






背景:
工作日下午16:00左右,突然OceanBase保障群里,消息响个不停,陆陆续续有人反馈,连不上了。博主第一反应这么多人反馈有问题,是不是集群挂了?惴惴不安的检查了下observer进程是否正常,果然,进程挂了,这下悬着的心终于死了。开始马不停蹄的故障应急。
故障应急:
- 检查observer进程是否还在。正常如下,是有observer进程的。反之当时故障,进去检查发现observer没了。

![]()
- 检查到observer进程不存在后,第一时间进行了observer的拉起。在oceanbase目录下执行全路径的/home/admin/oceanbase/bin/observer即可,或者执行./bin/observer也可完成拉起。
- 拉起命令发起后,发现迟迟不能成功。后检查/data/1磁盘分区已满,导致observer拉起失败。快速mv了此目录下无关文件(根因分析将对此文件进行进一步说明),再次进行observer拉起。集群中的大多数节点成功拉起,集群恢复,可对外正常提供服务。
根因定位:
- 事后复盘,通过observer log查询crash的上下文。发现如下:

- 找到crash 时的trace_id。注意此trace_id的值是原始值,细心的网友已经发现,这个值的格式和我们常见的trace_id值格式并不一样。实际他是经历了一次转化。转化规则见下:

- 拿到具体trace_id后,就可以查看trace_id到底对应的是做什么,从而引发的异常了。本来至此,就已经马上揭晓真相了。但是,select * from gv$sql_audit where trace_id='YB420A413EC2-00061FA509A80C04'\G 查看时,发现该trace_id的内容已经被刷没了。
- 于是找到crash时,/data/1下面的coredump文件进行进一步分析。这也就是上面提到的启动observer进程时的无关文件。正常来说不会coredump,一般时触发特定异常时,才会coredump,本次集群crash正是由于异常引发一直coredump,coredump使得/data/1空间被打满,从而引发了集群crash。可使用gdb对coredump进行分析。
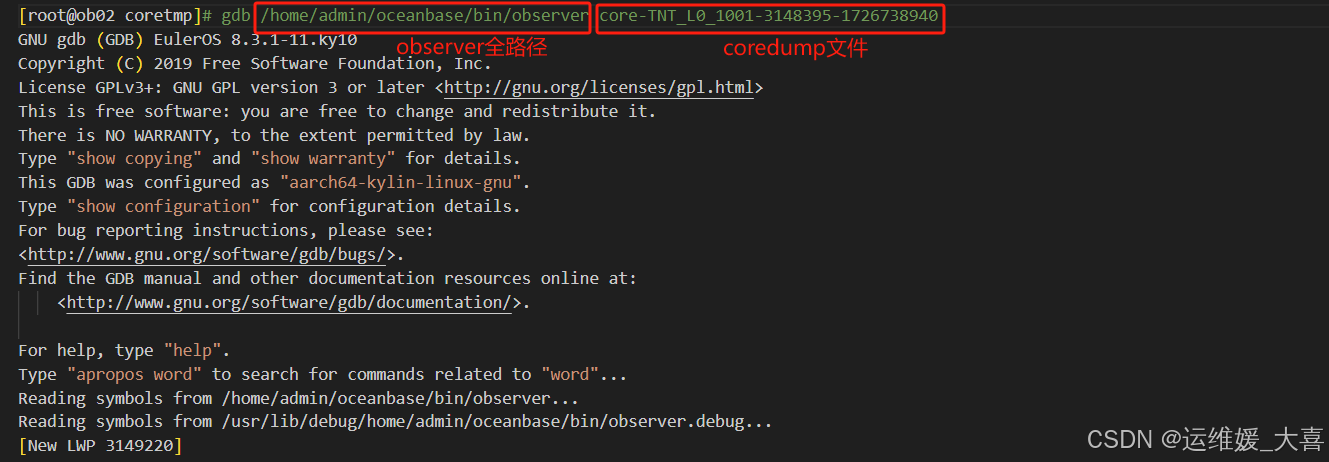
交互界面后,设置如下:
set logging file /home/admin/oceanbase/gdb-output
set logging on
set pagination off
set print pretty on
set print elements 0
bt
bt full
info r
info thread
set logging off
quit

