







原文:https://arxiv.org/pdf/1802.00121v2.pdf
作者:Quanshi Zhang, Yu Yang, Haotian Ma, Ying Nian Wu
收录于CVPR 2019
摘要
以下几层:
文章学习一个决策树,它可以在语义层面上明确CNN每一次预测的具体原因。决策树告诉人们哪些部分激活了预测的过滤器,以及它们对预测分数的贡献有多大。
我们的方法挖掘了CNN的所有潜在决策模式,其中每个模式代表了CNN如何使用对象部分进行预测的常见情况。
决策树以一种从粗到细的方式组织所有潜在的决策模式,以解释CNN在不同细粒度级别上的预测。
引文
常规的解释性介绍,本文围绕两个观点:
- 如何在语义层次上解释CNN中间层的特征。
- 如何定量分析每一个CNN预测的基本原理。
大概内容两部分:
- 给中层特征分配语义。
- 计算中层特征对最后预测得分的影响。
决策树构建:
用过滤器来学习表示对象的某部分(无监督)把特定部分的名称分配每给每个过滤器。最后,我们挖掘决策模式来解释CNN如何使用部件/过滤器进行预测,并构造决策树。
相关工作
与决策树相关工作的不同点:
首先,我们关注使用树在语义上解释每一个预训练好的CNN的预测。而上述研究中的决策树主要是为了分类而学习的,无法提供语义层面的解释。其次,我们从梯度上总结出与目标部分神经激活相关的决策模式,作为解释CNN预测的依据。与上述“基于提取”的方法相比,我们的“基于梯度的”决策树更直接、更严格地反映了CNN的预测。
特定图像CNN预测基本原理
滤波损失(filter loss):特征图与原图部分之间的负交互信息。
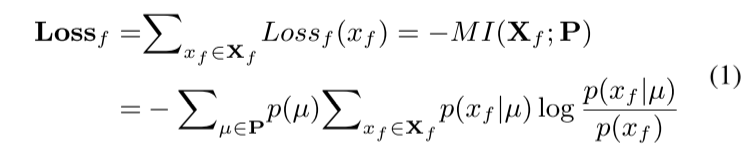
理解为,计算这张特征图对原图中某个部分的敏感程度,比如鸟头、鸟翅膀,如果出现了,则在出现的位置出现峰值,否则不激活。
CNN预测的定量原理
写的很多,简化出来就是下面这张图:
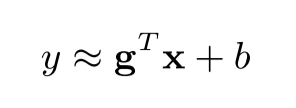
y是softmax层前的分类得分,x代表特特征图上某个部分的位置,g是y对x的导数(梯度),可以用来定量表示这个部分对得分的重要性。
这个部分介绍如何计算图上四个参数,有个细节是,具体计算使用了近似方法求x,g:

学习决策树
首先定义决策树中的基本概念,然后介绍学习算法。
下图为决策树的学习过程。

学到的决策树长这样,每个节点表示一个隐藏在CNN FC层中的决策模式:

结合第一张图的公式和决策树的构造过程,就得到了本文的模型:

模型的学习过程

初始化的树Q:所有gi模式下预测的“正向图”为叶子节点。
然后合并两个叶子节点,增加一种判断模式u。
依此类推构造该模式的决策树。
公式化就是:

解释CNN
如何解释决策树呢。
在推理过程中,我们可以以自顶向下的方式从根节点开始推断解析树。图4中的绿线显示了一个解析树。当我们选择节点u中的决策模式作为基本原理时,我们可以进一步选择其子v,将其与最具体的基本原理gi的兼容性最大化,作为更细粒度的模式。
量化计算不同模式对得分结果的贡献:
 实验
实验

