







 本文深入探讨了MySQL的几种存储引擎,包括MyISAM、Memory和CSV的特点及应用场景,并详细阐述了BTree索引和Hash索引的工作原理。此外,还分析了索引的优缺点、优化策略以及如何检查和删除冗余索引。
本文深入探讨了MySQL的几种存储引擎,包括MyISAM、Memory和CSV的特点及应用场景,并详细阐述了BTree索引和Hash索引的工作原理。此外,还分析了索引的优缺点、优化策略以及如何检查和删除冗余索引。
MyISAM存储引擎
MyISAM特点
1)不支持事务
2)支持全文检索,支持text支持前缀索引
3)支持数据压缩
4)紧密存储,顺序读性能很好
5)表级锁,混合读写性能不佳,并发性差
MyISAM应用场景
1)非事务应用,例如:保存日志
2)只读类应用,报表数据,字典数据
3)空间类应用,开发GIS系统(5.7版本以前,5.7以后InnoDB也支持)
4)系统临时表,SQL查询,分组的临时表引擎

Memory存储引擎
Memory特点
1)不支持事务
2)内存读写,临时存储
3)超高的读写效率,比MyISAM高一个量级
4)表级锁,并发性差
Memory应用场景
1)读多写少的静态数据,例如省市县的对应表
2)充当缓存使用,保存高频访问静态数据
3)系统临时表
Memory关键参数
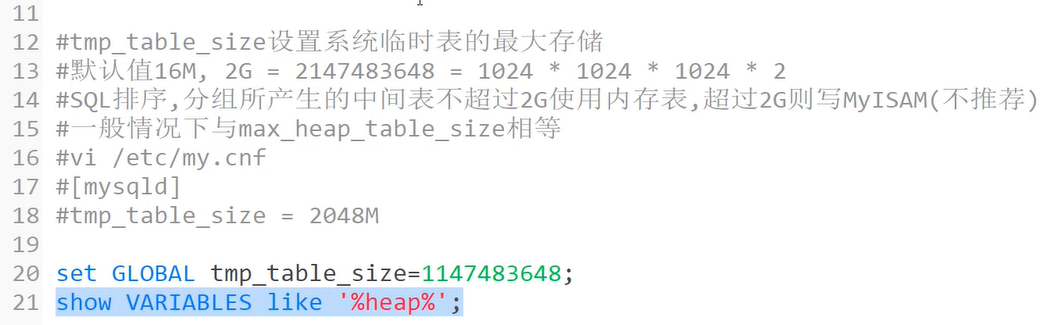
1)设置max_heap_table_size控制内存表大小(字节)
2)设置tmp_table_size内存临时表最大值(字节)

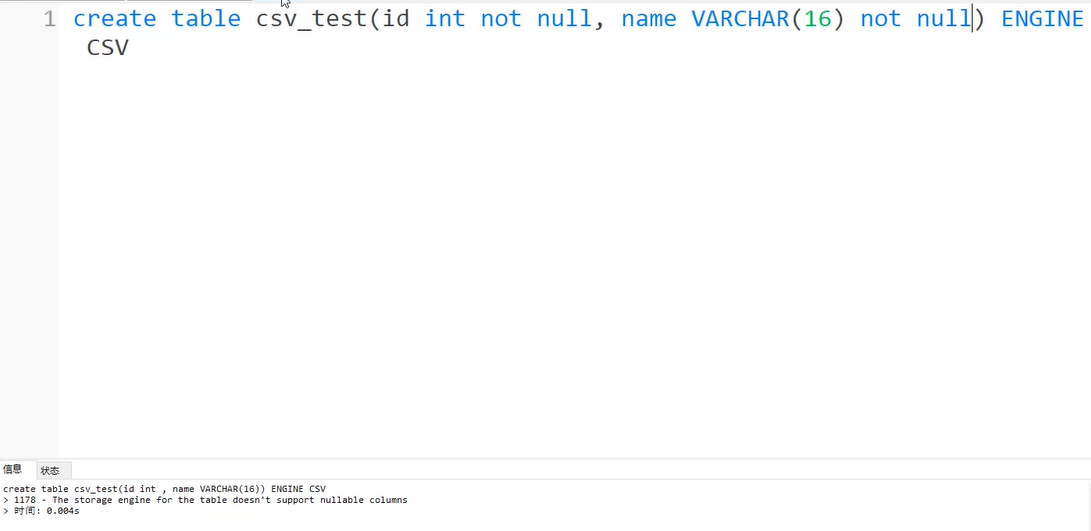
CSV存储引擎
CSV特点
1)纯文本保存
