




 XGBoost是梯度提升(GBDT)的优化实现,通过二阶泰勒展开引入模型复杂度,防止过拟合。它使用贪心算法构建树结构,通过计算增益选择最佳分割点。正则化项包含叶子节点数量和权重平方和,以平衡模型准确性和泛化能力。此外,XGBoost采用列抽样、稀疏值处理和多线程优化计算效率。
XGBoost是梯度提升(GBDT)的优化实现,通过二阶泰勒展开引入模型复杂度,防止过拟合。它使用贪心算法构建树结构,通过计算增益选择最佳分割点。正则化项包含叶子节点数量和权重平方和,以平衡模型准确性和泛化能力。此外,XGBoost采用列抽样、稀疏值处理和多线程优化计算效率。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
xgboost原理
XGBoost是对GBDT进一步改进
传统GBDT在优化时只用到一阶导数信息,XGBoost则对损失函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。
XGBoost在损失函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性。
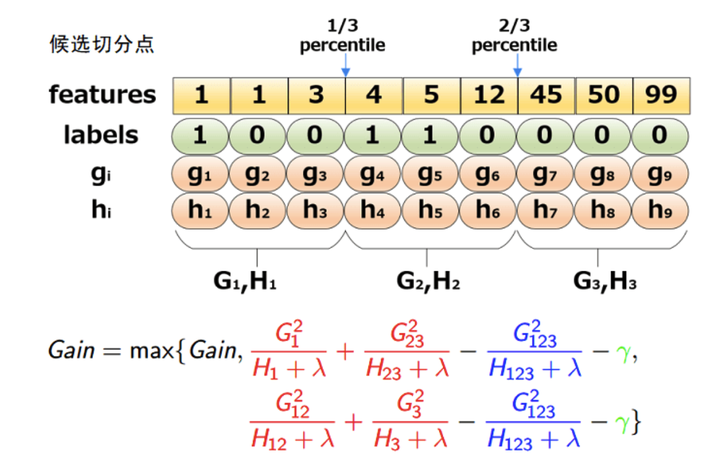
简单分位数算法
编辑切换为居中
添加图片注释,不超过 140 字(可选)
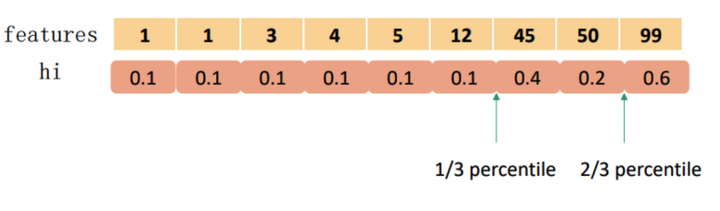
weighted quantile sketch,XGBoost提出以二阶梯度h为权重的分位数算法
编辑切换为居中
添加图片注释,不超过 140 字(可选)
XGBoost使用近似算法来寻找树的切分点,这使得它在计算时更加高效。
在精确贪心算法中,为了找到最佳切分点,需要遍历所有特征的所有可能切分点。相比之下,XGBoost使用近似算法,只需要考虑每个特征的分位点作为候选切分点。这样,就无需将全部数据放入内存,从而降低了计算复杂度。
关于候选切分点的选取,有两种策略:
全局(Global):在学习每棵树之前,提出候选切分点。这意味着对于整个树的构建过程,切分点的候选集保持不变。
局部(Local):每次分裂前,重新提出候选切分点。这意味着在树的每次分裂过程中,都会重新计算当前节点的候选切分点。
通过这些策略,XGBoost可以在保持较高准确度的同时,显著降低计算复杂度。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
Shrinkage(缩减):在XGBoost中,每次迭代完成后,会将叶子节点的权重乘以一个学习率(learning rate)。这种做法可以削弱每棵树的影响,为后续迭代留出更大的学习空间。缩减有助于降低模型的过拟合风险,提高模型的泛化能力。
列抽样(column subsampling):XGBoost从随机森林算法中借鉴了列抽样的方法。在训练过程中,XGBoost会对特征进行随机抽样,选择部分特征来构建每棵树。这样做不仅可以降低过拟合风险,提高模型的泛化能力,还可以减少计算量。这使得XGBoost在处理大规模数据集时具有优势。
稀疏值处理(sparsity-aware split finding):XGBoost能够自动处理缺失值。在寻找最佳切分点时,算法会自动学习缺失值的分裂方向(即分配到左子树或右子树)。这样,即使数据中存在缺失值,XGBoost仍能有效地进行训练,提高模型的鲁棒性。
XGBoost在选取最佳切分点时可以开启多线程进行

编辑切换为居中
添加图片注释,不超过 140 字(可选)
分块并行:在决策树的构建过程中,寻找最优切分点是最耗时的部分,而数据排序是其中的关键操作。为了减少排序时间,XGBoost引入了Block结构来存储数据。
数据按列存储:在Block结构中,数据是按列存储的。这使得XGBoost可以针对每个特征进行多线程并行计算,从而提高计算效率。
Block按列压缩:XGBoost对Block中的数据进行按列压缩,从而降低存储空间需求和计算开销。
