







 GBDT+LR是一种融合梯度提升决策树和逻辑回归的机器学习方法,用于提高模型预测性能。首先,GBDT通过迭代训练决策树并纠正预测误差,然后使用GBDT生成的特征进行逻辑回归模型训练。这种组合方法在特征工程、稀疏特征处理和模型性能优化方面表现出优势,常应用于广告点击率预测、金融风险控制和推荐系统等领域。
GBDT+LR是一种融合梯度提升决策树和逻辑回归的机器学习方法,用于提高模型预测性能。首先,GBDT通过迭代训练决策树并纠正预测误差,然后使用GBDT生成的特征进行逻辑回归模型训练。这种组合方法在特征工程、稀疏特征处理和模型性能优化方面表现出优势,常应用于广告点击率预测、金融风险控制和推荐系统等领域。
GBDT+LR
GBDT+LR是一种融合梯度提升决策树(Gradient Boosting Decision Tree,简称GBDT)和逻辑回归(Logistic Regression,简称LR)的机器学习方法。这种方法的主要目的是充分利用GBDT和LR的优势,提高模型的预测性能。
GBDT(Gradient Boosting Decision Tree):
GBDT是一种基于梯度提升(Gradient Boosting)的集成学习方法。GBDT通过迭代训练多个决策树模型,并将它们组合在一起,形成一个强大的预测模型。在每一轮迭代中,GBDT会训练一个新的决策树,该决策树试图纠正前面已训练的决策树的预测误差。通过这种方式,GBDT能够不断提高模型的预测能力。
LR(Logistic Regression):
逻辑回归是一种广泛应用于分类问题的线性模型。LR通过使用对数几率函数(logistic function)将线性回归的输出映射到概率空间,从而得到属于某一类别的概率。然后,可以根据概率阈值对样本进行分类。
GBDT+LR的融合方法:
GBDT+LR方法的核心思想是先使用GBDT对原始特征进行特征转换,然后将转换后的特征输入到LR模型中进行分类。
具体步骤如下:
(1)使用GBDT训练模型:首先,使用GBDT对训练数据进行训练,得到多个决策树模型。
(2)特征转换:将训练数据通过GBDT模型,得到每个样本在每棵树上的叶子节点。这些叶子节点可以看作是原始特征的高阶组合。将叶子节点编码成一种称为“one-hot encoding”的形式。这样,每个样本就会被转换成一个高维稀疏向量,向量中的每个元素代表该样本在某个叶子节点上的取值。
(3)训练LR模型:使用转换后的特征作为输入,训练逻辑回归模型。由于特征已经经过了GBDT的处理,这个过程可以看作是在学习GBDT所捕捉到的特征组合之间的线性关系。
(4)预测:对于新的样本,首先将其通过GBDT进行特征转换,然后将转换后的特征输入到LR模型中,得到分类结果。
GBDT+LR的优势:
特征工程:GBDT可以自动学习到有效的特征组合,降低了手动进行特征工程的难度和工作量。
稀疏特征处理:经过GBDT特征转换后,特征变得稀疏且高维,逻辑回归对稀疏特征的处理能力较强,有助于提高模型性能。
优化模型性能:GBDT和LR的组合可以充分利用非线性和线性模型的优势,提高模型的预测性能。
应用场景:
GBDT+LR模型适用于各种分类问题,特别是在广告点击率预测、金融风险控制、推荐系统等领域有着广泛的应用。
总结:
GBDT+LR是一种结合了梯度提升决策树和逻辑回归的机器学习方法。通过使用GBDT进行特征转换和逻辑回归进行分类,该方法充分发挥了两者的优势,提高了模型的预测性能。GBDT+LR模型在各种分类问题中均有良好的表现,尤其适用于广告点击率预测、金融风险控制和推荐系统等
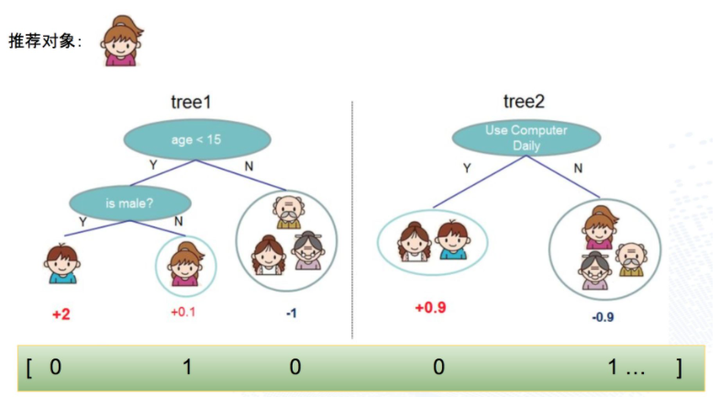
单独的使用GBDT模型,容易出现过拟合,在实际应用中往往使用 GBDT+LR的方式做模型训练
首先根据样本训练出GBDT树,对于每个叶子节点,回溯到根节点都可以得到一组组合特征,所以用叶子节点的标号可以代表一个新的组合特征。结合上面的图,用一个样本为例,直观的表达如下
编辑切换为居中
添加图片注释,不超过 140 字(可选)
其中 0号 组合特征的含义是:ageLessThan15AndIsMale,该样本取值 0
其中 1号 组合特征的含义是:ageLessThan15AndIsNotMale,该样本取值 1
其中 2号 组合特征的含义是:ageLargerOrEqualThan15,该样本取值 0
其中 3号 组合特征的含义是:useComputerDaily,该样本取值 0
其中 4号 组合特征的含义是:notUseComputerDaily,该样本取值 1
这部分特征是GBDT生成的组合特征,再结合LR固有的稀疏特征,就组成了 GBDT + LR 模型。
生成样本向量阶段,样本首先过GBDT模型,生成组合特征部分的输入向量,再结合固有的稀疏特征向量,组成新的特征向量,再以它训练LR,示例如下:

Sklearn
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
# 生成模拟数据的函数
def generate_data(n_samples=10000, n_features=10, random_state=None):
np.random.seed(random_state)
X = np.random.rand(n_samples, n_features)