2)不支持事务
3)不支持索引
CSV应用场景
1)数据交换/数据迁移

2)不依赖MySQL环境


BTree索引原理介绍
B+Tree索引
数据表索引的目的
1)索引就是为表建立的“目录”
2)索引的目的就是防止全表扫描
3)索引的存储形式是由存储引擎决定
数据表索引分类
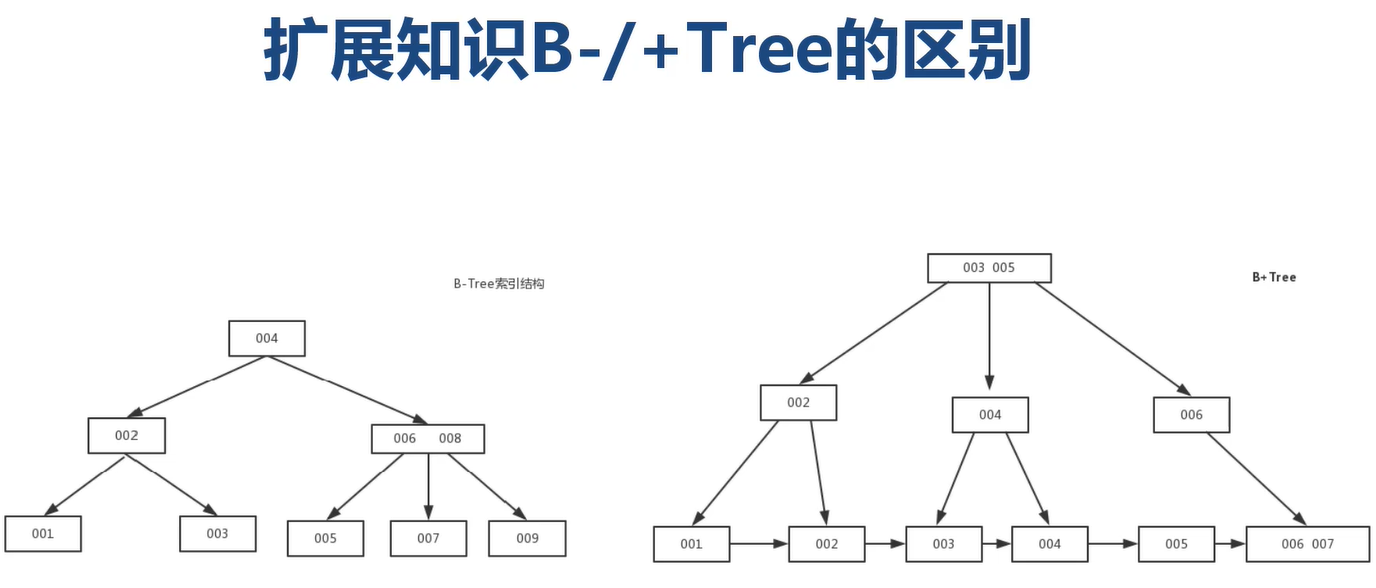
1)从存储结构上来划分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引
2)从应用层次来划分:普通索引,唯一索引,复合索引
3)根据中数据的无物理顺序与键值的逻辑(索引)顺序关系:聚集索引,非聚集索引
MySQL常用的索引
1)B+Tree索引 —— 适用于范围查找
2)Hash索引 —— 适用于精确匹配
