







- 目标网站:https://s.weibo.com/top/summary?cate=realtimehot 微博实时热搜榜
- 分析url结构
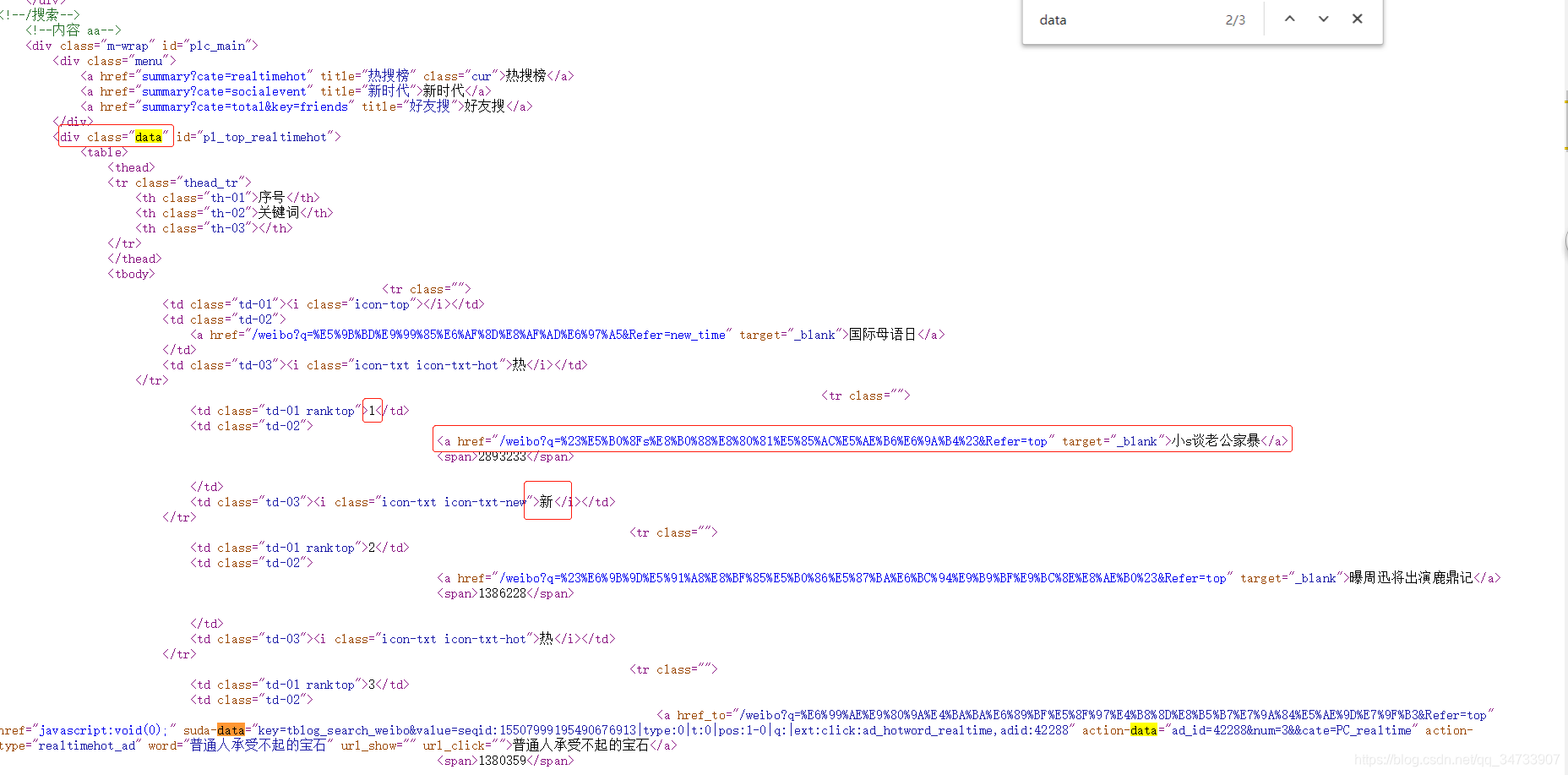
热搜榜上的每个话题在<div class = 'data'>且只存在一个class值为data的div块
爬取范围确定。
生成网站模板文件
在此我们直接使用上次创建的虚拟环境articalspider和项目ArticleSpider
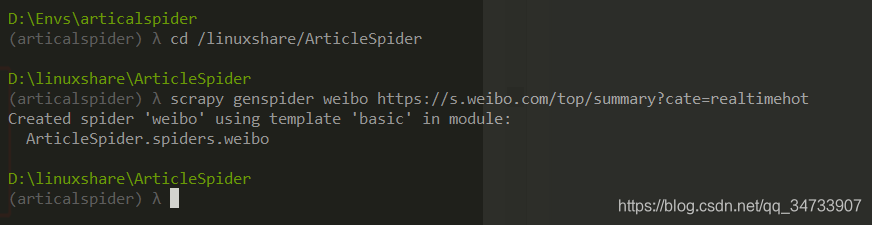
项目中就会直接出现weibo的爬虫文件
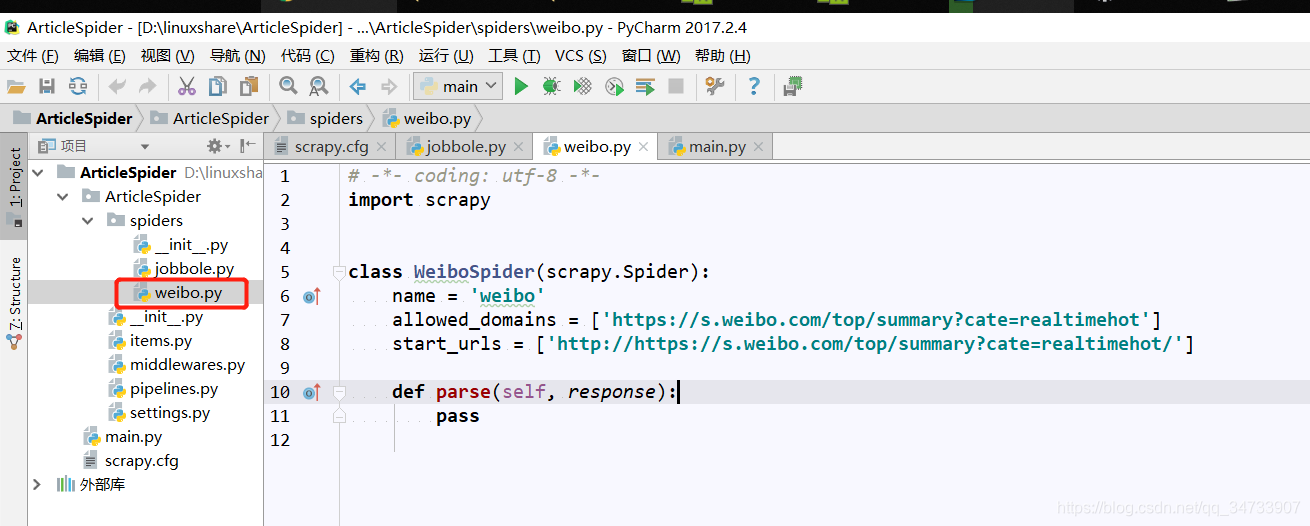
调试一下,看爬虫文件是否能正常获取html全文
在此出现了如下错误 :
Connected to pydev debugger (build 172.4343.24)
2019-02-22 10:26:18 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: ArticleSpider)
2019-02-22 10:26:18 [scrapy.utils.log] INFO: Versions: lxml 4.3.1.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.20.0, Twisted 18.9.0, Python 3.6.0 (v3.6.0:41df79263a11, Dec 23 2016, 07:18:10) [MSC v.1900 32 bit (Intel)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1a 20 Nov 2018), cryptography 2.5, Platform Windows-10-10.0.17134-SP0
2019-02-22 10:26:18 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'ArticleSpider', 'NEWSPIDER_MODULE': 'ArticleSpider.spiders', 'SPIDER_MODULES': ['ArticleSpider.spiders']}
2019-02-22 10:26:18 [scrapy.extensions.telnet] INFO: Telnet Password: 164c5a9047f9b8a7
2019-02-22 10:26:18 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2019-02-22 10:26:18 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-02-22 10:26:18 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-02-22 10:26:18 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2019-02-22 10:26:18 [scrapy.core.engine] INFO: Spider opened
2019-02-22 10:26:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-02-22 10:26:18 [py.warnings] WARNING: D:\Envs\articalspider\lib\site-packages\scrapy\spidermiddlewares\offsite.py:61: URLWarning: allowed_domains accepts only domains, not URLs. Ignoring URL entry https://s.weibo.com/top/summary?cate=realtimehot in allowed_domains.