Block Sharding:为了进一步提高计算性能,XGBoost支持将数据划分到不同硬盘上(Block Sharding)。这样,多个硬盘可以并行读取数据,提高磁盘吞吐率,从而缩短计算时间。
通过分块并行、数据按列存储、Block按列压缩和Block Sharding等技术,XGBoost能够有效地降低数据排序的时间,从而提高决策树构建过程中寻找最优切分点的效率。这些技术使得XGBoost在处理大规模数据集时具有显著的性能优势。
XGBoost(eXtreme Gradient Boosting)是一种梯度提升(Gradient Boosting)算法的优化实现。在XGBoost中,目标函数(Obj)包括两部分:模型的损失函数(L)和模型的复杂度(Ω)。损失函数衡量模型预测结果与真实标签之间的误差,而模型复杂度则衡量模型的复杂性。XGBoost的目标是找到一组树,使得目标函数最小化,从而在保证模型准确度的同时,提高模型的泛化能力,防止过拟合。
目标函数表示如下:
Obj(Θ) = L(Θ) + Ω(Θ)
其中,Θ 表示模型参数,L(Θ) 表示损失函数,Ω(Θ) 表示模型复杂度。对于回归问题,损失函数通常为平方损失函数:
L(Θ) = Σ(yi - ŷi)^2
其中,n 为样本数量,yi 表示样本的真实标签,ŷi 表示模型输出。
在XGBoost中,模型是由K棵树组成的,每棵树都是一个样本到叶子节点值的映射关系。模型复杂度的计算与树的个数(K)和每棵树的叶子节点数量有关,表示如下:
Ω(Θ) = γK + 0.5λΣ||fk||^2
其中,γ 和 λ 是正则化参数,用于控制模型复杂度,fk 表示第k棵树。
为了最小化目标函数,XGBoost采用了梯度提升(Gradient Boosting)方法。在每一轮训练中,模型计算损失函数关于当前模型输出的梯度和二阶导数,然后使用这些信息来构建一棵新的树,以减小损失函数。通过迭代这个过程,XGBoost能够逐步优化目标函数,提高模型性能。
XGBoost使用二阶泰勒展开式来近似损失函数,从而简化了优化问题。下面我们详细描述这一推导过程。
给定一个损失函数L(y, ŷ),其中y是真实标签,ŷ是模型预测值。对于一个加法模型(即模型预测值是由多棵树相加得到的),在第t轮迭代时,模型的预测值表示为:
ŷi^t = ŷi^(t-1) + f_t(xi)
其中,ŷi^t表示第t轮迭代后的预测值,ŷi^(t-1)表示第t-1轮迭代后的预测值,xi是样本特征,f_t(xi)是第t轮迭代生成的新树的预测值。
目标是在第t轮迭代时找到一个新的树f_t(xi),使得损失函数L(yi, ŷi^t)最小化。我们可以通过泰勒展开式来近似损失函数:
L(yi, ŷi^t) ≈ L(yi, ŷi^(t-1)) + g_if_t(xi) + 0.5 * h_if_t^2(xi) + C
其中,gi和hi分别为损失函数的一阶和二阶导数:
gi = ∂L(yi, ŷi^(t-1)) / ∂ŷi^(t-1)
hi = ∂^2L(yi, ŷi^(t-1)) / ∂(ŷi^(t-1))^2
C 是一个与f_t(xi)无关的常数项。
现在,我们需要在每轮迭代中找到一个新的树f_t(xi),使得近似损失函数最小化。为了引入模型复杂度,我们定义正则化目标函数:
Obj(f_t) = Σ[L(yi, ŷi^(t-1)) + g_if_t(xi) + 0.5 * h_if_t^2(xi)] + Ω(f_t)
其中,Ω(f_t)表示模型复杂度。在XGBoost中,模型复杂度定义为:
Ω(f_t) = γT + 0.5 * λ * Σw_j^2
T 是树f_t中叶子节点的数量,w_j是第j个叶子节点的权重,γ和λ是正则化参数。
为了最小化Obj(f_t),我们可以找到一个固定结构的树,将样本分配到不同的叶子节点,并计算每个叶子节点的最优权重。假设一个叶子节点包含I_j个样本,那么该叶子节点的最优权重w_j*可以通过求导Obj(f_t)关于w_j并令其为零来计算:
w_j* = - Σ_{i∈I_j} gi / (Σ_{i∈I_j} hi + λ)
将最优权重 w_j* 带回到 Obj(f_t),我们可以得到一个关于树结构的优化目标:
Obj'(f_t) = Σ[L(yi, ŷi^(t-1)) + g_if_t(xi) + 0.5 * h_if_t^2(xi)] + Ω'(f_t)
将 w_j* 代入 Ω(f_t),并忽略与树结构无关的项,我们得到:
Ω'(f_t) = γT + 0.5 * λ * Σ(- Σ_{i∈I_j} gi / (Σ_{i∈I_j} hi + λ))^2
为了最小化 Obj'(f_t),我们需要在每轮迭代中找到一个最优的树结构。在XGBoost中,这通过贪心算法来实现,每次尝试分割一个叶子节点,选择一个使得损失函数下降最大的特征进行分割。
给定一个叶子节点,我们可以计算分割该叶子节点前后损失函数的变化:
Gain = 0.5 * [Σ_{i∈I_L} g_i^2 / (Σ_{i∈I_L} h_i + λ) + Σ_{i∈I_R} g_i^2 / (Σ_{i∈I_R} h_i + λ) - Σ_{i∈I} g_i^2 / (Σ_{i∈I} h_i + λ)] - γ
其中,I_L 和 I_R 分别表示分割后左右子节点的样本集合,I 表示分割前的叶子节点的样本集合。我们可以遍历所有特征和分割点,找到一个使得 Gain 最大的特征和分割点进行分割。
通过迭代地添加树结构,XGBoost 可以逐步优化目标函数 Obj'(f_t),从而在保持模型准确性的同时,提高模型的泛化能力,防止过拟合。
总结一下,XGBoost 使用二阶泰勒展开式来近似损失函数,并引入了模型复杂度来防止过拟合。在每轮迭代中,XGBoost 通过贪心算法找到一个最优的树结构,使得损失函数下降最大。通过迭代这个过程,XGBoost 能够逐步优化目标函数,提高模型性能。
追加训练(Additive Training)或者梯度提升(Boosting)是XGBoost的核心思想,其目的是通过迭代地优化目标函数,逐步提高模型性能。下面简要介绍一下XGBoost中的追加训练方法。
追加训练(Boosting)的基本思想是在每轮迭代中学习一个新的基学习器(如决策树),并将其添加到当前模型中,从而修正模型的预测结果。具体来说,在第t轮迭代时,我们要学习一个新的基学习器f_t,使得损失函数L(y, ŷ)在当前模型的基础上进一步减小,其中y是真实标签,ŷ是模型预测值。
在XGBoost中,损失函数是通过二阶泰勒展开式近似的,从而简化了优化问题。在每轮迭代中,我们需要找到一个新的树f_t,使得近似损失函数最小化。为了防止过拟合,XGBoost还引入了模型复杂度来惩罚过于复杂的模型。因此,在每轮迭代中,我们需要在保持模型准确性的同时,提高模型的泛化能力。
追加训练的步骤如下:
初始化模型:在第0轮迭代时,初始化一个常数预测值,使得损失函数最小化。
对于每轮迭代 t = 1, 2, ..., T(T为迭代轮数): a. 计算损失函数关于当前模型预测值的一阶梯度(gi)和二阶梯度(hi)。 b. 根据梯度信息构建一棵新的树f_t,使得近似损失函数最小化。 c. 将新树f_t添加到当前模型中,更新模型预测值。
输出最终模型,得到预测结果。
在XGBoost中,新树的构建采用贪心算法,每次尝试分割一个叶子节点,选择一个使得损失函数下降最大的特征进行分割。这一过程可以通过计算不同特征和分割点的增益(Gain)来实现。
通过迭代地添加树结构,XGBoost可以逐步优化目标函数,提高模型性能。追加训练(Boosting)方法使XGBoost具有较强的拟合能力,同时通过引入模型复杂度,XGBoost能够有效地防止过拟合,从而在保证模型准确性的同时,提高模型的泛化能力。
总结一下,XGBoost中的追加训练(Boosting)是通过以下方法实现的:
使用二阶泰勒展开式近似损失函数,简化优化问题。
在每轮迭代中,找到一个新的树结构以使近似损失函数最小化。