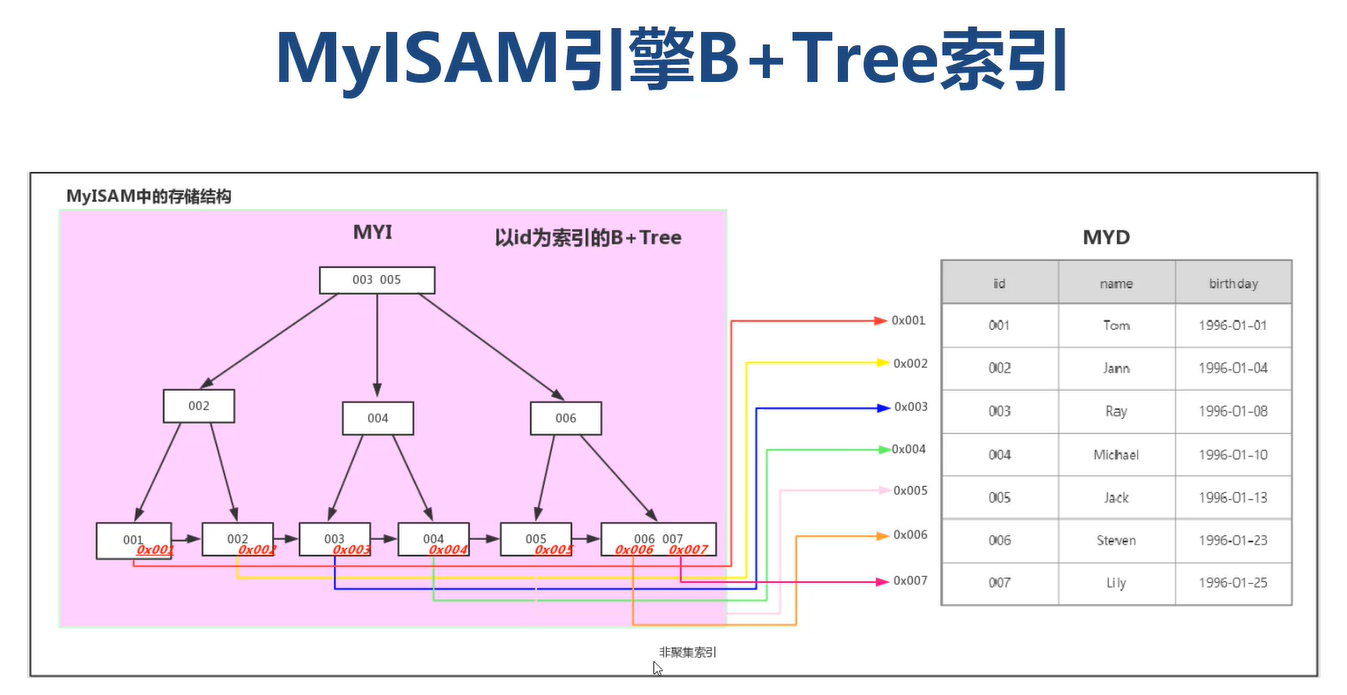
B+Tree索引
1)MySQL中InnoDB与MyISAM采用的是B+Tree索引
2)B+Tree索引采用树形链表结构建立数据“目录”
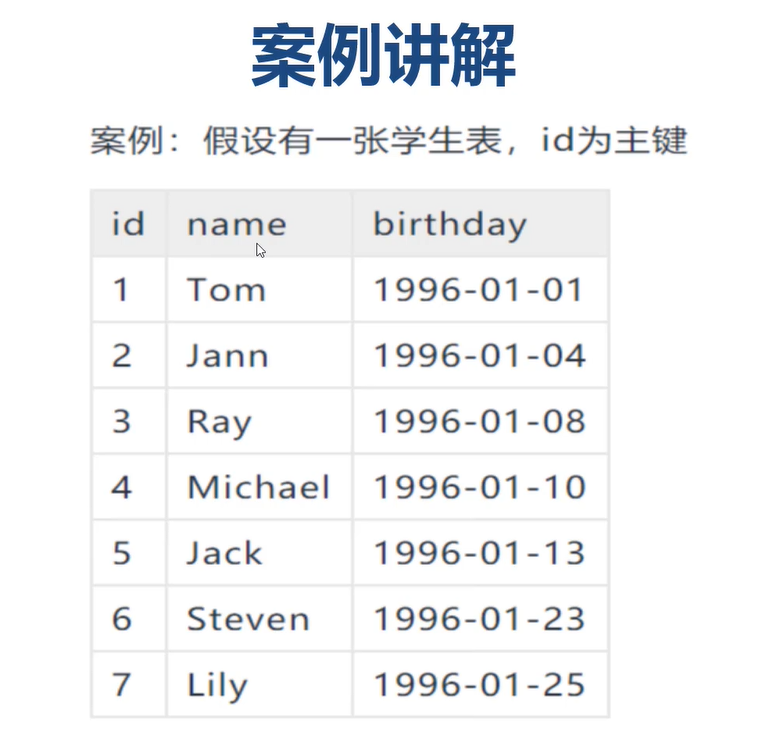
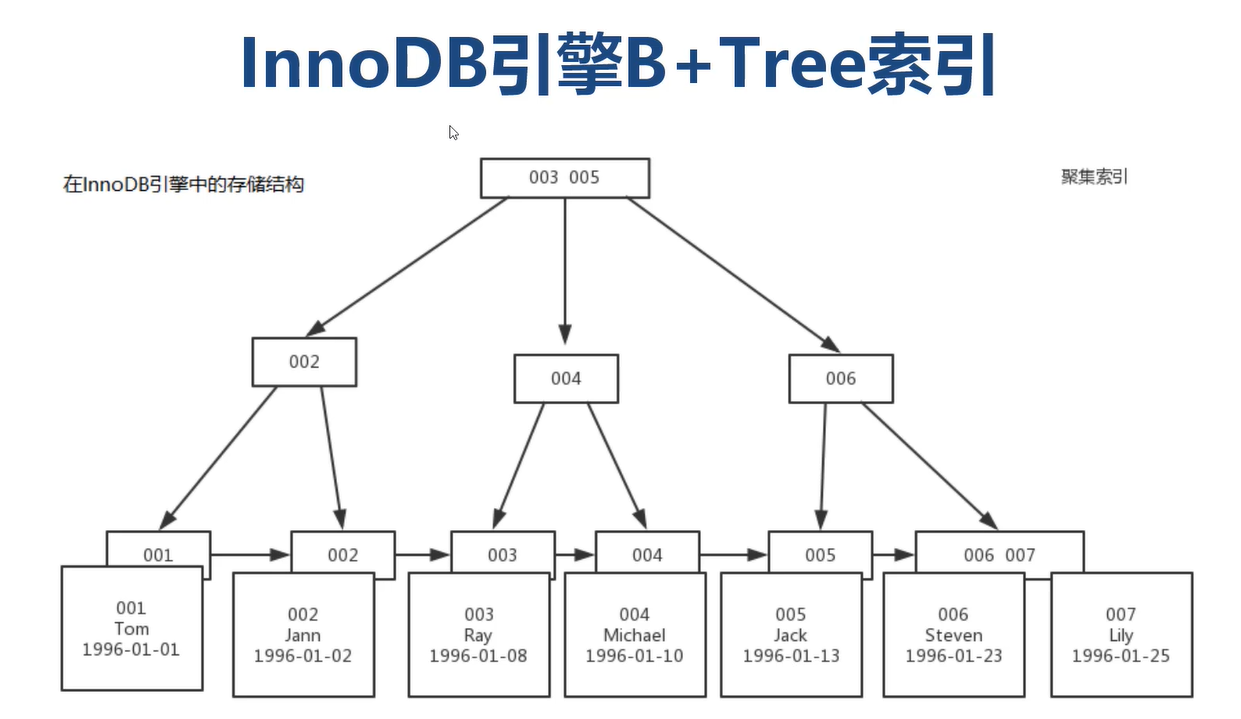
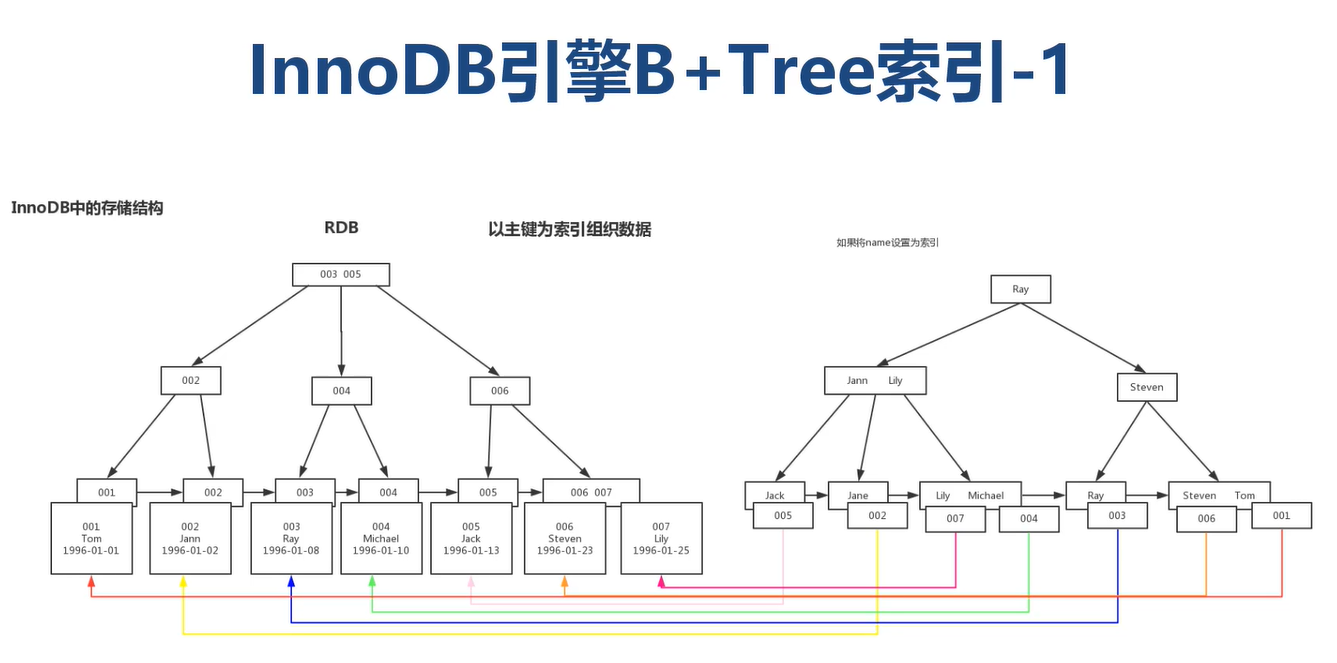
为什么官方建议使用自增长主键作为索引
自增长主键:默认新增长的数据是最大的,影响的范围是最小的
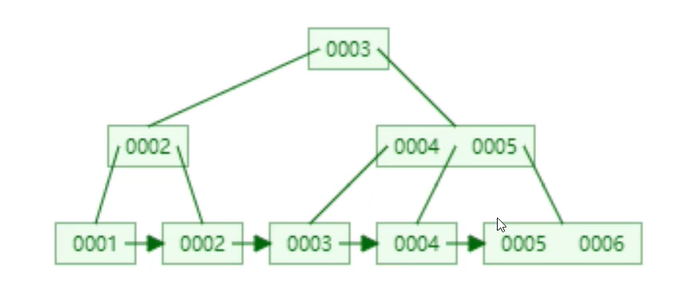
非自增长主键:每次数据新增,索引都要进行全局的重算
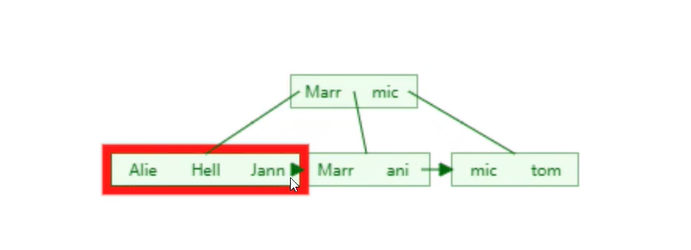