y = (np.random.rand(n_samples) > 0.5).astype(int)
return pd.DataFrame(X, columns=[f'feature_{
i}' for i in range(n_features)]), y
# 生成模拟数据
X, y = generate_data(n_samples=10000, n_features=10, random_state=42)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练GBDT模型
gbdt = GradientBoostingClassifier(n_estimators=50, random_state=42)
gbdt.fit(X_train, y_train)
# 对训练数据进行GBDT特征变换
train_leaves = gbdt.apply(X_train)[:, :, 0]
test_leaves = gbdt.apply(X_test)[:, :, 0]
# 对GBDT生成的叶子节点特征进行One-Hot编码
encoder = OneHotEncoder()
encoder.fit(train_leaves)
train_leaves_encoded = encoder.transform(train_leaves)
test_leaves_encoded = encoder.transform(test_leaves)
# 训练LR模型
lr = LogisticRegression(solver='lbfgs', max_iter=1000, random_state=42)
lr.fit(train_leaves_encoded, y_train)
# 对测试集进行预测并计算AUC
y_pred = lr.predict_proba(test_leaves_encoded)[:, 1]
auc = roc_auc_score(y_test, y_pred)
print(f'Test AUC: {
auc:.4f}')
Sklearn
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import roc_auc_score
# 生成模拟数据的函数
def generate_data(n_samples=10000, n_features=10, random_state=None):
np.random.seed(random_state)
X = np.random.rand(n_samples, n_features)
y = (np.random.rand(n_samples) > 0.5).astype(int)
return pd.DataFrame(X, columns=[f'feature_{
i}' for i in range(n_features)]), y
# 逻辑回归底层实现
class LogisticRegression:
def __init__(self, learning_rate=0.01, epochs=10, batch_size=32):
self.learning_rate = learning_rate
self.epochs = epochs
self.batch_size = batch_size
def _sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def fit(self, X, y):
self.w = np.random.rand(X.shape[1] + 1)
X = np.c_[np.ones(X.shape[0]), X]
for epoch in range(self.epochs):
for i in range(0, len(X), self.batch_size):
X_batch = X[i:i + self.batch_size]
y_batch = y[i:i + self.batch_size]
y_pred = self._sigmoid(np.dot(X_batch, self.w))
gradient = np.dot(X_batch.T, y_pred - y_batch) / len(y_batch)
self.w -= self.learning_rate * gradient
def predict_proba(self, X):
X = np.c_[np.ones(X.shape[0]), X]
return self._sigmoid(np.dot(X, self.w))
# 生成模拟数据
X, y = generate_data(n_samples=10000, n_features=10, random_state=42)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练GBDT模型
gbdt = GradientBoostingClassifier(n_estimators=50, random_state=42)
gbdt.fit(X_train, y_train)