引入模型复杂度作为正则化项,以防止过拟合。
采用贪心算法构建新树,以使损失函数的下降最大。
通过这种追加训练方法,XGBoost能够在训练过程中逐步改进模型的性能。与其他机器学习算法相比,XGBoost具有较高的准确性和泛化能力,使其在各种应用场景中表现出色。
XGBoost的核心思想是在每轮迭代中通过梯度提升来优化损失函数。为了防止过拟合,XGBoost引入了模型复杂度函数Ω作为正则化项。模型复杂度函数Ω能够惩罚过于复杂的模型,帮助找到一个既具有良好准确性又具有较好泛化能力的模型。
模型复杂度函数Ω的定义如下:
Ω(f_t) = γT + 0.5 * λ * Σw_j^2
其中,f_t表示第t轮迭代生成的树,T表示树中叶子节点的数量,w_j是第j个叶子节点的权重,γ和λ是正则化参数。这个函数包含两部分:
γT:这一项与叶子节点数量成正比。增加叶子节点数量会使模型更复杂,因此这一项可以防止树过深,限制模型的复杂度。
0.5 * λ * Σw_j^2:这一项与叶子节点权重的平方和成正比。较大的权重可能导致过拟合,这一项通过惩罚较大的权重来限制模型复杂度。
在每轮迭代中,XGBoost的目标是最小化以下目标函数:
Obj(f_t) = Σ[L(yi, ŷi^(t-1)) + g_if_t(xi) + 0.5 * h_if_t^2(xi)] + Ω(f_t)
其中,L(yi, ŷi^(t-1))是损失函数,g_i和h_i分别表示损失函数的一阶和二阶导数,Ω(f_t)是模型复杂度函数。这个目标函数包含了损失函数的近似值和模型复杂度,使得XGBoost在优化损失函数的同时,也能控制模型的复杂度。
通过引入模型复杂度函数Ω,XGBoost能够有效地平衡模型的准确性和泛化能力。这使得XGBoost在许多实际应用中具有优越的性能,成为当前最受欢迎的梯度提升树算法。
XGBoost 的目标函数 Obj(f) 定义为:
Obj(f) = ΣL(yi, ŷi) + Ω(f)
其中,L(yi, ŷi) 是损失函数,表示真实值 yi 和预测值 ŷi 之间的误差,Ω(f) 是模型复杂度函数,用于正则化模型。
对于树模型,我们可以将 Ω(f) 表示为:
Ω(f) = γT + 0.5 * λ * Σw_j^2
这里,T 是树的叶子节点数,w_j 是第 j 个叶子节点的权重,γ 和 λ 是正则化参数。接下来,我们分析这个函数的推导过程。
γT:这一项与树的叶子节点数 T 成正比。模型中叶子节点越多,模型越复杂,容易出现过拟合。因此,通过引入与叶子节点数成正比的项,可以限制模型的复杂度,防止树过深。
0.5 * λ * Σw_j^2:这一项与各个叶子节点权重的平方和成正比。较大的权重可能导致过拟合,通过惩罚较大的权重来限制模型复杂度。引入权重平方和的目的是使得权重分布更平均,防止某些叶子节点的权重过大导致模型过拟合。
将这两部分结合,我们得到模型复杂度函数 Ω(f):
Ω(f) = γT + 0.5 * λ * Σw_j^2
此复杂度函数包含两个惩罚项:一个与叶子节点数量有关,另一个与叶子节点权重有关。这种设计使得 XGBoost 在优化损失函数的同时,能够控制模型的复杂度,从而有效地防止过拟合。
XGBoost 在每轮迭代中通过构建一棵新的树来优化目标函数。为了找到最优的树结构,XGBoost 采用贪心算法在每一步尝试分割一个叶子节点,选择使得目标函数下降最大的特征进行分割。下面简要介绍 XGBoost 中贪心法求解树的过程。
在每轮迭代中,我们需要找到一个新的树结构以使近似损失函数最小化。具体来说,我们要找到一个最优的特征和分割点进行分割,使得目标函数 Obj'(f_t) 最小。为了衡量分割的好坏,我们计算分割后目标函数的变化(增益,Gain):
Gain = 0.5 * [Σ_{i∈I_L} g_i^2 / (Σ_{i∈I_L} h_i + λ) + Σ_{i∈I_R} g_i^2 / (Σ_{i∈I_R} h_i + λ) - Σ_{i∈I} g_i^2 / (Σ_{i∈I} h_i + λ)] - γ