Hash索引介绍
Hash索引
1)Hash索引(hash index)基于哈希表实现
2)精确匹配索引所有列的查询才有效
3)Hash索引为每条数据生成一个HashCode

Hash索引的特点
1)Hash索引只包含哈希值和行指针
2)只支持精确匹配,不支持范围查询、模糊查询及排序
3)Hash取值速度非常快,但索引选择性很低时不建议使用
4)MySQL目前只有Memory显示支持Hash索引
InnoDB中的Hash索引
1)InnoDB存储引擎只支持显示创建BTree索引
2)数据精确匹配时MySQL会自动生成HashCode,存入缓存
索引的优点
1)索引大幅提升了数据的检索效率
2)索引把随机IO,变成了顺序IO
索引是不是越多越好
1)降低了写入数据的效率
2)太多的索引增加了查询优化器的选择时间
3)不合理的使用索引,会大幅占用磁盘空间
索引的优化策略
1)索引选择性太差
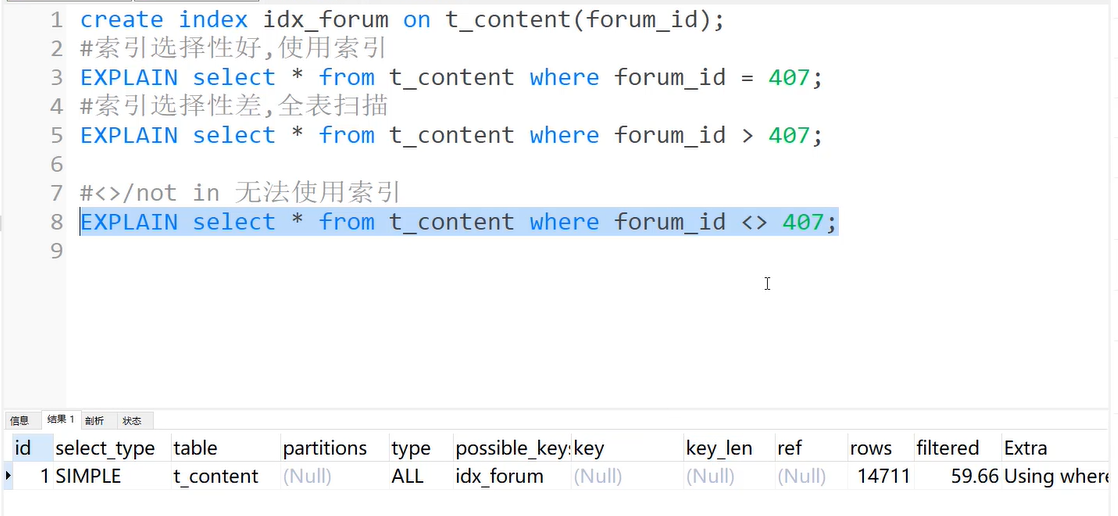
2)<>/not in无法使用索引
3)is null会使用索引,is not null 不会使用索引
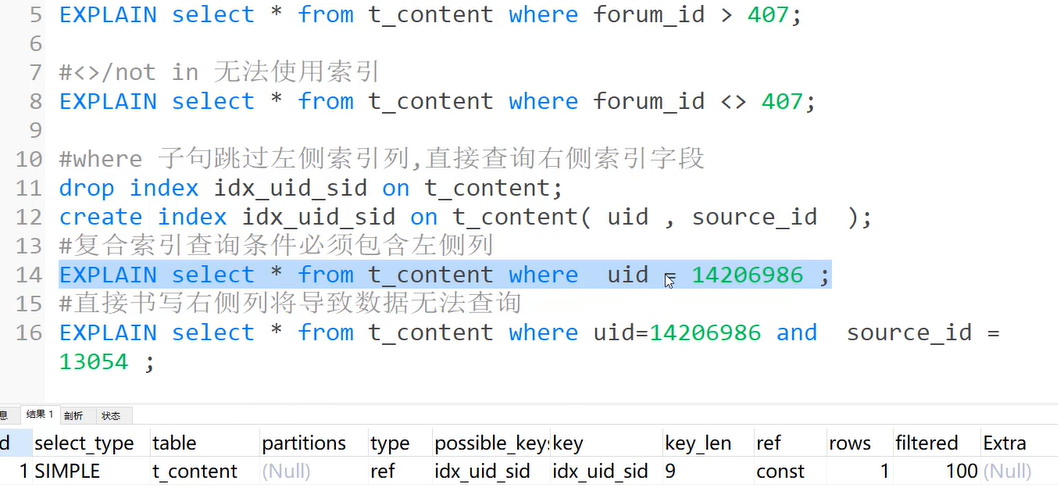
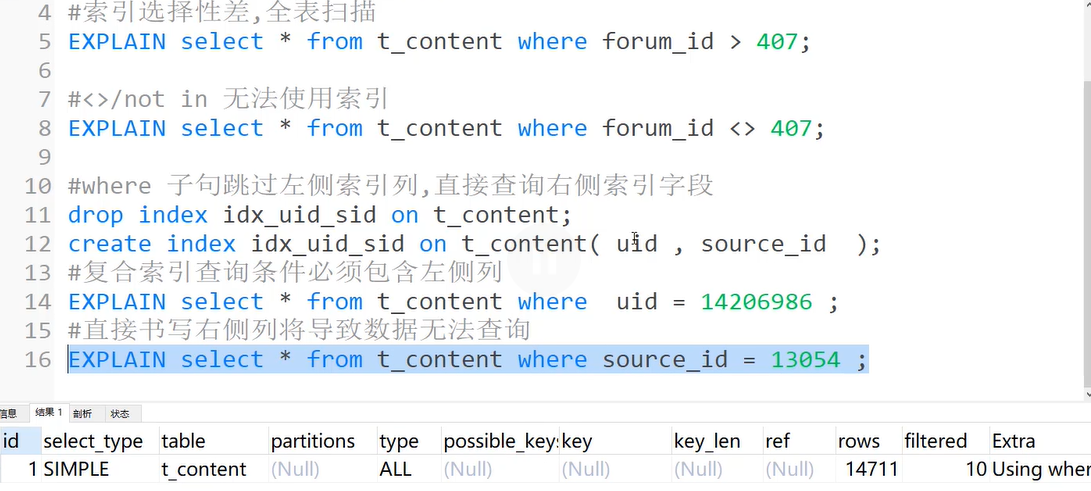
4)where子句跳过左侧索引列,直接查询右侧索引字段
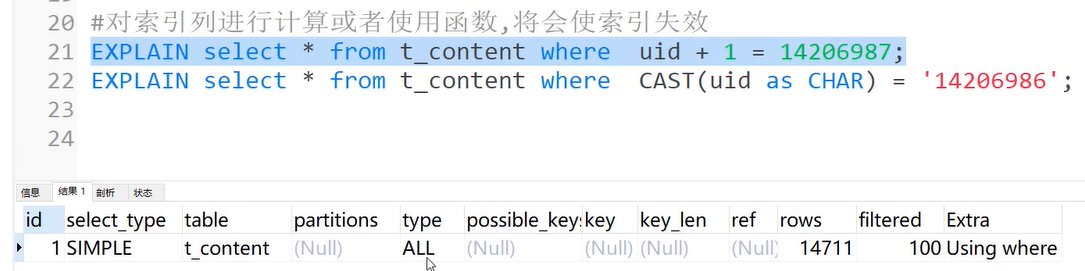
5)对索引列进行计算或者使用函数
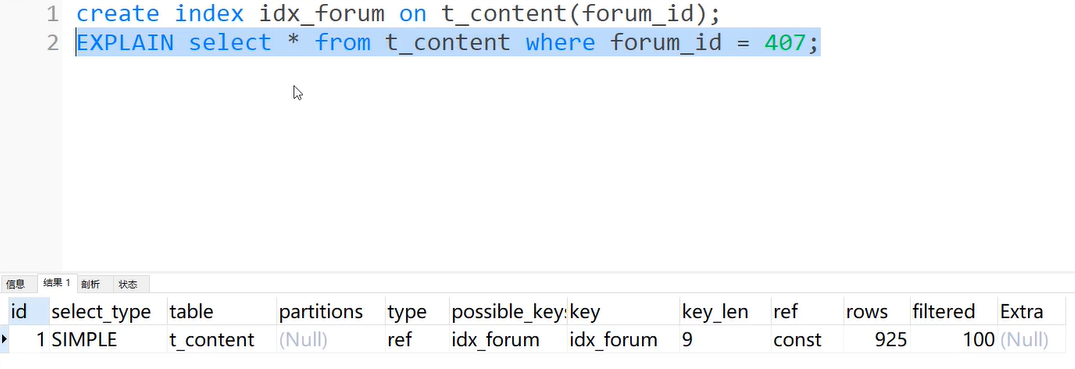
索引选择性好,使用索引
索引选择性差,全表扫描