能够很好的将预测结果按照模式归类,从而解释CNN的决策过程。从图像可看出,同一层的图片非常相似。
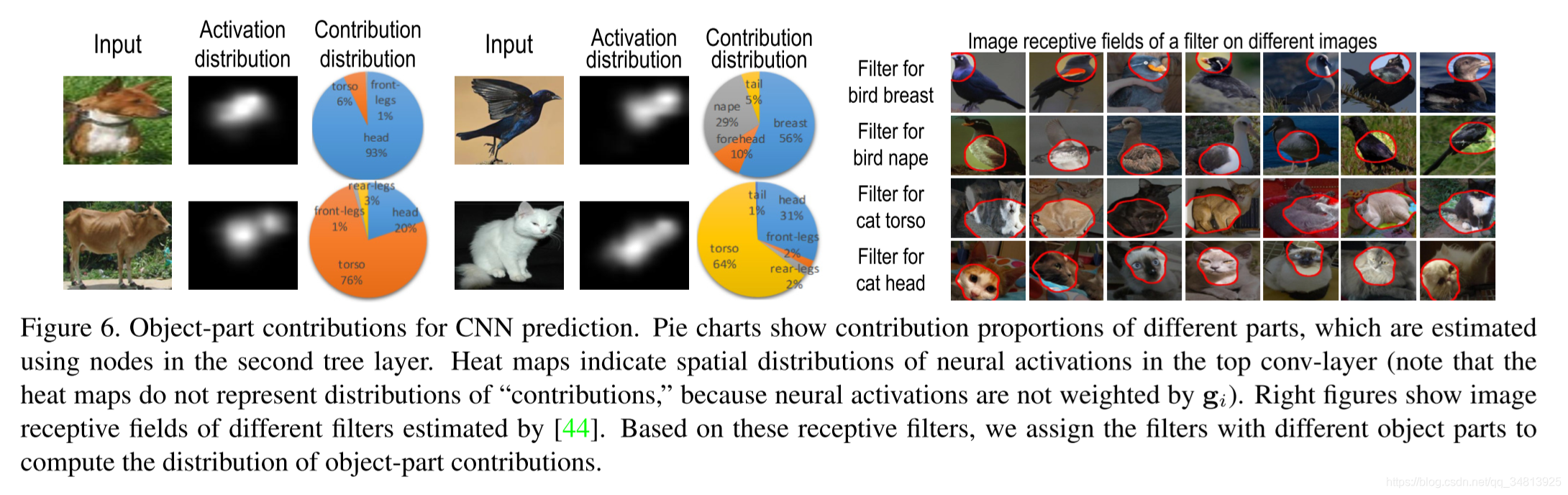
实验定量分析不同部分的贡献程度。
评价方法:第一个指标评估图像的部分对CNN预测的贡献的误差,这些误差是用树中第二层中的节点估计的。具体计算就是CNN原来的预测输出-特征图上除去第i个部分的激活信息后的输出。
第二个指标,贡献分布的适配程度,比较特征图间真实的贡献分布和估计的贡献分布。意思就是,评价某个模式分配到某个特征图上是否合适。
除了理论基础的准确性之外,我们还测量了使用决策树来表示CNN信息的损失作为补充的评估。一个度量是分类精度,就是测量决策树的分类结果的准确性。具体是比较树的叶子节点和原CNN的预测结果。
从表格可以看出决策树解释的分类结果和CNN预测的基本一致,说明论文方法解释CNN的效果较好。
总结
在这项研究中,我们使用一个决策树来解释CNN在语义层面上的预测。我们研究了一种对CNN进行修正的方法,并将其与决策树紧密耦合。该决策树将CNN的决策模式编码为每个预测的定量依据。我们的方法不需要对训练图像中的物体部分或纹理进行任何标注来指导CNN的学习。我们已经在不同的基准数据集上测试了我们的方法,实验证明了我们的方法的有效性。请注意,从理论上讲,决策树只是为CNN预测提供了一个近似的解释,而不是对CNN表示细节的精确重构。有两个原因。首先,没有精确的对象-部分标注来监督CNNs的学习,滤波损失只能粗略地使每个滤波代表一个对象零件。该过滤器可能产生不正确的激活在一些具有挑战性的图像。其次,每个节点的决策模式忽略不重要的对象部分过滤器,以保证决策模式的稀疏表示。

















 2393
2393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