warnings.warn(message, URLWarning)
2019-02-22 10:26:18 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
参考 https://blog.youkuaiyun.com/xudailong_blog/article/details/79432155
发现自动生成的爬虫文件weibo.py中
start_urls = ['http://https://s.weibo.com/top/summary?cate=realtimehot/']
多出来一个http://,更改值为正确的url即可下面通过xpath提取出我们所需要的值
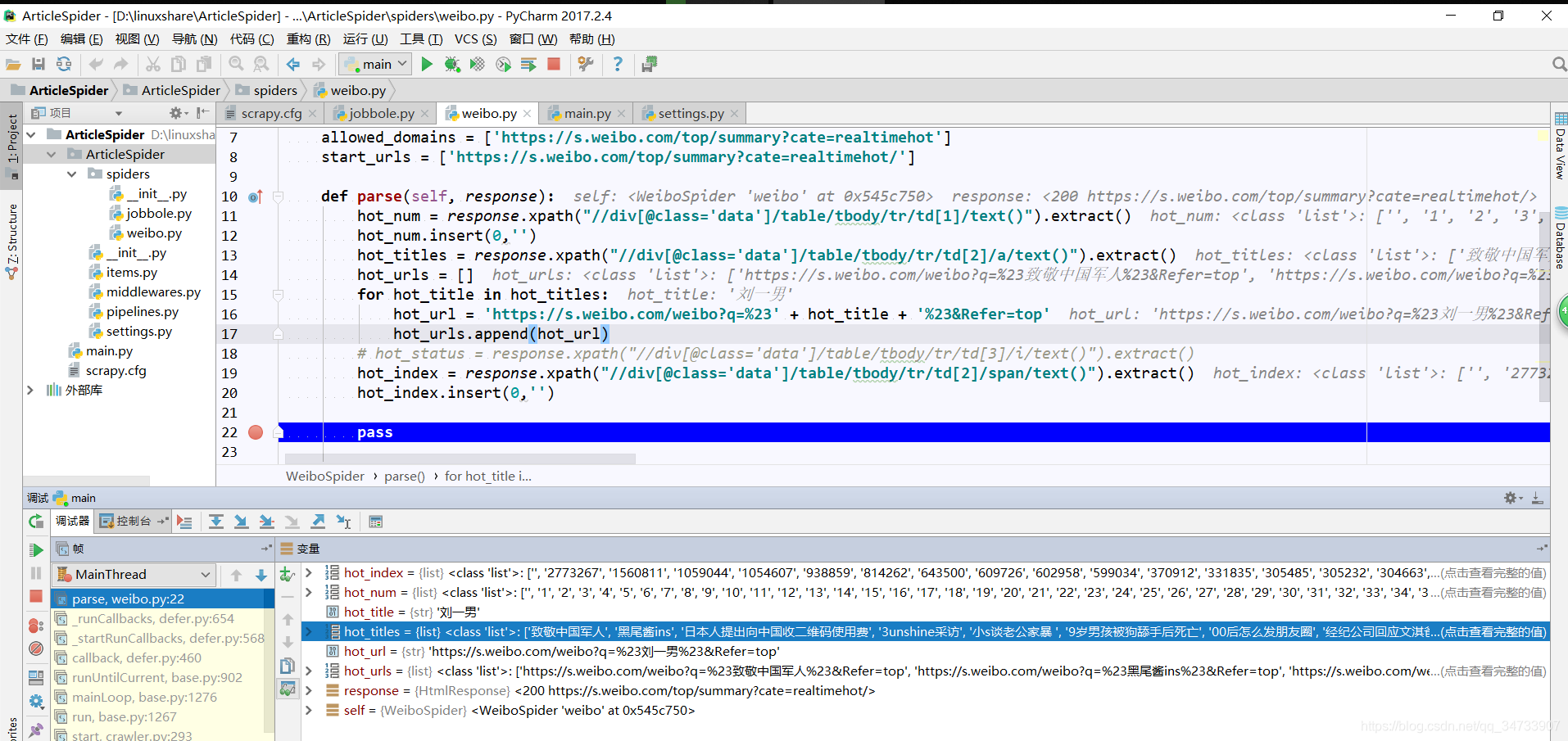
hot_num : 热搜话题序号
hot_title : 热搜话题名称
hot_urls : 热搜话题url
hot_status : 热搜话题状态 #不是每个话题都有状态,暂时还没找到解决方法,先不爬取了
hot_index : 热搜话题热度指数
在shell中调试 : 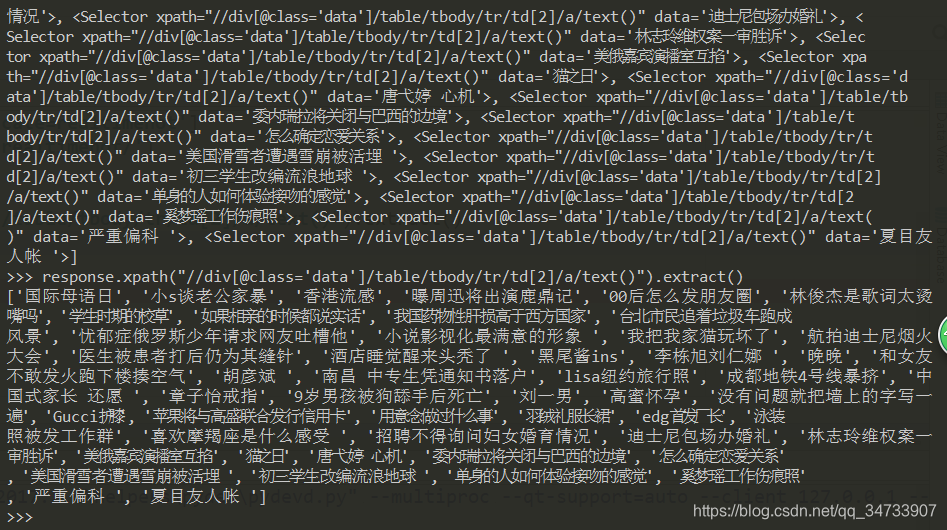


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