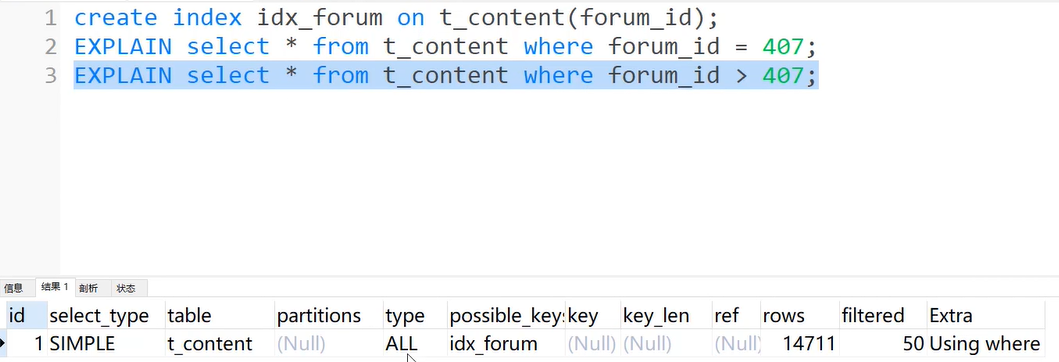
<>/not in 无法使用索引
复合索引查询条件必须包含左侧列
直接书写右侧列将导致无法使用索引
对索引列进行计算或者使用函数,将会使使用失效
注意:Oracle可以对整个函数进行索引创建,MySQL不支持
使用索引优化排序
当order by字段与索引字段顺序/排序方向相同时索引可优化排序速度
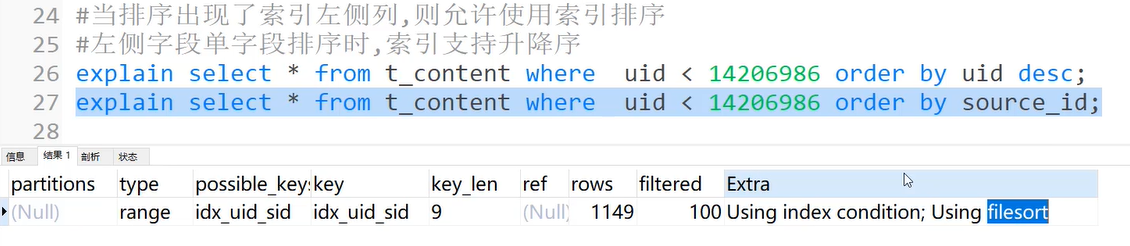
当排序出现了索引左侧列,则允许使用索引排序
左侧字段单字段排序时,索引支持升降序

Using filesort,会进行读取文件的重新排列
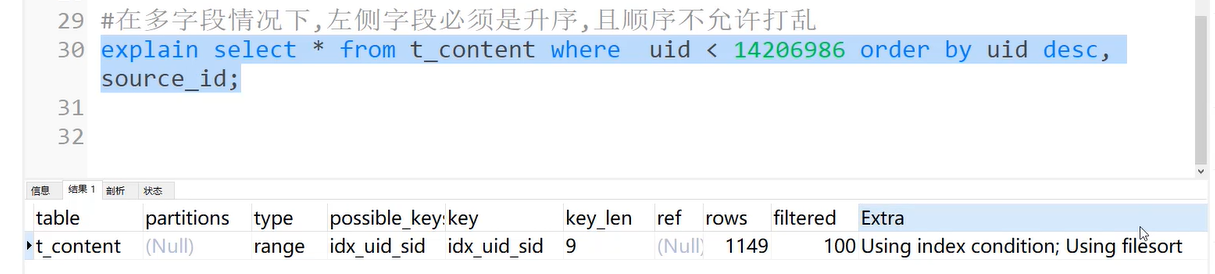
在多字段情况下,左侧字段必须是升序,且顺序不允许打乱

左侧降序,执行效率差
