




 本文介绍了一种名为MobileBert的新模型,它是Bert模型的轻量化版本,通过加入bottleneck机制减少参数量,同时保持深度,实现模型压缩和加速。文章详细解释了bottleneckstructures的作用,以及如何通过teacher-student机制进行有效训练。
本文介绍了一种名为MobileBert的新模型,它是Bert模型的轻量化版本,通过加入bottleneck机制减少参数量,同时保持深度,实现模型压缩和加速。文章详细解释了bottleneckstructures的作用,以及如何通过teacher-student机制进行有效训练。
前言
- 论文地址:https://arxiv.org/abs/2004.02984
- 代码地址:https://github.com/google-research/google-research/tree/master/mobilebert
Abstract
提出 MobileBert 来压缩和加速 Bert 模型。
1、Introduction
MobileBERT 采用的和 BERT-large 一样深的层数,在每一层中的 transformer 中加入了 bottleneck 机制使得每一层 transformer 变得更窄。那么 bottleneck structures 是个什么东西呢?看下面这个图:
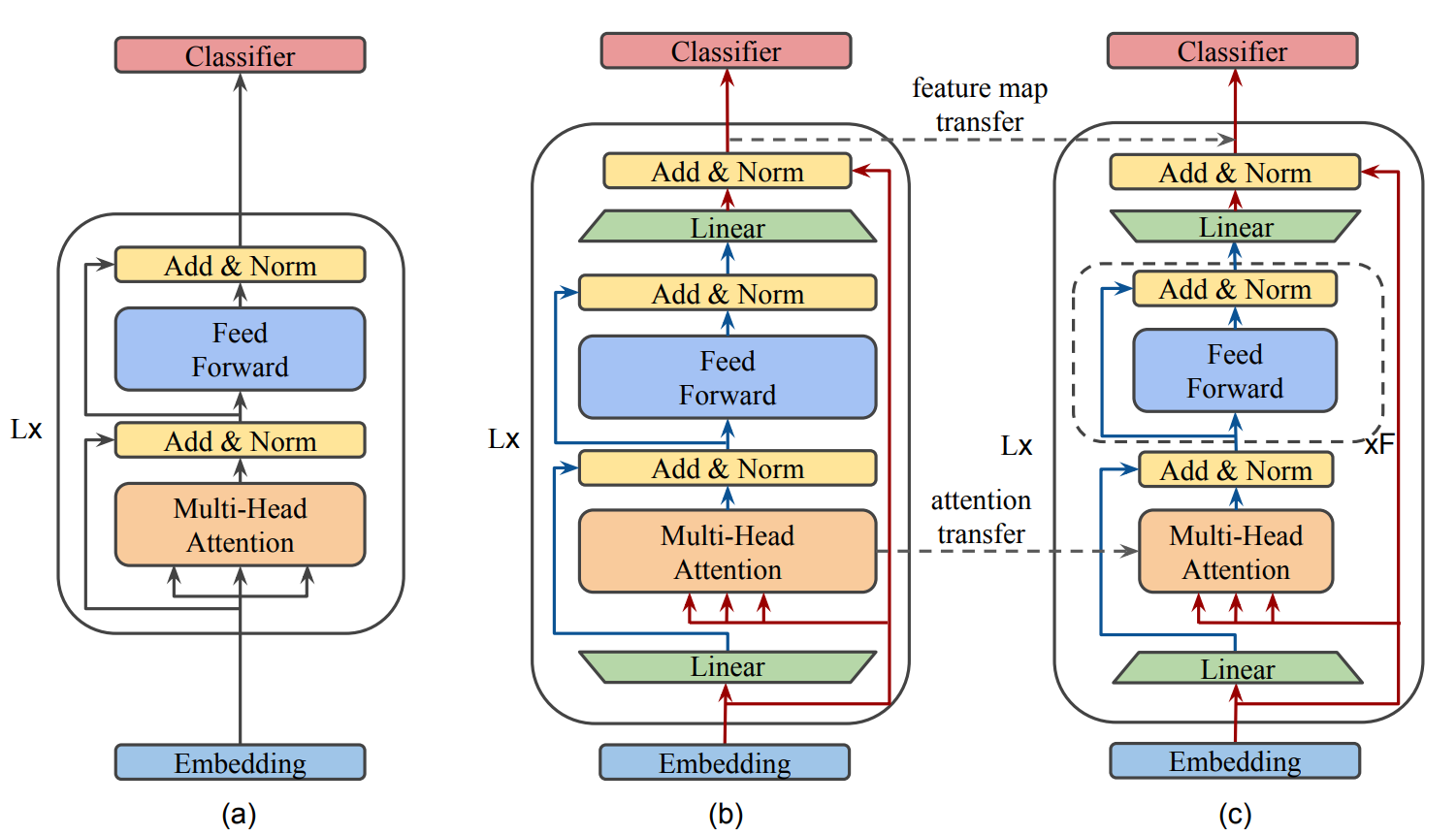
其中 a 是bert,从图中可以看出,多了两个全连接层,就是图中的矩形,这个就是作者说的bottleneck structures。它的主要作用是调整输入输出维度。
2、Related Work
过。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