其中,I_L 和 I_R 分别表示分割后左右子节点的样本集合,I 表示分割前的叶子节点的样本集合,g_i 和 h_i 分别是损失函数的一阶梯度和二阶梯度,λ 和 γ 是正则化参数。
在贪心算法中,我们遍历所有可能的特征和分割点,找到一个使得增益 Gain 最大的特征和分割点进行分割。具体步骤如下:
初始化树结构,只包含一个叶子节点。
对于每个叶子节点: a. 遍历所有可能的特征和分割点,计算增益 Gain。 b. 选择一个使得增益 Gain 最大的特征和分割点进行分割。 c. 如果增益 Gain 大于某个阈值,将当前叶子节点分割成两个子节点;否则,保持当前叶子节点不变。
重复步骤 2,直到满足停止条件(例如,达到预设的最大树深度或最小叶子节点权重和)。
通过贪心算法构建树结构,XGBoost 可以在每轮迭代中找到一个使目标函数下降最大的树结构,从而逐步优化目标函数。这种方法具有较高的计算效率,能够在有限时间内找到一个近似最优的树结构。然而,由于贪心算法局部最优的特性,它可能无法找到全局最优的树结构。
尽管如此,XGBoost 在实践中表现出了很好的性能,主要原因有以下几点:
局部最优解通常足够接近全局最优解:虽然贪心算法可能无法找到全局最优的树结构,但在很多情况下,局部最优解已经足够接近全局最优解。这意味着贪心算法在提高计算效率的同时,并没有显著牺牲模型的性能。
增量学习和模型集成:XGBoost 使用增量学习方法(Boosting)逐步构建模型,每轮迭代中都会添加一棵新的树。通过将多棵树的预测结果组合起来,可以弥补单棵树的不足,提高模型的准确性和泛化能力。
正则化:XGBoost 引入了模型复杂度函数作为正则化项,以防止过拟合。这使得 XGBoost 在优化损失函数的同时,也能控制模型的复杂度。正则化有助于提高模型的泛化能力,使其在实际应用中表现更好。
总之,虽然 XGBoost 使用的贪心算法可能无法找到全局最优的树结构,但由于增量学习、模型集成和正则化等因素的影响,在实际应用中,XGBoost 仍然能够取得非常好的性能。这使得 XGBoost 成为许多机器学习任务中最受欢迎的梯度提升树算法之一。
《唯品金融机器学习实践》中也提到因为GBDT+LR良好的表达能力和可解释性成为他们的最重要模型之一。
饿了么的Rank系统中,GBDT+FTRL,也是AUC最高的模型(不是之一,超过深度学习尝试)。
GBDT+LR(梯度提升决策树+逻辑回归)和 GBDT+FTRL(梯度提升决策树+Follow The Regularized Leader)是广告点击率(CTR)预估中的两种组合模型。这些模型结合了树模型的非线性表达能力和线性模型的简单性,从而提高了预测性能。虽然 XGBoost 在很多任务中的表现优于 GBDT,但在实际应用中,我们很少看到 XGBoost+LR 这样的模型组合。这主要有以下原因:
复杂度:相较于 GBDT,XGBoost 本身引入了更多的正则化项和优化技巧,使得模型更加复杂。因此,XGBoost 单独使用时通常就能取得很好的性能,不需要与其他模型进行组合。
重复的正则化:XGBoost 已经内置了正则化策略来防止过拟合,而 LR 或 FTRL 中通常也会使用正则化项。如果将 XGBoost 与 LR 或 FTRL 结合,可能会导致正则化效果叠加,从而影响模型的表达能力。
计算资源和时间:在许多实际场景中,计算资源和时间是有限的。构建 XGBoost+LR 模型需要同时训练两个模型,这会增加计算成本。而在很多情况下,单独使用 XGBoost 就能达到足够好的性能。
模型组合(例如,模型融合、模型堆叠)是一种通用的策略,可以提高模型的准确性和鲁棒性。在实际应用中,需要权衡模型的性能、计算成本和复杂度,来决定是否使用模型组合。
分类
import xgboost as xgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