# 对训练数据进行GBDT特征变换
train_leaves = gbdt.apply(X_train)[:, :, 0]
test_leaves = gbdt.apply(X_test)[:, :, 0]
# 对GBDT生成的叶子节点特征进行One-Hot编码
encoder = OneHotEncoder()
encoder.fit(train_leaves)
train_leaves_encoded = encoder.transform(train_leaves).toarray()
test_leaves_encoded = encoder.transform(test_leaves).toarray()
# 训练自定义逻辑回归模型
lr = LogisticRegression(learning_rate=0.01, epochs=10, batch_size=32)
lr.fit(train_leaves_encoded, y_train)
# 对测试集进行预测并计算AUC
y_pred_proba = lr.predict_proba(test_leaves_encoded)
auc = roc_auc_score(y_test, y_pred_proba)
print(f'Test AUC: {
auc:.4f}')
Pyspark
import numpy as np
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import GBTRegressor
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# 数据生成函数
def generate_data(n_samples=10000, n_features=20, random_state=None):
if random_state:
np.random.seed(random_state)
X = np.random.rand(n_samples, n_features)
w = np.random.rand(n_features)
b = np.random.rand()
y = np.dot(X, w) + b
y = 1 / (1 + np.exp(-y))
y = np.round(y)
return X, y
# 生成数据
n_samples = 10000
n_features = 20
X, y = generate_data(n_samples=n_samples, n_features=n_features, random_state=42)
# 创建Spark会话
spark = SparkSession.builder.appName("GBDT_LR_Example").getOrCreate()
# 将数据转换为Spark DataFrame
data = np.column_stack((X, y))
data = spark.createDataFrame(data.tolist(), ["feature_{}".format(i) for i in range(n_features)] + ["label"])
# 划分训练集和测试集
train_data, test_data = data.randomSplit([0.8, 0.2], seed=42)
# 训练GBDT模型
assembler = VectorAssembler(inputCols=["feature_{}".format(i) for i in range(n_features)], outputCol="features")
gbt = GBTRegressor(labelCol="label", featuresCol="features", maxIter=50, stepSize=0.1)
# 构建GBDT模型流水线
gbt_pipeline = Pipeline(stages=[assembler, gbt])
gbt_model = gbt_pipeline.fit(train_data)
# 转换训练和测试数据
train_data_transformed = gbt_model.transform(train_data).select(col("prediction").alias("gbt_prediction"), col("label"))
test_data_transformed = gbt_model.transform(test_data).select(col("prediction").alias("gbt_prediction"), col("label"))
# 训练LR模型
lr_assembler = VectorAssembler(inputCols=["gbt_prediction"], outputCol="features")
lr = LogisticRegression(labelCol="label", featuresCol="features", maxIter=10)
# 构建LR模型流水线
lr_pipeline = Pipeline(stages=[lr_assembler
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









