







为啥不使用均方误差损失函数?
主要原因是在分类问题中,使用sigmoid/softmx得到概率,配合MSE损失函数时,采用梯度下降法进行学习时,会出现模型一开始训练时,学习速率非常慢的情况
交叉熵函数是凸函数,求导时能够得到全局最优值。
信息量: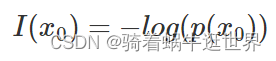
熵: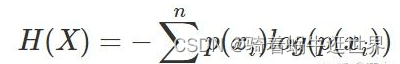
相对熵: 又称KL散度(Kullback-Leibler (KL) divergence),用于衡量对于同一个随机变量x的两个单独的概率分布P(x)和Q(x)之间的差异。
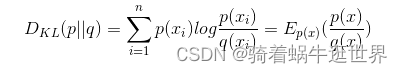
相对熵不具有对称性、不具有负数性
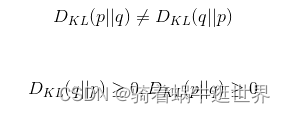
将上面相对熵KL散度修改格式如下:KL散度 = 信息熵 - 交叉熵
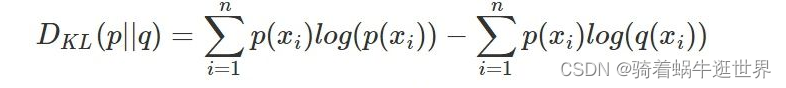


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