返回的output如下
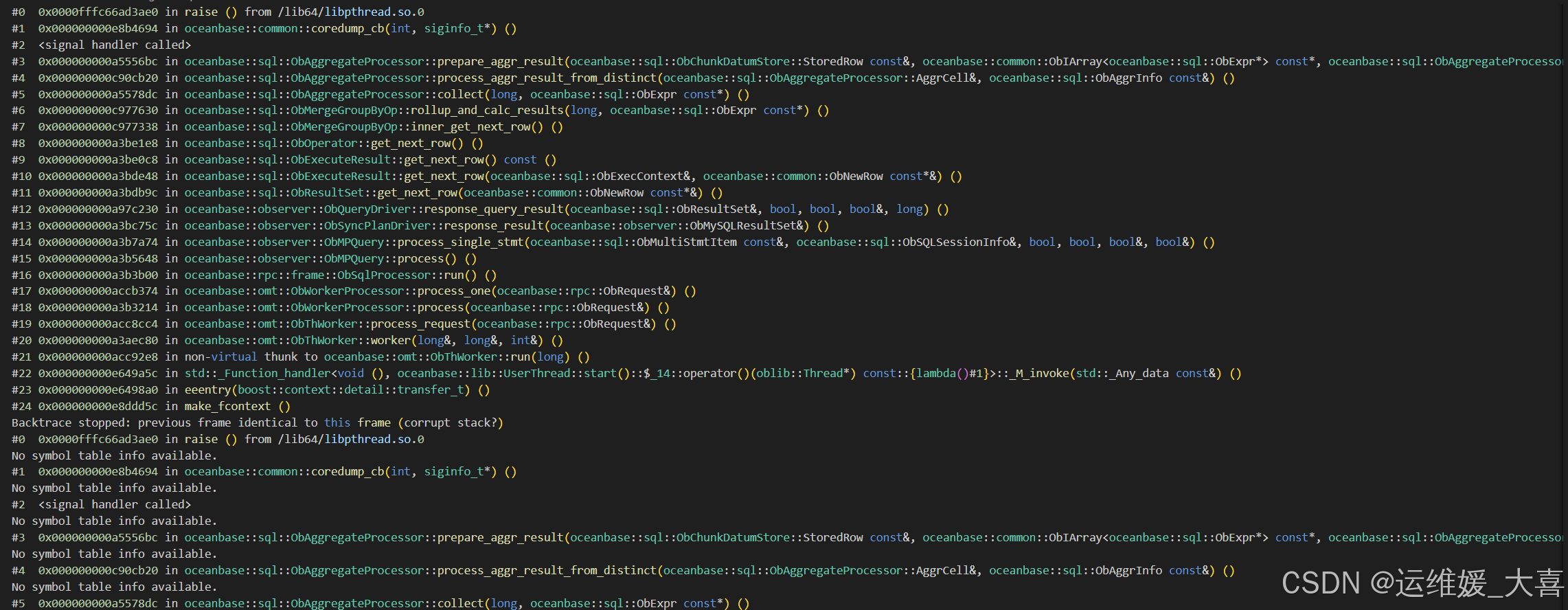
在output中找到了对应的crash时的query sql:
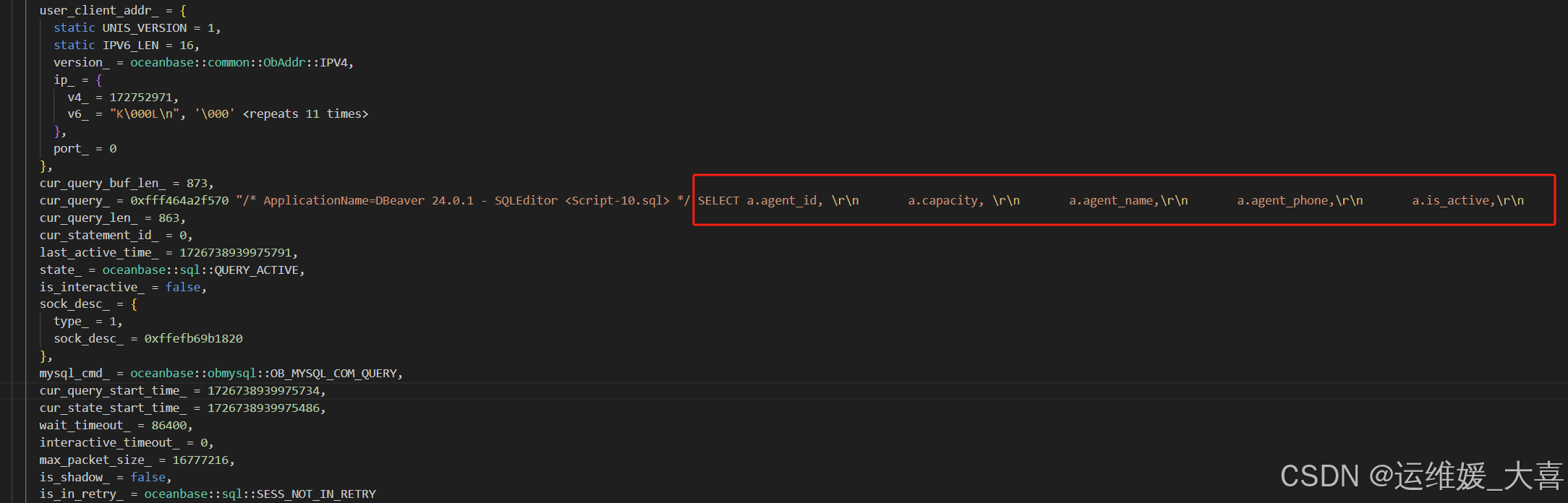
具体SQL见下:

经厂商确认,此为当前版本OB3.2.3.1 bp5 bug,JSON_ARRAYAGG和DISTINCT同时使用导致触发此BUG。疯狂coredump,在后续的版本中已经修复,后续版本再遇到类似sql,会直接进行报错。后续不再支持JSON_ARRAYAGG。
优化措施:
- 可新添加监控指标,识别是否有coredump产生,正常情况下不会产生coredump,如有coredump产生,则应立即关注,提早介入。
- Trace_id的转化,是本次新get到的技能,添加到了自研的oba(OceanBase黑屏运维工具)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









