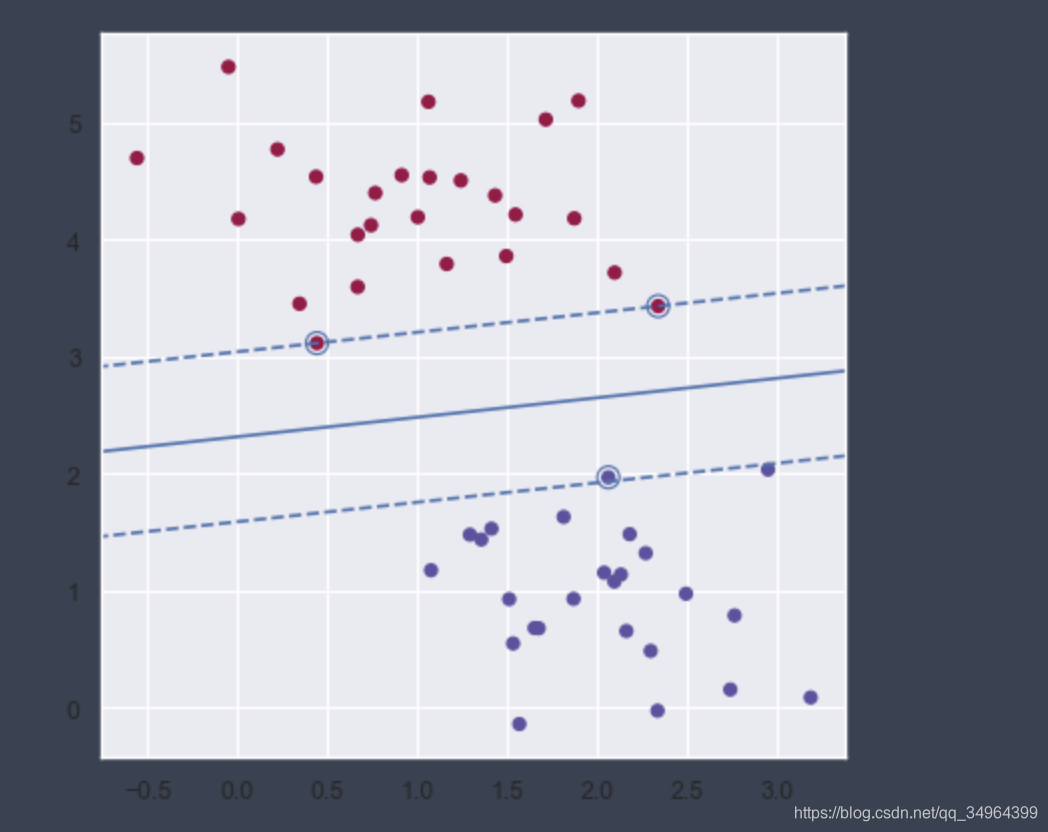
当然也可以通过参数求解方式获得支持向量所在超平面
w = model.coef_[0]
b = model.intercept_[0]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









