






版本信息:OCEANBASE 4.2.1.7
故障现象:sys租户状态显示不可用。直接用如下语句黑屏查询也是显示,内存不足。如下图所示:


与此同时,该集群其他租户的DDL语句,无法执行:
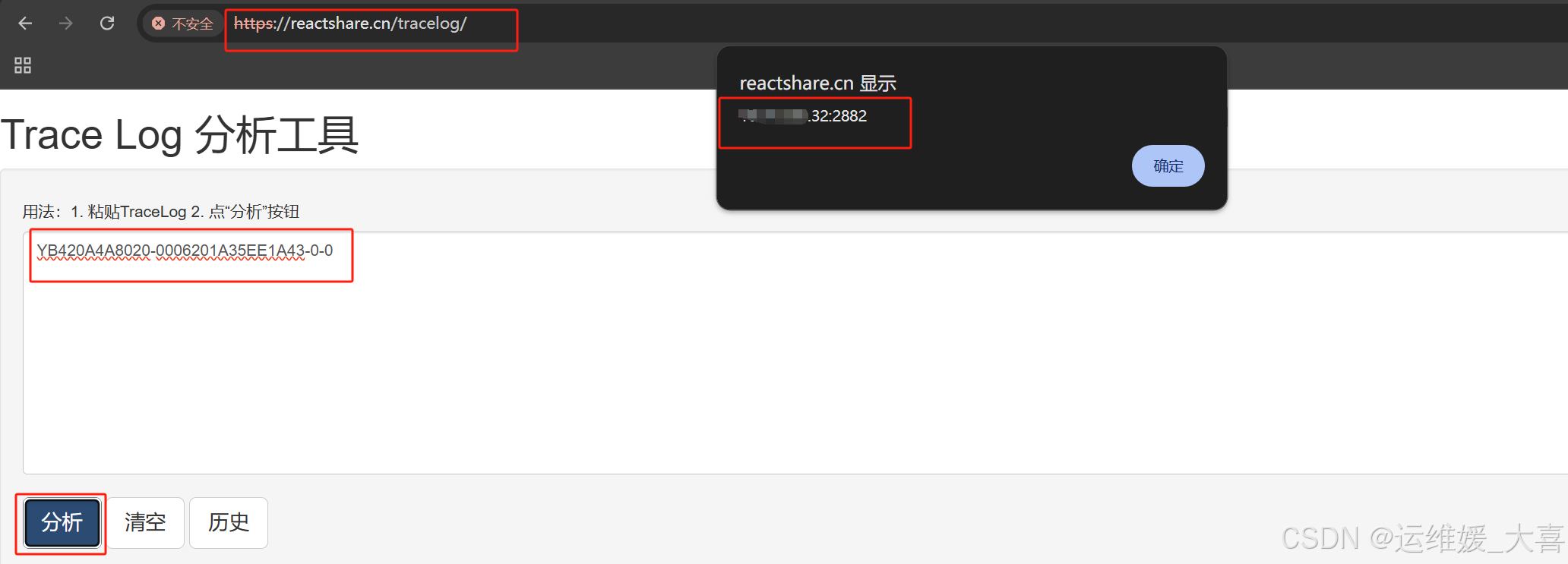
故障定位:使用如下语句在sys租户执行,当出现报错后,继续执行select last_trace_id();获取改报错的traceid信息。

拿到traceid后,在https://reactshare.cn/tracelog/进行traceid的解析,可解析到是来自哪个IP。
根据IP在对应服务器的observer.log中获取完整的信息。

从observer日志中查到,此次报错是在1017租户查询时发生了超时,1017是1018的Meta租户,当前1018租户的内存为8G。

初步怀疑是此租户的内存太小,导致对应Meta租户的内存仅仅1G因而导致超时。计划增加1018租户内存,先尝试用ocp扩容,报错No memory or reach tenant memory limit。
经和1018的业务开发沟通后,进行了切换,尝试切换后还是无法扩容。后又对该节点进行了重启,重启后故障依然未消除。
于是采用黑屏方式进行1018扩容。
Alter resource unit unit_name memory_size‘12G’;
进行了此操作后,再次查询,仍报错:

重复上述定位步骤,发现报错为1019租户,1019为1020的Meta租户,1020当前租户内存8G,于是对1020进行扩容。此外检查了所有当前内存小于10G的租户,均扩容到12G。再次查询后,可正常返回。
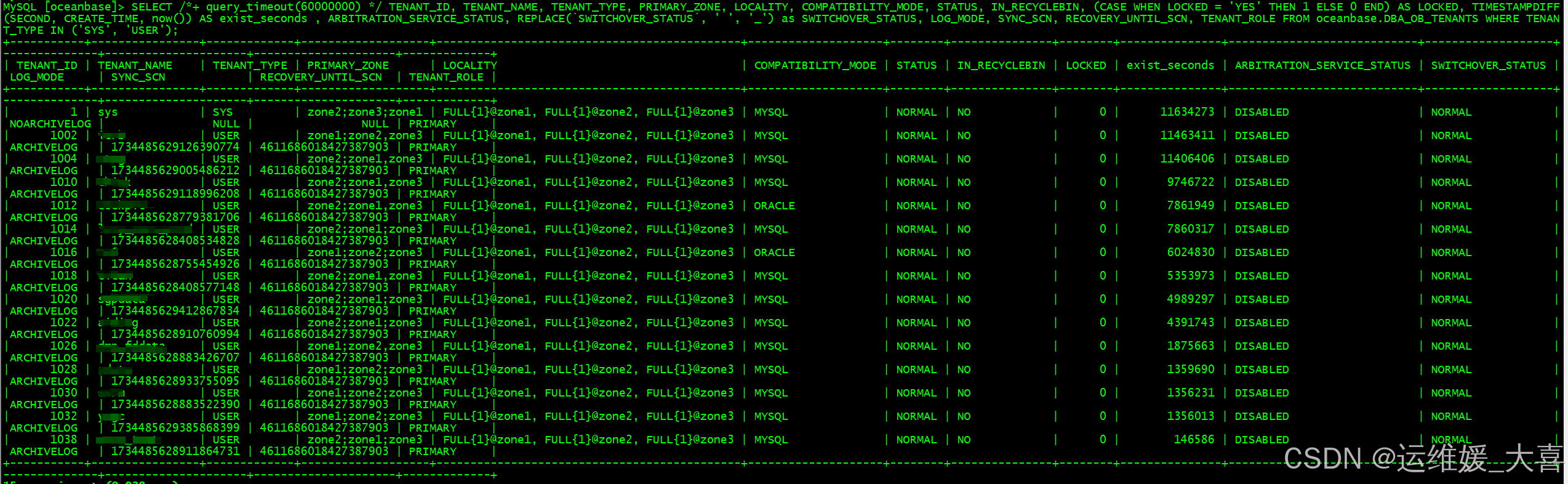
检查sys租户的状态:

在进行DDL验证,均正常。至此本次故障恢复完成。
复盘结论:
sys租户在执行sql时报错-4013,但看了sys租户的内存使用,都是正常的,不存在内存满的问题。然后通过日志发现这个sql是发到1017这个租户上执行的,这个meta租户返回了-4013。通过日志看内存模块,使用最大的模块是CO_STACK。这个模块使用大的原因是stack_size由默认的512KB改成了1MB。因为meta租户是跟业务租户的内存相关的,所有后续把所有小内存租户的内存规格调大恢复正常。
复盘改进:
- 当前集群stack_size值为1MB,这种情况下,建议所有租户的的内存分配均大于10G。
- 租户规划上,原则上一个业务域一个租户。租户划分需要合理规划。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