顺序打乱,执行效率差

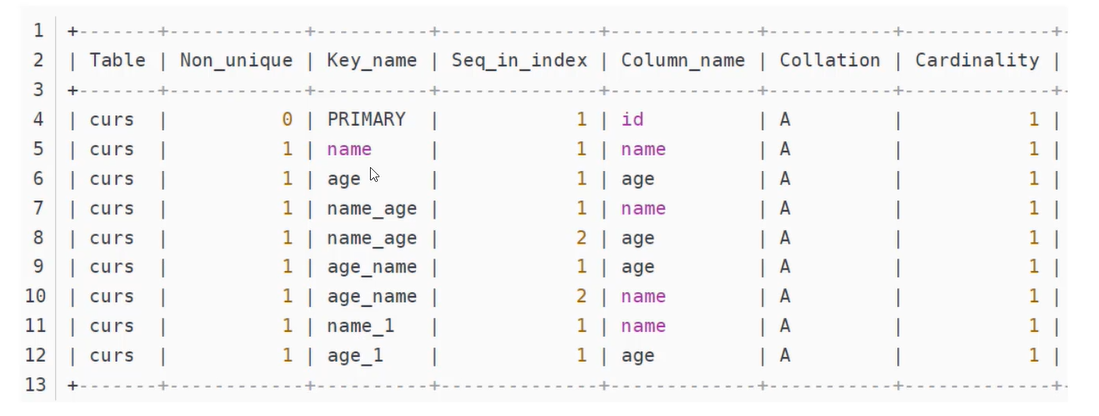
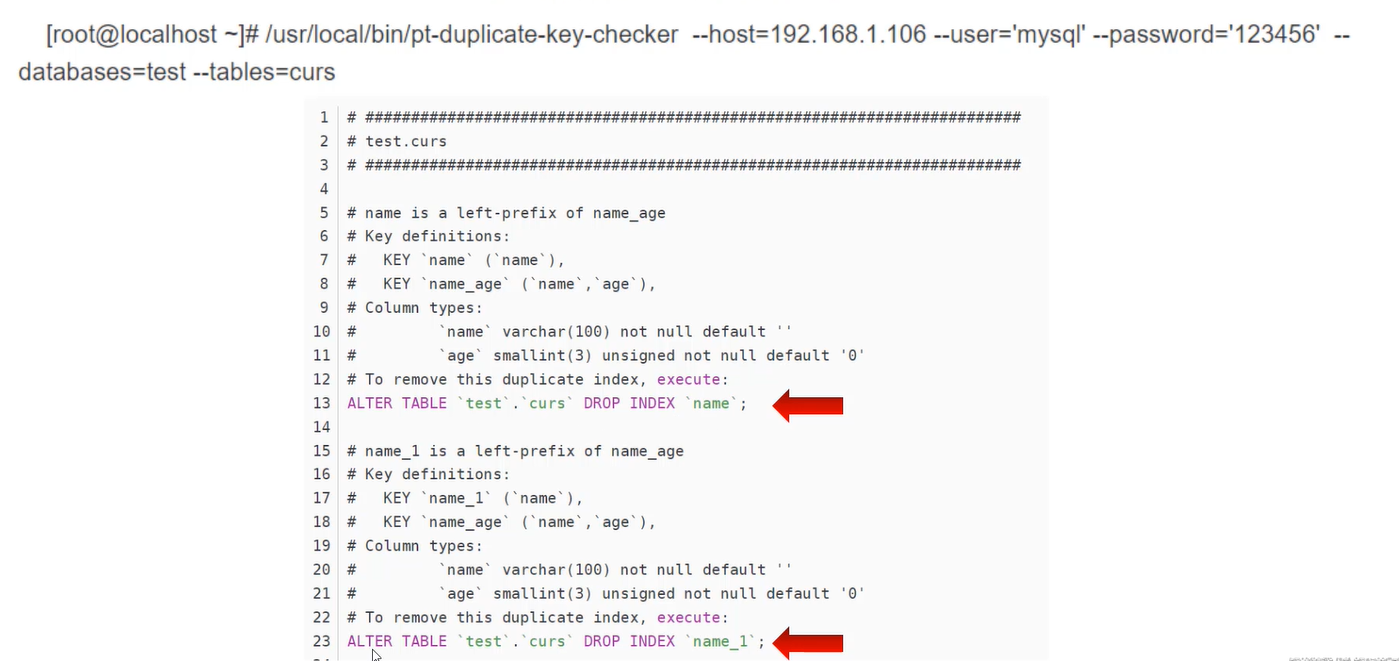
删除冗余索引
1)pt-duplicate-key-checker是percona-toolkit工具包中的实用组件
2)它可以帮助你检测表中重复的索引或者主键
实用索引SQL语句
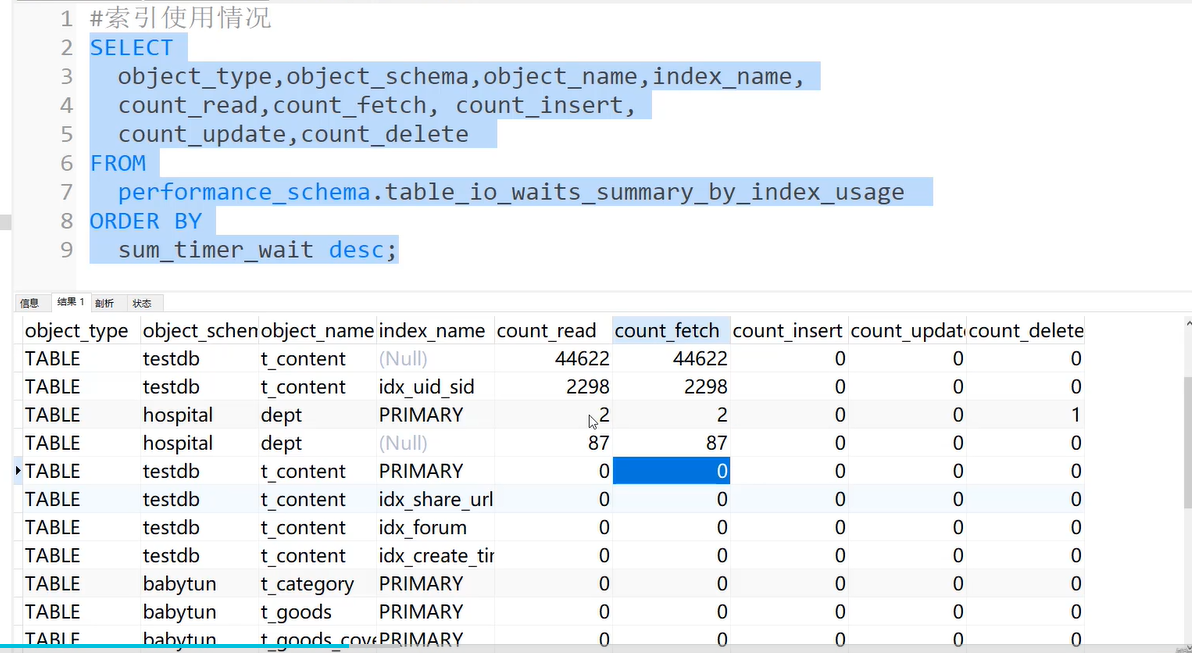
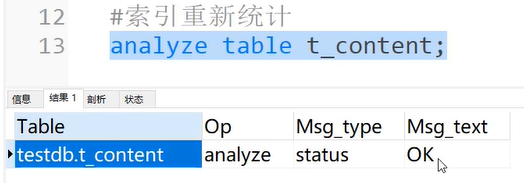
减少表与索引碎片
1)analyze table 表名;
2)optimize table 表名;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









